一种中文通告文档问题答案对自动生成方法与流程
本发明属于数据处理领域,特别涉及一种中文通告文档问题答案对自动生成方法。
背景技术
近年来,随着互联网、机器学习、自然语言处理的飞速发展和网上大规模知识库以及海量网络信息的出现,自动问答系统取得了长足的发展,逐步开始被各产业界认可和应用。例如面向常用问题集(frequentaskedquestions,faq)的问答系统,它通过将用户提出的问题和知识库中的问题答案对进行匹配检索直接得到候选答案,问题答案对的知识库是问答系统的一个重要组成部分。自动生成问题答案对知识库是自动问答系统、对话系统、自然语言处理、人工智能、认知科学、教育学等众多领域中一个重要且极具挑战性的前沿课题,同时问题的自动生成具有可观的发展前景。
另外,由中文通告文档自动生成问题答案对的知识库具有重要研究意义。现在越来越多的领域和机构有了自己的中文官网和主页,他们在上面发布各种通告,通告中蕴含了大量的信息,用户提出的问题的答案很多都可以在其中找到答案。如果对这些信息通过人工构造问题答案对知识库或者进行人工交互的问答,将会消耗大量的人力资源和时间。而通过由通告文档自动生成问题答案对知识库,然后自动问答系统对用户提出的问题在知识库中检索返回匹配的问题答案,可以大大减少人力资源开销,从而迅速提高工作效率。
现有技术中的问题生成方法,在涵盖众多领域的问题生成时,需要耗费大量人力资源和时间继续拧索引,而且如果出现新的领域和概念还需要维护和更新这个索引表,缺乏一定的健壮性。当该技术应用于特定领域时,如果该领域缺乏该领域的语义词典和语义分析工具时,将会影响问题生成的质量,此外最后获取的问题表达式对应的问题答案没有评估其质量如何,因此缺乏一定的鲁棒性。
技术实现要素:
为了解决现有技术中的问题,本发明提出了一种中文通告文档问题答案对自动生成方法,通过由中文通告文档生成出相应的问题答案对,问答系统就可以对用户提出的问题返回相应的答案,采用自然语言处理与深度学习相结合的算法,保证了生成出来的问题答案的通顺性和与原通告文档的相关性。
一种中文通告文档问题答案对自动生成方法,应用于中文通告文档问题答案对自动生成系统,所述方法包括以下步骤:
步骤1,获取问题答案对,生成规则集、模板库、打分模型及自动生成模型;
步骤2,获取中文通告文档,对所述中文通告文档进行预处理,提取关联语句;
步骤3,根据所述规则集中的规则对所述关联语句进行规则匹配,当所述关联语句与一规则匹配时,根据该规则的生成问题表达式生成所述关联语句的问题,保存生成的问题和语句至问题答案对库;
步骤4,当所述关联语句没有匹配到任何一个规则时,对该语句进行关键词提取,根据所述模板库中的模板对提取的关键词进行匹配,当所述关键词匹配到对应模板,根据该模板生成问题;
步骤5,根据所述打分模型对所述步骤4中生成的问题进行打分,当得分超过预设阈值时将该问题与关联语句保存至所述问题答案对库和打分模型训练集中,将生成该问题的模板保存至所述模板库中;
步骤6,将未匹配到模板的语句或所述模板生成的问题在所述打分模型中得分不超过预设阈值的语句输入至所述自动生成模型中生成问题,将所述自动生成模型生成的问题应用所述打分模型进行打分,将得分超过所述预设阈值的生成问题和语句保存至所述问题答案对库;
步骤7,将生成了问题的模板扩展至所述模板库,基于扩展后的所述打分模型训练集训练所述打分模型,基于扩展后的问题答案对库训练所述自动生成模型。
