一种基于独立循环神经网络的新能源出力预测方法及系统与流程
本发明涉及新能源发展预测技术领域,尤其涉及一种基于独立循环神经网络的新能源出力预测方法及系统。
背景技术
随着能源的日益短缺和绿色发展路线的贯彻,推进能源结构改革和实现可持续发展成为我国能源系统改革的重中之重,而我国在太阳能、风能和电能等新能源领域也取得了高速发展。但是,在全国广泛推广使用新能源的同时,新能源出力的不确定性使风机和光伏电源等新能源的发展受到一定程度的限制,而准确预测出力状况能够实现新能源的高效消纳,因此,风机、光伏等新能源的出力预测对电力调度工作具有重大意义。目前,较为成熟的预测方法大多根据新能源历史发电量进行预测,如灰色预测算法、神经网络法、支持向量机等,但这些方法均缺乏对政策、城市发展规划等因素的着重考量,存在着预测精度不理想的问题,不适用于新能源大规模推广应用的大背景。近年来,深度学习、人工智能技术的进步为精细化考量新能源出力的影响因素并提高预测精度提供了有效途径,因此,在城市大力发展新能源的背景下,亟待需要一种着重考量新能源渗透率的变化的新能源出力预测方法。
技术实现要素:
本发明的目的是提供一种基于独立循环神经网络的新能源出力预测方法及系统,能够着重考量新能源渗透率的变化,预测出更为精准的年度新能源出力典型曲线,为地区电力规划建设与调度工作提供更为可靠的参考。
本发明采用的技术方案为:
一种基于独立循环神经网络的新能源出力预测方法,包括以下步骤:
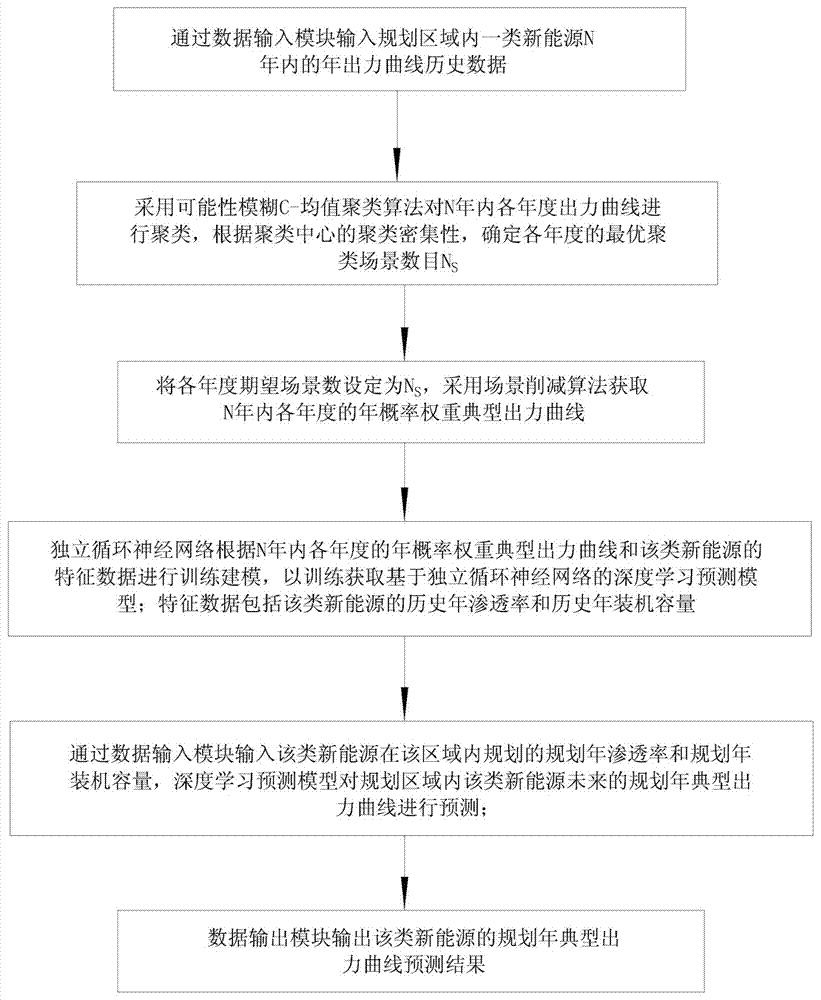
a、通过数据输入模块输入规划区域内一类新能源n年内的年出力曲线历史数据;
b、采用可能性模糊c-均值聚类算法对n年内各年度出力曲线进行聚类,根据聚类中心的聚类密集性,确定各年度的最优聚类场景数目ns;
c、将各年度期望场景数设定为ns,采用场景削减算法获取n年内各年度的年概率权重典型出力曲线;
d、独立循环神经网络根据n年内各年度的年概率权重典型出力曲线和该类新能源的特征数据进行训练建模,以训练获取基于独立循环神经网络的深度学习预测模型;特征数据包括该类新能源的历史年渗透率和历史年装机容量;
e、通过数据输入模块输入该类新能源在该区域内规划的预计特征数据,深度学习预测模型对规划区域内该类新能源未来的规划年典型出力曲线进行预测;预计特征数据包括该类新能源的规划年渗透率和规划年装机容量;
f、数据输出模块输出该类新能源的规划年典型出力曲线预测结果。
进一步地,所述步骤b中可能性模糊c-均值聚类算法的目标函数表达公式如下:
公式(1)中,u表示隶属度原型矩阵,t表示典型性原型矩阵,v表示聚类中心,x表示原始数据集,c表示聚类中心数目,uik代表n个元素相对于c个聚类中心的隶属度,tik代表n个元素相对于c个聚类中心的典型性值,a用于表征隶属度值的影响,b用于表征典型性值的影响,m和η为加权指数,xk表示原始数据元素,vi表示聚类中心元素,γi表示算法的惩罚因子参数,为正数。
进一步地,所述隶属度原型矩阵u的计算公式为:
公式(2)中,dika表示样本数据k与聚类中心i之间的欧氏距离,djka表示样本数据k与聚类中心j之间的欧氏距离;
典型性原型矩阵t的计算公式为:
公式(3)中,γi表示算法的惩罚因子参数,为正数;b用于表征典型性值的影响;
聚类中心v的计算公式为:
公式(4)中,a用于表征隶属度值的影响,b用于表征典型性值的影响。
进一步地,所述c个聚类中心的聚类密集性计算公式如下:
公式(5)中,c表示聚类中心数目,var(ci)与var(x)分别代表聚类中心数目为ci的类别内的簇内方差和数据集x的簇内方差;数据集x的簇内方差计算公式为:
