一种轻量顶点染色线程生成分发的方法及装置与流程
本发明涉及的是图形芯片技术领域,具体涉及一种轻量顶点染色线程生成分发的方法及装置。
背景技术
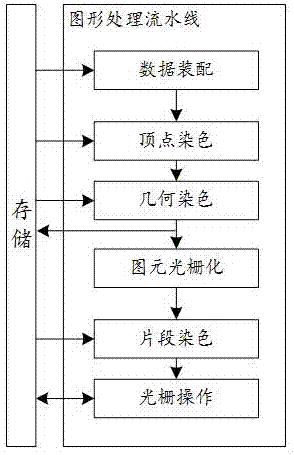
电子设备在现代人类生活中已经成为了必须品,为了增进人和计算机交互的友好性与真实感,各种人机交互的技术得到快速的发展如虚拟现实(virtualreality,vr),增强现实(augmentedreality,ar)等。这些技术的发展同计算机图形应用是密不可分,而计算机图形应用的基础就是图形api和图形处理器。图形api(例如opengl,directx3d)定义了图形处理的流水线(图1所示),图形处理器则是对图形处理流水线一种硬件实现,执行各种流水线中各项功能。
图形处理器中能够执行多种染色程序(顶点染色,几何染色,像素染色等),并且通过大量的数据并行提供高效的计算能力。但是一旦染色程序中的依赖关系出现长延时(例如存储和纹理等操作),会导致计算的阻塞引起性能的下降。此时,图形处理器会通过切换其他非阻塞的染色线程来隐藏这些长延时操作,以线程的高吞吐量来提高图形处理器的性能。
图形处理器中传统的染色线程的生成是由顶点线程分发器(vertexdispatcher,vdpr)处理。vdpr先考虑处理器中的各种剩余资源,当剩余资源能够满足线程的所需的所有资源时,才会生成新的线程分配线程id。生成的线程经由vdpr分发到计算簇中的计算单元执行(见图2,图3)。这样的线程生成分发方法会存在由长时延的资源准备导致的线程生成滞后的缺点。线程生成的滞后导致线程数量相对不足,一定程度时会引起线程切换的阻塞,从而导致图形处理器的性能的下降。所以图形处理器中需要一种更加的高效染色线程生成的方法。
综上所述,本发明设计了一种轻量顶点染色线程生成分发的方法及装置。
技术实现要素:
针对现有技术上存在的不足,本发明目的是在于提供一种轻量顶点染色线程生成分发的方法及装置,能够减少生成顶点染色线程的时间开销,避免线程创建滞后。
为了实现上述目的,本发明是通过如下的技术方案来实现:一种轻量顶点染色线程生成分发的方法,包括以下步骤:
1、接收来自fep(frontendprocessor,前端处理器)的两类画图命令drawelements和drawarrays;
2、根据命令中的参数执行逻辑顶点划分,配置除线程id外的参数,批量创建无线程id的伪线程;
3、等待线程的id分配,形成可调度线程;
4、根据所有gcu的状态和fep配置的分发策略将新生成的顶点染色线程分发给对应的gcu。
所述的步骤2的划分步骤具体如下:根据命令参数first,count和fep配置的顶点染色线程所含顶点的数目vtx_cnts_per_vtx_thread,将count划分成若干个伪线程并向线程id池中申请线程id,在得到分配的线程id后,将线程的id、图元类型和线程实际的顶点数目信息发送给图元装配单元(pa)。图元装配单元根据这些信息来对染色后的顶点进行装配。
所述的步骤3的线程分发具体步骤如下:顶点染色线程创建后,线程分发调度根据线程id来分配gca(graphicscomputearray,计算单元阵列),此时gca可以主动根据线程id来读取外部数据;当染色线程启动所需的资源准备完成时,计算单元就可以开始执行染色线程的执行程序;若染色线程程序执行时出现资源阻塞的情况,计算单元会切换其他没有阻塞的染色线程执行,直到该线程资源阻塞解除时计算单元再次将该线程切换回来执行;若染色线程执行中间没有出现阻塞,直到染色线程执行完毕,计算单元释放该顶点染色线程id给线程id池。
一种轻量顶点染色线程生成分发装置,包括轻量线程生成分发处理器、计算簇、图元装配单元、交叉互联单元和图形存储单元,轻量线程生成分发处理器通过多个计算簇、图元装配单元与交叉互联单元相连,交叉互联单元和图形存储单元相连,所述的计算簇包括多个计算单元,计算单元通过线程id来管理线程所需的各项资源。
本发明具有以下有益效果:
本发明提出了伪线程和可调度线程。首先,伪线程的创建开销小且无阻塞。可调度线程仅依赖线程id不考虑其他资源,而线程id不是gpu性能瓶颈。所以,线程创建开销小且效率高。可见,轻量级线程可以让资源依赖逐步分解到最接近阻塞的逻辑单元,而不是统一的集中在线程的创建时。这样一来当出现资源阻塞时,线程执行的延迟时间会大大的降低。而图形处理器中资源阻塞是一件高概率的事件,所以轻量级线程生成,近阻塞资源式的线程调度方式可以很好地提高图形处理器的染色线程的吞吐能力。