进一步地,所述步骤3包括以下流程:
步骤31,判断规则集中是否有规则与关联语句匹配;
步骤32,当所述关联语句与一规则匹配时,根据该规则的生成问题表达式生成所述关联语句的问题,保存生成的问题和语句至问题答案对库;
步骤33,当所述关联语句没有匹配到任何一个规则时,流程进入步骤4。
进一步地,所述步骤4包括以下流程:
步骤41,当所述关联语句没有匹配到任何一个规则时,对该语句进行关键词提取,判断模板库中是否有模板与提取的关键词匹配;
步骤42,当所述关键词匹配到对应模板,根据该模板生成的问题,流程进入步骤5;
步骤43,当所述关键词没有匹配到任何一个模板时,流程进入步骤6。
进一步地,所述步骤5包括以下流程:
步骤51,应用所述打分模型对所述步骤4生成的问题进行打分,判断得分是否超过所述预设阈值;
步骤52,当得分超过所述预设阈值时,将该问题与关联语句保存至所述问题答案对库和打分模型训练集中,将生成该问题的模板保存至所述模板库中;
步骤53,当得分未超过所述预设阈值时,流程进入步骤6。
进一步地,所述中文通告文档问题答案对自动生成系统包括:
获取模块,用于获取问题答案对;
规则制定模块,用于定制规则集;
模板制定模块,用于定制问题的模板库;
预处理模块,用于对中文通告文档进行预处理,提取关联语句;
规则匹配模块,用于匹配语句符合的问题规则;
模板匹配模块,用于匹配语句符合的问题模板;
问题生成模块,用于将匹配到的规则、模板或自动生成问题模型生成与语句相关的问题;
打分模块,用于对生成的问题进行打分。
本发明的有益效果:本发明提供了一种中文通告文档问题答案对自动生成方法,通过由中文通告文档生成出相应的问题答案对,问答系统就可以对用户提出的问题返回相应的答案,采用自然语言处理与深度学习相结合的算法,保证了生成出来的问题答案的通顺性和与原通告文档的相关性,具有良好的扩展性和鲁棒性,在技术上具有超前性。
附图说明
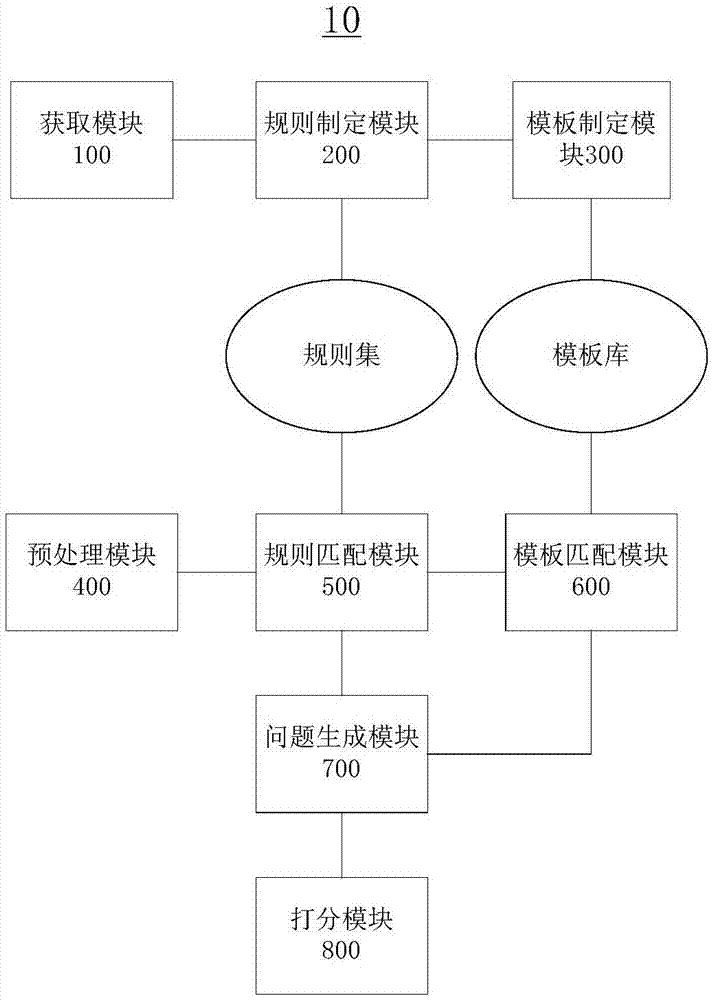
图1为本发明实施例中中文通告文档问题答案对自动生成系统结构示意图。
图2为本发明实施例的流程图。
图3为本发明实施例的打分模型结构示意图。
图4为本发明实施例的自动生成模型结构示意图。
图中:10-中文通告文档问题答案对自动生成系统;100-获取模块;200-规则制定模块;300-模板制定模块;400-预处理模块;500-规则匹配模块;600-模板匹配模块;700-问题生成模块;800-打分模块。
具体实施方式
下面结合附图对本发明的实施例做进一步的说明。
本发明提出的一种中文通告文档问题答案对自动生成方法,应用于中文通告文档问题答案对自动生成系统,系统结构如图1所示,包括:
获取模块100,用于获取问题答案对;
规则制定模块200,用于定制规则集;
模板制定模块300,用于定制问题的模板库;
预处理模块400,用于对中文通告文档进行预处理,提取关联语句;
规则匹配模块500,用于匹配语句符合的问题规则;
模板匹配模块600,用于匹配语句符合的问题模板;
问题生成模块700,用于将匹配到的规则、模板或自动生成问题模型生成与语句相关的问题;
打分模块800,用于对生成的问题进行打分。
请参阅图2,本发明提出的一种中文通告文档问题答案对自动生成方法,通过以下步骤实现:
步骤1,获取问题答案对,生成规则集、模板库、打分模型及自动生成模型。