公式(6)中,
进一步地,所述步骤b中确定各年度的最优聚类场景数目ns具体包括以下步骤:
b1:设定聚类中心数目c的值,1<c<n,并设定加权指数m值,m取值范围为[1,∞);
b2:初始化算法迭代次数l,使l为1;
b3:将可能性划分矩阵uik进行初始化,设定另一加权指数η的值;
b4:循环迭代运算,更新可能性模糊c-均值聚类算法的隶属度原型矩阵u、典型性原型矩阵t和聚类中心v;若输出的目标函数与前一次循环迭代的输出值之间差值不小于设定的阈值,且l不大于最大循环次数lmax,则继续循环;若输出的目标函数与前一次循环迭代的输出值之间差值小于设定的阈值,或l大于最大循环次数lmax,则停止循环并获取聚类中心数目c下的聚类密集性;
b5:改变聚类中心数目c的值,重复步骤b1至b4,比较不同聚类中心数目下的聚类密集性,通过聚类密集型判定聚类中心数目是否为最优,获取最优聚类场景数目ns。
进一步地,所述步骤c具体包括以下步骤:
c1:设原始数据集x中包含n个不同元素xi,i=1,2,……,n,设元素xi产生的概率为pi,设拟保留场景数为ns;
c2:计算原始数据集x中与元素xi的产生概率pi距离最短的概率pj,获取元素xj,j=1,2,……,n;计算公式为:
c3:从原始数据集x中删除元素xi,删除元素xi由以下公式确定:
c4:原始数据集x中剩余元素数目变为n-1,将被删除元素的概率加到与其距离最近的元素上;
c5:重复步骤c2至步骤c4,直至原始数据集x中剩余元素数目达到设定值ns;
c6:将剩余元素以各自对应概率为权重进行求和,获取场景削减后得到的地区内该类新能源的年概率权重典型出力pt和对应年概率权重典型出力曲线;pt计算公式如下:
公式(9)中,pt表示为场景削减后得到的地区内该类新能源的年概率权重典型出力;pi表示元素xi产生的概率;xi表示原始数据集中的元素,在本方法中具体指新能源出力曲线历史数据。
进一步地,所述的独立循环神经网络包括输入层、隐含层和输出层,输入层输入隐含层的隐含层输入序列为x=(x1,x2,x3,…,xt),隐含层输出至输出层的隐含层输出序列为y=(y1,y2,y3,…,yt),t为时间步长,x为输入隐含层的历史数据,y为输出隐含层的新能源年典型出力曲线预测结果;所述新能源出力预测系统包括:
数据输入模块,用于向场景聚类削减模块和indrnn预测模块输入数据;
场景聚类削减模块,包括数据聚类单元和场景削减单元,数据聚类单元用于将n年内各年度出力曲线进行聚类,确定各年度的最优聚类场景数目ns,场景削减单元用于利用场景削减算法获取n年内各年度的年概率权重典型出力曲线;
indrnn预测模块,包括数据接收单元、预测模型建立单元、新能源出力预测单元和预测结果输出单元,数据接收单元用于接收数据输入模块输入的新能源在n年内的历史年渗透率、历史年装机容量和年出力曲线历史数据,并将接收到的数据传递至独立循环神经网络的输入层,预测模型建立单元用于将n年的年概率权重典型出力曲线、历史年渗透率和历史年装机容量导入独立循环神经网络的隐含层进行训练建模,以训练生成基于独立循环神经网络的深度学习预测模型,新能源出力预测单元用于利用深度学习预测模型对所需预测区域内一类新能源未来的出力状况进行预测,预测结果输出单元用于将新能源出力预测单元的预测结果传递至数据输出模块;
数据输出模块,用于将indrnn预测模块产生的数据传递至外部设备。
进一步地,所述深度学习预测模型表达式如下:
pforecast=f(t,st,vt,pt)(10)