附图说明
下面结合附图和具体实施方式来详细说明本发明;
图1为本发明的背景技术中图形处理的流水线图;
图2为本发明的背景技术中图形处理器的结构图;
图3为本发明的背景技术中线程创建流程图;
图4为本发明的装置结构示意图;
图5为本发明的计算簇的结构框图;
图6为本发明的方法流程图;
图7为本发明的线程分配流程图;
图8为本发明的线程分发流程图;
图9为本发明的接收线程流程图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
参照图4-图9,本具体实施方式采用以下技术方案:一种轻量顶点染色线程生成分发的方法,包括以下步骤:
1、接收来自fep(frontendprocessor,前端处理器)的两类画图命令drawelements和drawarrays;
2、根据命令中的参数执行逻辑顶点划分,配置除线程id外的参数,批量创建无线程id的伪线程;
3、等待线程的id分配,形成可调度线程;
4、根据所有gcu的状态和fep配置的分发策略将新生成的顶点染色线程分发给对应的gcu。
为了统一顶点染色线程的创建,本具体实施方式采用了序列化的逻辑顶点索引。根据命令参数first,count和fep配置的顶点染色线程所含顶点的数目vtx_cnts_per_vtx_thread,将count划分成若干个伪线程并向线程id池中申请线程id,如图7所示。在得到分配的线程id后,将线程的id、图元类型和线程实际的顶点数目信息发送给图元装配单元(pa)。图元装配单元根据这些信息来对染色后的顶点进行装配。
由于线程生成考虑的资源只有线程id,这样一来极大的减少了线程生成时资源监测的范围和形式。顶点染色线程创建后,线程需要的所有资源都是基于线程id管理。一旦线程创建完成,线程分发调度根据线程id来分配gca(graphicscomputearray,计算单元阵列),此时gca可以主动根据线程id来读取外部数据。当染色线程启动所需的资源准备完成时,计算单元就可以开始执行染色线程的执行程序。如果染色线程程序执行时出现资源阻塞的情况,计算单元会切换其他没有阻塞的染色线程执行,直到该线程资源阻塞解除时计算单元再次将该线程切换回来执行。如果染色线程执行中间没有出现阻塞,直到染色线程执行完毕,计算单元释放该顶点染色线程id给线程id池,如图8所示。
本具体实施方式将线程资源的请求操作从vtcd(vertexthreadconstructoranddispatcher,线程创建分发单元)分发迁移到了gca中,引入的代价就是gca中需要实现根据线程id请求资源,监管资源是否就绪。而这种管理机制恰恰之前的vdpr中是存在的,稍加修改就可复用,可见代价是非常小的。
本具体实施方式所有图元draw命令统一到基于索引的画图命令,包含两类drawarrays和drawelements。若是应用程序中含有其他draw命令则由软件库将其转换为上述两类命令。逻辑顶点的序列化,统一后的两类画图命令的索引都是从0开始往上递增。两类画图命令按照vtx_cnts_per_vtx_thread来划分逻辑顶点索引,生成伪线程。请求线程id,当获取到线程的id后,将该可调度线程按照fep配置的分发策略分发给空闲的计算单元(graphicscomputeunit,gcu)。将线程创建与线程id获取明显分离,创建完毕但未获得的线程id的线程视为伪线程,获得线程id后的伪线程是可调度线程。在接受到新线程执行请求后,gcu先进行逻辑顶点索引到实际索引的映射,而后主动读取该线程所需的属性资源。当属性资源和其他所需资源准备完毕时,gcu开始按照单指令多线程(singleinstructionmultithread,simt)的方式执行该线程。
基于伪线程和调度线程的其他形式的调度与分发。例如基于伪线程调度与分发,将伪线程同可调度线程的关联延迟,只是在资源回收时和线程重排序等必要时间点进行伪线程与调度线程id的关联映射,然后基于可调度线程id进行各项操作。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!