本实施例中,获取模块100从各领域的问题答案对库中获取问题答案对,目的是利用这个语料库对该领域定制规则集、模板库、打分模型及自动生成模型,使生成的问题答案对符合这个领域的正常问答形式。
通过规则制定模块200制定规则集,利用中文通告文档的书写规范来制定一套规则(re1,re2,….ren)和规则下生成问题的表达式(ex1,ex2,…exn)。例如:中文通告文档的标题中通常要求给出本通告文档的中心内容如“关于如何申请出国留学”,通告下有时会要求给出“咨询电话:123456”,基于这个书写规范,用正则表达式表示这个书写规范rei:(【1】:【2】)其中【1】代表“咨询电话”【2】代表“123456”作为一条规则,然后对这条规则制定一个问题生成表达式exi:(t的【1】?),可以生成问题“关于如何申请出国留学的咨询电话?”。
通过模板制定模块300制定模板库,首先获取一个停用词表,停用词表中包含的是一些常用的介词或者连词等,这些词不包含关键的信息,但是能串联起其他的词构成一个通顺的句子。然后对种子问题答案对的问题集进行分词和词性的标注,其中词性标注略过那些在停用词表中的词,目的是这些词可能不会在句子中出现但是他们能使之后用模板生成的问题具有通顺性。例如对问题“澳大利亚的首都在哪里”,进行分词和词性标注后为“澳大利亚ns/的/首都n/在哪里”,其中ns、n是“澳大利亚”、“首都”的词性代表地点名词、名词,“的”、“在哪里”出现在停用词表中所以不进行词性标注。用词性替换分词结果得到一个模板temi:“ns的n在哪里”的模板保存到模板库。然后对模板中的模板利用语义词扩展进行一个去重,例如【在哪里,在哪,何处】等语义非常接近,因此模板“ns的n在哪里”、“ns的n在哪”、“ns的n在何处”能合并为一个模板。
预训练打分模型,打分模型如图3所示,对种子问题答案对的答案集进行关键词的提取和词性的标注,例如对一条问题答案对,qi:“澳大利亚的首都在哪里”ai:“堪培拉,澳大利亚联邦首都,位于澳大利亚山脉区的开阔谷地上,位于澳大利亚东南部”,对ai提取关键词和词性标注后得到关键词和关键词的词性:澳大利亚-ns、堪培拉-ns、首都-n,利用关键词的词性搜索之前制作好的模板库,搜索时忽略模板中在停用词表中的词,匹配到的模板是:ns的n在哪里、n的ns在哪里。用关键词替换模板中的词性部分,得到合格问题:“澳大利亚的首都在哪里”,标注其得分为1,也可能得到不合格的问题如:“首都的澳大利亚在哪里”,标注其得分为0,将句子的关键词、生成的问题(例如:澳大利亚堪培拉首都<to>澳大利亚的首都在哪里,其中<to>作为句子关键词与生成问题的分隔符)作为训练模型的输入加入训练集,问题的得分作为训练集的标签,训练打分模型,打分模型的最后一层一个softmax层用于将最后的输出归一化到0到1之间作为最后的输出得分。训练后的打分模型可以用于对之后生成的问题进行一个打分,打分的目的是提高生成问题的质量。
预训练自动生成模型,自动生成模型如图4所示,自动生成模型为一个序列模型,模型的输入输出均为序列。将种子问题答案对的答案集分词后的序列作为自动生成模型的训练集输入,种子答案对的问题集分词后的序列作为自动生成模型的训练集的输出。训练好后的自动生成模型之后可以对输入的中文句子,自动得到由该中文句子生成的中文问题。
步骤2,获取中文通告文档,对所述中文通告文档进行预处理,提取关联语句。