公式(10),t为时间参数,t以年为单位,t=1,2,3,…,n;st是地区规划发展的一类新能源的年渗透率历史数据;vt为地区内该类新能源的年装机容量历史数据;pt为地区内该类新能源的典型年出力曲线历史数据。
进一步地,所述独立循环神经网络的隐含层在时刻t的状态向量ht表达式如下:
ht=σ(wxt+u⊙ht-1+b)(11)
公式(11)中,xt是t时刻的输入数据,σ为sigmoid函数,⊙为hadamard乘积运算,w为当前输入数据的计算权重,u为循环权重,b为神经元偏差,ht-1表示上一时刻隐含层状态向量。
本发明具有以下有益效果:
(1)通过采用独立循环网络进行建模和预测,与改进型循环神经网络、长短时记忆神经网络(lstm)等传统神经网络相比,独立循环网络的神经元相互独立,结构精简,便于堆叠和调节,且能够获取更具深度的网络和获取更精确的预测出力结果,同时,独立循环神经网络还可以很好地利用relu等非饱和函数作为激活函数,在模型训练之后能够取得更优的鲁棒性,对长序列有更为理想的处理效果。
(2)通过使场景削减过程在生成新能源典型出力曲线时,将新能源出力的不确定性纳入考量范围,相比传统的通过聚类算法得出新能源典型出力曲线更具准确性,在保证准确性的同时,降低了独立循环神经网络需要处理的序列数据的规模,更便于独立循环神经网络对数据进行处理,缓解了“梯度消失”问题。
附图说明
图1为本发明中新能源出力预测方法的流程图;
图2为本发明中新能源出力预测系统的结构示意框图;
图3为图2中数据聚类单元的结构图;
图4为图2中场景削减单元的结构图;
图5为本发明中独立循环神经网络的总体架构图;
图6为本发明中独立循环神经网络的结构展开图;
图7为独立循环神经网络隐含层的单一环节结构图。
具体实施方式
如图1所示,本发明公开了一种基于独立循环神经网络的新能源出力预测方法,包括以下步骤:
a、通过数据输入模块输入规划区域内一类新能源n年内的年出力曲线历史数据;
b、采用可能性模糊c-均值聚类算法对n年内各年度出力曲线进行聚类,根据聚类中心的聚类密集性,确定各年度的最优聚类场景数目ns;
可能性模糊c-均值聚类算法的目标函数表达公式如下:
公式(1)中,u表示隶属度原型矩阵,t表示典型性原型矩阵,v表示聚类中心,x表示原始数据集,c表示聚类中心数目,uik代表n个元素相对于c个聚类中心的隶属度,tik代表n个元素相对于c个聚类中心的典型性值;a用于表征隶属度值的影响,b用于表征典型性值的影响;m和η为加权指数,xk表示原始数据元素,vi表示聚类中心元素,γi表示算法的惩罚因子参数,为正数;
可能性模糊c-均值聚类算法的隶属度原型矩阵u的计算公式为:
公式(2)中,dika表示样本数据k与聚类中心i之间的欧氏距离,djka表示样本数据k与聚类中心j之间的欧氏距离;
典型性原型矩阵t的计算公式为:
公式(3)中,γi表示算法的惩罚因子参数,为正数;b用于表征典型性值的影响;
聚类中心v的计算公式为:
公式(4)中,a用于表征隶属度值的影响,b用于表征典型性值的影响;
通过聚类密集性判断聚类中心数目是否为最优,其中,c个聚类中心的聚类密集性计算公式如下:
公式(5)中,var(ci)与var(x)分别代表聚类中心为ci的类别内的簇内方差和数据集x的簇内方差,其中,数据集x的簇内方差的计算公式如下:
公式(6)中,
优选地,采用可能性模糊c-均值聚类算法确定各年度的最优聚类场景数目ns的方法包括以下过程:
b1:设定聚类中心数目c,1<c<n,并设定加权指数m值,m取值范围为[1,∞);
b2:初始化算法迭代次数l,使l为1;
b3:将可能性划分矩阵uik进行初始化,设定另一加权指数η的值;
