一种基于商品评论的舆情监控方法及系统与流程
本发明涉及电子商务领域,特别是涉及一种基于商品评论的舆情监控方法及系统。
背景技术
随着大量的零售从线下转移到线上,线上零售存在的最大的问题就是实物信息的缺失,特别是对于体验型商品。用户很难通过产品指标和数据确定和评价体验型产品的质量好坏,因此产品的售后评论就成为了影响用户购买决策的重要因素。企业能否及时的对于差评进行及时有效的反馈会很大程度上影响用户对企业的印象,而对与销量较大的电商企业,每天形成的评论数以万计,人工检查是一个庞大而枯燥的工作,自动化的检测问题评论能够有效地降低企业人力成本和提高员工的工作体验。
此外用户的评论对于企业来说不仅是公关的关注对象,同时也是企业内部问题检测的风向标。用户对于产品的评论意见基本会集中在体现在产品的某一方面的性能问题或者销售过程的服务问题。从企业内部检查出这些问题是比较困难的,因此需要一种预警系统。用户在购买产品后往往会客观的描述对产品和企业的意见,通过产品评论企业很容易就查出企业内部的问题,从而进行整改提高企业的服务质量,改善企业形象。出于对评论数量量级的考虑自动化的评论问题的检测和识别是企业预警系统的重要任务。
在过去对于商品评论的研究中,商品评论的分类都是通过文本向量空间模型和情感词典实现情感分类。然而在中文中,句法结构复杂,情感倾向分类困难,过去的研究在情感分类上都未能取得的理想的效果。其最根本的原因在于未能考虑到词语语序带来的文本情感的不同。
近年来流行的深度学习技术在多种分类预测任务中表现极佳,其中循环神经网络(rnn)在情感分类人物中表现最佳。但rnn存在着训练困难,层数和步长增加后容易出现梯度爆炸的问题。长短时记忆神经网络能够有效地进行训练,避免了rnn梯度爆炸的问题,同时保存了rnn能够学习顺序特征的特性。但是基于神经网络的情感分类方法又都以某个很小的领域为目标,同样的模型在其它领域就无法取得有效的结果。而对于企业而言,获取标注数据是困难的,给数据进行标注是一项巨大的工程,普通的企业很难实现这样的目标。
本发明在神经网络方法的基础之上,以lstm为基本算法,将评论分类分解为两阶段问题,分阶段进行学习和训练,构造了一种层次结构的产品评论分类方法和系统,使企业能够在不对大规模数据进行标注的同时,实现可定制的产品评论分类,并且根据评论分类结果对有关企业的舆情进行监控和与预警。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足,提供一种基于商品评论的舆情监控方法及系统。
为解决上述技术问题,本发明提供一种基于商品评论的舆情监控方法,包括词向量嵌入、评论数据收集和预处理、评论数据标引、神经网络训练和自动分类和报警的步骤,具体如下:
步骤1,词向量嵌入,采集网络百科全书中的语料,并对语料进行分词,用分词后的语料训练词向量模型;
步骤2,评论数据收集和预处理,利用爬虫程序模拟用户在浏览器端的行为,获得各个页面的html代码;将html代码根据商品id和时间存储在系统的文件存储系统中;对收集的html代码进行解析,获得评论数据并存入数据库中;
步骤3,评论数据标引,根据需求设置标注体系,对标注界面设置标注指标;抽取一部分评论数据根据已经设置好的标注指标,对评论数据进行人工标注,标注完成的评论数据将存储至数据库中;
步骤4.神经网络训练,根据事先创建的神经网络训练参数文档,初始化一个包含两层lstm和一个多层全连接的神经网络网络结构;选择导入事先训练好的网络权重参数或者使用初始化的权重值;根据神经网络训练参数文档中的batchsize、学习率和学习次数等参数;从数据库中获得评论数据作为神经网络训练数据进行训练;