本实施例中,获取中文通告文档,通过预处理模块400对文档进行预处理,可以通过人工收集或者网络爬虫自动爬取中文通告文档,对文档进行分段、分句和获取文档的标题和来源,利用计算句子含有信息的算法,筛选出含有关键信息的句子,保证了生成的问题具有一定的价值,同时提高生成问题的效率。计算句子含有信息的算法公式如下:
st.α+β+γ=1
其中,infi表示句子
步骤3,根据所述规则集中的规则对所述关联语句进行规则匹配,当所述关联语句与一规则匹配时,根据该规则的生成问题表达式生成所述关联语句的问题,保存生成的问题和语句至问题答案对库。
本实施例中,通过规则匹配模块500实现规则与句子的匹配。利用通告的书写规范,预设一套与通告书写规范对应的正则表达式作为规则,每条规则中包含了由该规则生成问题的表达式,之后对筛选过后的句子进行检测是否匹配某条规则,然后利用该规则的生成问题表达式来生成相应的问题。
步骤3通过以下流程实现:
步骤31,判断规则集中是否有规则与关联语句匹配。
本实施例中,用句子搜索预设的规则集。
步骤32,当所述关联语句与一规则匹配时,根据该规则的生成问题表达式生成所述关联语句的问题,保存生成的问题和语句至问题答案对库。
本实施例中,当有规则与之匹配时,提取匹配到的规则rei对应的问题生成表达式exi,根据问题生成表达式exi生成问题,保存生成的问题和语句至问题答案对库。
步骤33,当所述关联语句没有匹配到任何一个规则时,流程进入步骤4,进行模板匹配。
步骤4,当所述关联语句没有匹配到任何一个规则时,对该语句进行关键词提取,根据所述模板库中的模板对提取的关键词进行匹配,当所述关键词匹配到对应模板,根据该模板生成问题。
本实施例中,通过模板匹配模块600实现模板与句子的匹配。对句子进行关键词的提取和词性标注,获取关键词和关键词的词性,利用句子的关键词和关键词的词性搜索匹配的问题模板库,然后利用匹配到问题模板进行替换生成句子对应的问题。由于是用关键词的技巧来匹配模板生成问题,能保证生成的问题含有句子的关键信息,提高生成的问题与句子的相关性和生成的效率。
步骤4过以下流程实现:
步骤41,当所述关联语句没有匹配到任何一个规则时,对该语句进行关键词提取,判断模板库中是否有模板与提取的关键词匹配。
本实施例中,对句子进行关键字提取和词性标注,获得关键词和关键词的词性。
步骤42,当所述关键词匹配到对应模板,根据该模板生成的问题,流程进入步骤5。
本实施例中,用关键词的词性在问题模板库中进行搜索,搜索时忽略那些在停用词表中的词,只关注问题模板库的词性部分,提取出匹配的模板temi,问题模板库中的词性部分用词性相同的关键词进行替换生成候选的问题集。
步骤43,当所述关键词没有匹配到任何一个模板时,流程进入步骤6。
步骤5,根据所述打分模型对所述步骤4中生成的问题进行打分,当得分超过预设阈值时将该问题与关联语句保存至所述问题答案对库和打分模型训练集中,将生成该问题的模板保存至所述模板库中。
本实施例中,通过打分模块800对步骤42中生成的候选问题集进行打分,打分模型如图3所示。利用之前预训练的的打分模型对候选问题集逐个进行打分。通过运用打分模型进行打分的技巧可以剔除问题候选集中的不合格问题,保证生成的问题的有效性。候选集问题打分算法公式如下:
ut=tanh(wwht+bw)
c=∑αht
score=softmax(fc(c))