b4:循环迭代运算,更新可能性模糊c-均值聚类算法的隶属度原型矩阵u、典型性原型矩阵t和聚类中心v;若输出的目标函数与前一次循环迭代的输出值之间差值不小于设定的阈值,且l不大于最大循环次数lmax,则继续循环;若输出的目标函数与前一次循环迭代的输出值之间差值小于设定的阈值,或l大于最大循环次数lmax,则停止循环并获取聚类中心数目c下的聚类密集性;
b5:改变聚类中心数目c的值,重复步骤b1至b4,比较不同聚类中心数目下的聚类密集性,通过聚类密集型判定聚类中心数目是否为最优,获取最优聚类场景数目ns。
c、将各年度期望场景数设定为ns,采用场景削减算法获取n年内各年度的年概率权重典型出力曲线;场景削减算法过程如下:
c1:设原始数据集x中包含n个不同元素xi,i=1,2,……,n,设元素xi产生的概率为pi,设拟保留场景数为ns;
c2:计算原始数据集x中与元素xi产生概率pi距离最短的概率pj,获取元素xj,j=1,2,……,n;计算公式为:
c3:从原始数据集x中删除元素xi,删除元素xi由以下公式确定:
c4:原始数据集x中剩余元素数目变为n-1,将被删除元素的概率加到与其距离最近的元素上;
c5:重复步骤c2至步骤c4,直至原始数据集x中剩余元素数目达到设定值ns;
c6:将剩余元素以各自对应概率为权重进行求和,获取场景削减后得到的地区内该类新能源的年概率权重典型出力pt和对应年概率权重典型出力曲线;pt计算公式如下:
公式(9)中,pt表示为场景削减后得到的地区内该类新能源的年概率权重典型出力;pi表示元素xi产生的概率;xi表示原始数据集中的元素,在本方法中具体指新能源出力曲线历史数据;
由此,基于历史数据,即可得到规划地区历年新能源概率权重典型出力曲线;
d、独立循环神经网络根据n年内各年度的年概率权重典型出力曲线和该类新能源的特征数据进行训练建模,以训练获取基于独立循环神经网络的深度学习预测模型;特征数据包括该类新能源的历史年渗透率和历史年装机容量;
e、通过数据输入模块输入该类新能源在该区域内规划的预计特征数据,深度学习预测模型对规划区域内该类新能源未来的规划年典型出力曲线进行预测;预计特征数据包括该类新能源的规划年渗透率和规划年装机容量;
f、数据输出模块输出该类新能源的规划年典型出力曲线预测结果。
如图2所示,本发明还公开了一种基于独立循环神经网络的新能源出力预测系统,独立循环神经网络包括输入层、隐含层和输出层,新能源出力预测系统包括:
数据输入模块,用于向场景聚类削减模块和indrnn预测模块输入数据;
场景聚类削减模块,包括数据聚类单元和场景削减单元,数据聚类单元用于将n年内各年度出力曲线进行聚类,确定各年度的最优聚类场景数目ns,场景削减单元用于利用场景削减算法获取n年内各年度的年概率权重典型出力曲线;
indrnn预测模块,包括数据接收单元、预测模型建立单元、新能源出力预测单元和预测结果输出单元,数据接收单元用于接收数据输入模块输入的新能源在n年内的历史年渗透率、历史年装机容量和年出力曲线历史数据,并将接收到的数据传递至独立循环神经网络的输入层,预测模型建立单元用于将n年的年概率权重典型出力曲线、历史年渗透率和历史年装机容量导入独立循环神经网络的隐含层进行训练建模,以训练生成基于独立循环神经网络的深度学习预测模型,新能源出力预测单元用于利用深度学习预测模型对所需预测区域内一类新能源未来的出力状况进行预测,预测结果输出单元用于将新能源出力预测单元的预测结果传递至数据输出模块;
数据输出模块,用于将indrnn预测模块产生的数据传递至外部设备。