步骤5,自动分类和报警,从数据库中获得没有标注的,待标注的数据输入神经网络,获得分类结果,分类结果会被自动存入数据库中,分类结果将被抽样检查,检验通过的数据被发送并进行处理,并对消极评论发出警报。
所述步骤1中,网络百科全书选用维基百科,在对语料进行分词前,先进行中文翻译或简繁体转化;所述步骤2中,所述爬虫程序模拟用户在浏览器端的行为包括登陆、搜索、点击、浏览和滚动等,以操作浏览器在各个商品页面上浏览和跳转,所述评论数据包括获得评论内容和评论位置,将评论内容、商品id、评论位置、页面url、评论时间、用户id存入数据库中;所述步骤5中,检验通过的评论数据被发送至人工检查,如果没有通过人工检查,数据自动分类的标注结果将被擦除,并提示重新训练神经网络。
所述步骤1中,运用隐式马尔科夫链对转化后的语料进行分词,将分词后的语料输入word2vec算法中训练词向量模型,得到一个为∑的词语集合以及一一对应的向量集合v的词-向量词典dict;所述dict中的键和值分别为{wi:vi}。其中vi是一个由k个[0,1]之间均匀分布的随机数组成的向量。为了进行下一步的训练,需要设置一个超参数window;根据上述参数和变量,输入层有window*2*k个节点,输出层有k个节点;训练过程如下,首先以某个词wi为中心,找到左右临近的window个词语,依次序在dict中找到这个词语w对应的向量v,将这window*2个词语在dict中对应的词语向量依次首尾相连,拼接为一个window*2*k的向量,输入神经网络的输入层,得到输出结果p;根据dict查找wi对应的k维的向量vi,将vi作为预测目标;计算p与vi之间的损失函数loss,公式为mean(-vilog(p));对loss求输入层的梯度,进行反向传播,调整神经网络的权重和输入的向量,最终收敛,得到一个稳定的dict;用word2vector算法得到dict,dict表示词-向量词典,其中∑是dict中的词语的全集,每一个词语wi∈∑都能从dict中找到唯一一个与之对应的向量vi;所述步骤4中,从数据库中获得评论数据,在步骤1中的词向量模型中进行词向量嵌入,再作为神经网络训练数据进行训练。
所述步骤4中,词向量嵌入后对每一批评论数据根据该批评论数据中的最长的语句,对较短的语句在语句前用零向量进行填补,使每一批评论数据形成一个三阶张量,具体为:
首先对一个评论数据rk进行分词得到一个有序的词语序列seq包含[w1,w2,…,wm],m个词语。
按照词语序列seq中的语序依次在dict中查找词语wi对应的向量vi,若wi不包含于∑则跳过该词,继续查找下一个词语的词向量vi;
对词语序列查找完对应的词向量后得到一个维度为lengthj×k的二维矩阵,其中lengthj是这个评论rk包含于∑的词语数量,因此对于不同的rj其长度lengthj不一定相等;
重复batch次上述抽取一个评论,进行分词和嵌入词向量操作,最终得到一个维度为batch个lengthj×k的矩阵,求取这batch个评论中length的最大值lengthmax,对lengthi<lengthmax的评论矩阵做如下处理,在矩阵前补充一个维度为(lengthmax-lengthi)×k的矩阵;
经上述操作得到的batch个矩阵的维度都为lengthmax×k,将其拼接在一起得到一个维度为batch×lengthmax×k的三阶张量。
所述步骤3中,抽取的每一条评论数据会被分派给两位用户进行人工标注,如标注结果不一致则分派给第三位用户,以标注一致的两位用户的结果作为这条评论数据的最终标注结果。
所述步骤4中,lstm层运算包含遗忘门运算、记忆门运算和输出门运算,全连接神经网络的计算公式为:
d=relu(input·wd+bd)
其中d是全连接神经网络的输出,input是上一层神经网络输入的向量,wd与bd是随机数,反向传播中被训练,在导入训练好的神经网络权重后允许用户继续输入训练数据,优化网络结构。