ht,表示lstm时刻t的状态,它是由t时刻的正向状态
步骤51,应用所述打分模型对所述步骤4生成的问题进行打分,判断得分是否超过所述预设阈值。
步骤52,当得分超过所述预设阈值时,将该问题与关联语句保存至所述问题答案对库和打分模型训练集中,将生成该问题的模板保存至所述模板库中。
本实施例中,当得分超过预设阈值时,表明该问题为合格问题,将该问题与句子保存至问题答案对库和打分模型训练集中,将生成该问题的模板保存至模板库中。
步骤53,当得分未超过所述预设阈值时,流程进入步骤6。
步骤6,将未匹配到模板的语句或所述模板生成的问题在所述打分模型中得分不超过预设阈值的语句输入至所述自动生成模型中生成问题,将所述自动生成模型生成的问题应用所述打分模型进行打分,将得分超过所述预设阈值的生成问题和语句保存至所述问题答案对库。
本实施例中,将步骤43中未匹配到模板的句子和步骤53中得分未超过预设阈值的句子输入至自动生成模型中,将生成的问题再次输入至打分模型中进行打分,将得分超过预设阈值的问题和句子保存至问题答案对库中。
自动生成模型如图4所示,过程如下:
对句子进行分词的到分词后的句子序列(w1,w2,…wn);
将句子序列输入至自动生成模型中,自动生成模型为序列模型,得到一个输出序列作为生成的问题。自动生成模型生成问题算法公式为
编码器encoder总输入为si=(x1,x2…xli),encoder中未使用双向的循环网络因为许多研究表明在encoder中将输入序列反向输入有时效果更好而且能减少模型的复杂度同时减轻过拟合压力,li表示句子si分词后的总词数,
步骤7,将生成了问题的模板扩展至所述模板库,基于扩展后的所述打分模型训练集训练所述打分模型,基于扩展后的问题答案对库训练所述自动生成模型。
本实施例中,利用前面生成的合格问题扩展模板库,利用扩展打分模型训练集重新训练打分模型,利用扩展种子问题答案对重新训练自动生成模型,利用这技巧可言提高之后生成问题的质量。具体的过程如下:
将合格问题和句子保存至种子问题答案对知识库;
合格问题如果不匹配问题模板库中的任何一个模板,则用制作问题模板的方法制作合格问题的模板保存至模板库;
句子的关键词、生成的所有问题和所有的得分(包含合格及不合格问题及其得分)其中句子的关键词、问题中间加入一个分隔符<to>作为打分模型训练集的输入,得分作为打分模型训练集的标签,保存至打分模型的训练集当中;
利用扩展后的打分模型训练集重新训练打分模型,利用扩展后的种子问题答案对库重新训练自动生成模型。
综上所示,本发明利用计算句子所含信息的算法,提取出含有价值信息的句子。利用通告书写规范制定的规则和规则相应的问题生成表达式,能快速生成问题,提高的问题生成的速度。利用关键词和关键词词性进行模板匹配生成候选的问题集,可以保证生成问题与原句的相关性。打分模块800可以对候选的问题集进行打分,可以剔除一部分候选问题集,保证了生成的问题的通顺性。同时问题的模板库、打分模型的训练集和自动生成的模型的训练集均是可扩展的,这说明系统是可以达到自优化的,保证了之后生成问题的质量。本发明的另一个优势在于没有直接对句子进行语法语义分析或句子依存分析,利用速度较快的关键词提取、词性标注技术达到了较快的生成速度,提高了生成问题答案对的效率。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!