预测模型建立单元使用独立循环神经网络建立的深度学习预测模型表达式如下:
pforecast=f(t,st,vt,pt)(10)
公式(10),t为时间参数,t以年为单位,t=1,2,3,…,n;st是地区规划发展的一类新能源的年渗透率历史数据;vt为地区内该类新能源的年装机容量历史数据;pt为地区内该类新能源的典型年出力曲线历史数据。
独立循环神经网络隐含层的输入序列为x=(x1,x2,x3,…,xt),输出序列为y=(y1,y2,y3,…,yt),t为时间步长,x为输入隐含层的历史数据,y为输出隐含层的新能源年典型出力曲线预测结果,输入序列由输入层输入隐含层,输出序列由隐含层输入输出层;隐含层在时刻t的状态向量ht表达式如下:
ht=σ(wxt+u⊙ht-1+b)(11)
公式(11)中,xt是t时刻的输入数据,σ为sigmoid函数,⊙为hadamard乘积运算,w为当前输入数据的计算权重,u为循环权重,b为神经元偏差,ht-1表示上一时刻隐含层状态向量。
为了更好地理解本发明,下面结合附图对本发明的技术方案做进一步说明。
本发明中所述的基于独立循环神经网络的新能源出力预测系统基于计算机平台建立,可通过matlab、python等软件实现,该系统所安装的计算机内包括处理器、数据输入模块、场景聚类削减模块、indrnn预测模块、数据存储模块和数据输出模块。
数据输入模块为计算机输入设备,包括但不限于键盘、鼠标等,数据存储模块包括但不限于只读存储器rom、电可擦除可编程只读存储器eeprom、闪速型存储器flashmemory以及固体硬盘等,数据输出模块包括但不限于显示器等,处理器包括但不限于中央处理器cpu、图形处理器gpu等。
场景聚类削减模块包括但不限于数据聚类单元和场景削减单元,本模块的各单元指的是能够被计算机的处理器执行并运行以实现特定功能的计算机程序指令段,可由matlab、python等软件编写实现,并存储于计算机的数据存储模块中。
indrnn预测模块包括但不限于数据接收单元、预测模型建立单元、新能源出力预测单元和预测结果输出单元,本模块的各单元指的是能够被计算机的处理器执行并运行以实现特定功能的计算机程序指令段,可由matlab、python等软件编写实现,并存储于计算机的数据存储模块中。
本发明中所述的基于独立循环神经网络的新能源出力预测方法的流程如图1所示,所构建的深度学习预测模型基于深度学习领域中的独立循环神经网络(indrnn)实现,如图5所示,构建模型所使用的独立循环神经网络(indrnn)由输入层、隐含层、输出层构成。
如图1和图2所示,基于独立循环神经网络的新能源出力预测方法包括以下步骤:
步骤a、通过计算机数据输入模块输入规划区域内某一类新能源n年内的年出力曲线历史数据,并将年出力曲线历史数据传递至场景聚类削减模块中;
步骤b、如图3所示,场景聚类削减模块的数据聚类单元采用pfcm聚类算法(可能性模糊c-均值聚类算法)对n年内各年度出力曲线历史数据进行聚类,pfcm聚类算法目标函数表达公式如下:
公式(1)中,u表示隶属度原型矩阵,t表示典型性原型矩阵,v表示聚类中心,x表示原始数据集,c表示聚类中心数目,uik代表n个元素相对于c个聚类中心的隶属度,tik代表n个元素相对于c个聚类中心的典型性值;a用于表征隶属度值的影响,b用于表征典型性值的影响;
pfcm聚类算法的隶属度原型矩阵u的计算公式为:
公式(2)中,dika表示样本数据k与聚类中心i之间的欧氏距离,djka表示样本数据k与聚类中心j之间的欧氏距离;
典型性原型矩阵t的计算公式为:
公式(3)中,γi表示算法的惩罚因子参数,为正数;b用于表征典型性值的影响;
聚类中心v的计算公式为:
公式(4)中,a用于表征隶属度值的影响,b用于表征典型性值的影响;
通过聚类密集性判断聚类中心数目是否为最优,其中,c个聚类中心的聚类密集性计算公式如下:
公式(5)中,c表示聚类中心数目,var(ci)与var(x)分别代表聚类中心为ci的类别内的簇内方差和数据集x的簇内方差;其中,数据集x的簇内方差计算公式如下:
公式(6)中,
进一步地,通过pfcm聚类算法,根据聚类中心的聚类密集性确定各年度的最优聚类场景数目ns,具体过程为:
b1:设定聚类中心数目c,1<c<n,并设定加权指数m值,m取值范围为[1,∞);
b2:初始化算法迭代次数l,使l为1;
b3:将可能性划分矩阵uik进行初始化,设定另一加权指数η的值;
b4:进行循环迭代运算,更新可能性模糊c-均值聚类算法的隶属度原型矩阵u、典型性原型矩阵t和聚类中心v;若输出的目标函数与前一次循环迭代的输出值之间差值不小于设定的阈值,且l不大于最大循环次数lmax,则继续循环;若输出的目标函数与前一次循环迭代的输出值之间差值小于设定的阈值,或l大于lmax,则停止循环并获取聚类中心数目c下的聚类密集性;
b5:改变聚类中心数目c的值,重复步骤b1至b4,比较不同聚类中心数目下的聚类密集性,通过聚类密集型判定聚类中心数目是否为最优,获取最优聚类场景数目ns;
步骤c、如图4所示,场景削减单元利用利用步骤b得到的最优聚类场景数目进行场景削减,场景削减单元所采用的场景削减算法过程如下:
c1:设原始数据集x中包含n个不同元素xi,i=1,2,……,n,设元素xi产生的概率为pi,设拟保留场景数为ns;
c2:计算原始数据集x中与元素xi产生概率pi距离最短的概率pj,获取元素xj,j=1,2,……,n;计算公式为:
c3:从原始数据集x中删除元素xi,删除元素xi由以下公式确定:
c4:原始数据集x中剩余元素数目变为n-1,将被删除元素的概率加到与其距离最近的元素上;
c5:重复步骤c2至步骤c4,直至原始数据集x中剩余元素数目达到设定值ns;
c6:将剩余元素以各自对应概率为权重进行求和,获取场景削减后得到的地区内该类新能源的年概率权重典型出力pt和对应年概率权重典型出力曲线;pt计算公式如下:
公式(9)中,pi表示元素xi产生的概率;xi表示原始数据集中的元素,在本方法中具体指新能源出力曲线历史数据;
将各年度期望场景数设定为ns,采用场景削减算法获取n年内各年度的年概率权重典型出力曲线;
由此,基于历史数据,即可得到规划地区历年新能源概率权重典型出力曲线;
步骤d、通过步骤c得到的各年度的年概率权重典型出力曲线,结合该类新能源的历史年渗透率和历史年装机容量数据输入indrnn预测模块的数据接收单元,预测模型建立单元利用独立循环神经网络进行训练建模,以训练获取基于独立循环神经网络的深度学习预测模型;深度学习预测模型表达式如下:
pforecast=f(t,st,vt,pt)(10)
公式(10),t为时间参数,t以年为单位,t=1,2,3,…,n;st是地区规划发展的一类新能源的年渗透率历史数据;vt为地区内该类新能源的年装机容量历史数据;pt为地区内该类新能源的典型年出力曲线历史数据
步骤e、新能源出力预测单元利用深度学习预测模型,基于数据输入模块输入的该类新能源在该区域内规划的规划年渗透率和规划年装机容量,对规划区域内该类新能源未来的规划年典型出力曲线进行预测;
步骤f:通过预测结果输出单元输出该类新能源的规划年典型出力曲线预测结果至计算机的数据输出模块,并进行曲线的可视化。