所述步骤4中,每次训练前将训练数据分为训练数据和测试数据,利用测试数据评价模型准确率,如准确率较低或无法达到理想,可以回滚至神经网络上一状态或者训练全新的神经网络。
一种基于商品评论的舆情监控系统,其特征在于:包括依次相连的词向量嵌入模块、评论数据收集和预处理模块、评论数据标引模块、神经网络训练模块和自动分类和报警模块:
所述词向量嵌入模块用于采集网络百科全书中的语料,并对语料进行分词,用分词后的语料训练词向量模型;
所述评论数据收集和预处理模块用于利用程序模拟用户在浏览器端的行为,获得各个页面的html代码;将html代码根据商品id和时间存储在系统的文件存储系统中;对收集的html代码进行解析,获得评论数据并存入数据库中;
所述评论数据标引模块用于根据需求设置标注体系,对标注界面设置标注指标;抽取一部分评论数据根据已经设置好的标注指标,对评论数据进行人工标注,标注完成的评论数据将存储至数据库中;
所述神经网络训练模块用于根据事先创建的神经网络训练参数文档,初始化一个包含两层lstm和一个多层全连接的神经网络网络结构;选择导入事先训练好的网络权重参数或者使用初始化的权重值;根据神经网络训练参数文档中的batchsize、学习率和学习次数等参数;从数据库中获得评论数据作为神经网络训练数据进行训练;
所述自动分类和报警模块用于从数据库中获得没有标注的,待标注的数据输入神经网络,获得分类结果,分类结果会被自动存入数据库中,分类结果将被抽样检查,检验通过的数据被发送并进行处理,并对消极评论发出警报。
本发明所达到的有益效果:结合了多种深度学习算法和创新性数据处理方法,对于消极评论的判别以及消极评论点的侦测,使得企业能够即使发现消极评论信息并有针对性的进行干预,维护企业形象;并且能够有效的将非结构化的评论数据,转化为业务需要的、可分析的结构化数据。
附图说明
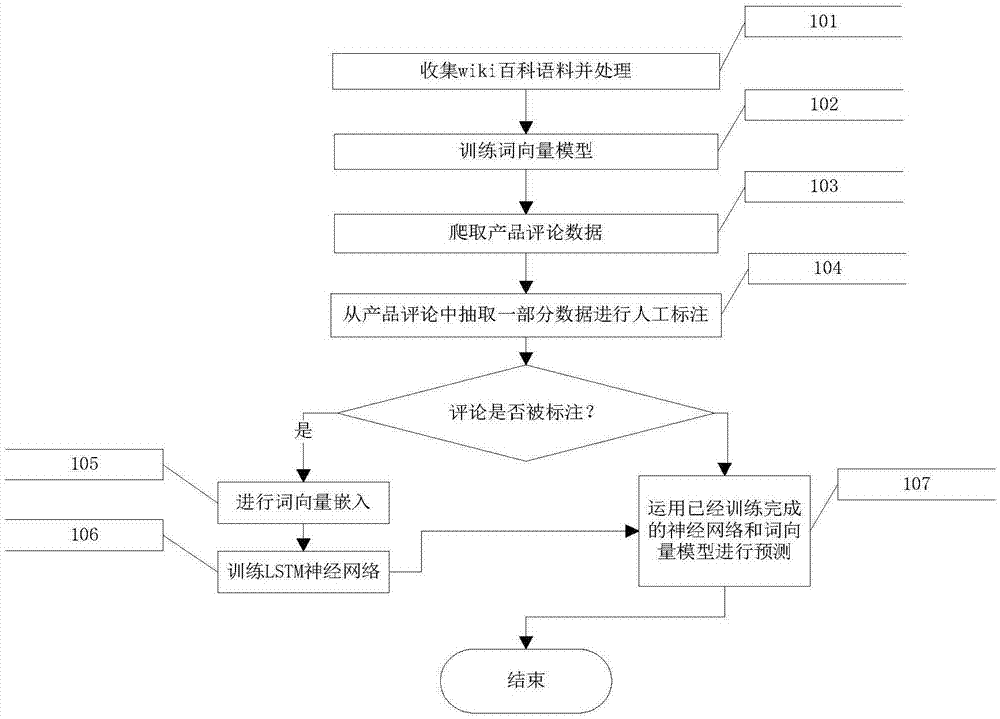
图1为本发明的示例性实施例的步骤流程图;
图2为本发明的示例性实施例的系统结构示意图;
图3为本发明的示例性实施例的词向量嵌入流程示意图;
图4为本发明的示例性实施例的将三阶张量输入输入层的效果示意图
图5为本发明的示例性实施例的神经网络示意图。
具体实施方式
下面结合附图和示例性实施例对本发明作进一步的说明:
如图1所示,本发明采用的技术方案包括以下步骤:
步骤101,用维基百科和公开评论数据组合成语料库corpus,corpus包含d1、d2、……,dn等n篇文档。对所有的文档进行分词操作,由corpus可以得到一个由w1、w2、……,wm组成的包含m个词语的集合∑。然后建立一个字典dict,dict中的键和值分别为{wi:vi}。其中vi是一个由k个[0,1]之间均匀分布的随机数组成的向量。为了进行下一步的训练,需要设置一个超参数window。
步骤102,构造了一个神经网络,根据上述参数和变量,输入层有window*2*k个节点,输出层有k个节点。
步骤102,中的训练过程如下,首先以某个词wi为中心,找到左右临近的window个词语,依次序在dict中找到这个词语w对应的向量v,将这window*2个词语在dict中对应的词语向量依次首尾相连,拼接为一个window*2*k的向量,输入神经网络的输入层,得到输出结果p。根据dict查找wi对应的k维的向量vi,将vi作为预测目标。
步骤102,计算p与vi之间的损失函数loss,公式为mean(-vilog(p))。
步骤102,对loss求输入层的梯度,进行反向传播,调整神经网络的权重和输入的向量,最终收敛,得到一个稳定的dict。