本发明中所阐述的独立循环神经网络是一种改进的rnn(循环神经网络),传统的rnn是通过对隐含层的状态向量ht递归应用状态转移函数f来处理时间序列的网络。t时刻的隐含层状态向量ht由当前输入xt和前一时刻隐含层状态向量ht-1来决定,表达式如下:
本质上,rnn是一种数据推断机器,只要数据足够多,就可以得到从x(t)到y(t)的概率分布函数,寻找到两个时间序列之间的关联。但是,rnn通过计算梯度,来决定传递回隐藏层的信息,以供网络学习。而梯度信息会随着时间而衰减,使得回传效果变差。处理较长的序列时,间隔较大的数据之间的影响关系表达不明,称为“梯度消失”。为了缓解梯度衰减的问题,使得算法对长序列有更加理想的处理效果,在深度学习领域,不断提出基于rnn的改进算法,如改进型循环神经网络、长短时记忆神经网络(lstm),但随着对rnn的改进,其结构越发复杂。本发明中所阐述的独立循环神经网络(indrnn)与改进型循环神经网络、长短时记忆神经网络(lstm)相比,结构更为简单,但经过测试,对长序列有更为理想的处理效果。原因在于,在传统rnn以及后续的改进算法中,作为激活函数的双曲正切函数和sigmoid函数本身就极易造成梯度衰减,此外,传统的rnn及改进算法中所有神经元连接在一起,使得神经元的运行状况难以解释。在独立循环神经网络中,神经元相互独立,结构精简,便于堆叠和调节,获取更具深度的网络。独立循环神经网络还可以很好地利用relu等非饱和函数作为激活函数,在训练之后取得很好的鲁棒性。
如图5所示,本发明中的独立循环神经网络由输入层、隐含层和输出层构成。如图6所示,隐含层的输入序列为x=(x1,x2,x3,…,xt),输出序列为y=(y1,y2,y3,…,yt),t为时间步长,x为输入隐含层的历史数据,y为输出隐含层的新能源年典型出力曲线预测结果,输入序列由输入层输入隐含层,输出序列由隐含层输入输出层;如图6所示,隐含层在时刻t的状态向量ht表达式如下:
ht=σ(wxt+u⊙ht-1+b)(11)
公式(11)中,xt是t时刻的输入数据,σ为sigmoid函数,⊙为hadamard乘积运算,w为当前输入数据的计算权重,u为循环权重,b为神经元偏差,ht-1表示上一时刻隐含层状态向量。在本实例中,独立循环神经网络隐含层的状态向量ht生成受到三个因素的影响,其一为当前输入数据xt,其二为上一时刻隐含层状态向量ht-1,其三为神经元偏差b。
与现有技术相比,本发明所述的场景削减过程在生成新能源典型出力曲线时,将新能源出力的不确定性纳入考量,比传统的通过聚类算法得出新能源典型出力曲线更具准确性。在保证准确性的同时,降低了独立循环神经网络需要处理的序列数据的规模,更便于独立循环神经网络对数据进行处理,缓解了“梯度消失”问题。
与现有技术相比,本发明所述的独立循环神经网络,结构更为简单,但与传统的rnn神经网络以及长短时记忆神经网络(lstm)相比,对长序列有更为理想的处理效果。
与现有技术相比,本发明中所述基于独立循环神经网络的区域新能源发展预测方法,用于在地区广泛进行新能源电力规划建设的发展新阶段中,结合城市规划,进行新能源年典型出力曲线预测。该发明在新能源规划建设中能够取得更为精确新能源出力预测结果。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解,其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换,而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!