步骤102用word2vector算法得到dict,dict表示词-向量词典,其中∑是dict中的词语的全集,每一个词语wi∈∑都能从dict中找到唯一一个与之对应的向量vi。
步骤201训练word2vec模型时所使用的训练语料为,维基百科和评论语料,因此训练得到的模型的词典集合大于仅仅用评论语料训练的模型,保证了词向量嵌入时句子信息的完整性;且由于这两个语料数量巨大,能够满足复杂模型训练的数据要求,保证了训练模型的效果。
步骤103,爬虫程序爬取数据,收集制定的商品评论。系统会模拟人的点击、滚轮滚动和输入行为,设置一定的停留间隔和操作流程后能够最大程度的避免被反爬虫系统封禁。被爬虫系统封禁之后自动关闭当前爬虫程序,重新启动新的爬虫进程。在爬虫运行一段时间后中断当前的爬虫进程,更换代理后重启启动新的爬虫,进一步保证爬虫的正常运行。
步骤103,爬虫爬取的数据放入数据库中,以网页的url作为唯一识别标志,当爬取新的数据时发现当前记录已经收录就不再重复爬取。爬虫进程可以定时调用,保证系统中的数据具有时效性。
步骤103利用页面操作脚本,登陆电商平台,进入本店在售产品列表页,采集所有产品页面的url得到url集合items。
步骤103依次访问items中所有的产品详情页,利用页面操作脚本,操作浏览器进行网站的登陆、搜索和翻页等操作,获得网页的原始html代码,然后对html标签进行解析提取评论栏内的评论文档内容s并合并为文档集合docs。获取items中的评论信息,当某个产品的评论信息已被获取后就标记为已爬取,设置定时程序定期更新评论信息。
步骤104由业务人员和管理人员进行标引体系的指定,设置研究问题q1、q2、…、qn,以及对应问题的类别c1、c2、…、cn,其中c1包括c11、c12、…c1m等不同的取值。例如针对快递问题q1对应的类别为c1,其中包括的取值有c11“正常”、c12“速度慢”、c13“损坏”三个不同的取值。
步骤104由标引人员从评论数据文档集合docs中抽取一定数量的评论,针对标引体系中的问题q依次选择其类别,交由两个标引员完成人工标引任务,当两个标引员标注的结果一样时,标引结果被存入数据库中;当两个标引员标注的结果不一致时,由第三个标引员进行标引的,将第三个标引员的标注结果存入数据库中。
步骤104中得到的文档集合doc抽取一定的数据进行人工标引用于生成训练数据doc。
步骤202将任意语句分解成由词语有序组成的序列。
步骤202到步骤205中词向量嵌入的方式如下,首先对一个评论rk进行分词得到一个有序的词语序列seq包含[w1,w2,…,wm],m个词语。
步骤202分词以后,步骤205,按照序列seq中的语序依次在dict中查找词语wi对应的向量vi,若wi不包含于∑则跳过该词,继续查找下一个词语的词向量vi,词向量嵌入后的实施例如图3所示。
步骤105和步骤107对词语序列查找完对应的词向量后得到一个维度为lengthj×k的二维矩阵。其中lengthj是这个评论rk包含于∑的词语数量,因此对于不同的rj其长度lengthj不一定相等。
步骤106和步骤107重复batch次上述抽取一个评论,进行分词和嵌入词向量操作,最终得到一个维度为batch个lengthj×k的矩阵。求取这batch个评论中length的最大值lengthmax,对lengthi<lengthmax的评论矩阵做如下处理。在矩阵前补充一个维度为(lengthmax-lengthi)×k的矩阵。
步骤105和步骤107,经上述操作得到的batch个矩阵的维度都为lengthmax×k,将其拼接在一起得到一个维度为batch×lengthmax×k的三阶张量。
步骤105和步骤107,依第二个维度依次将维度为batch×k的三阶张量输入输入层,输入层包含由k个节点,输入层输出为k维向量,输入lstm层中。输入方法的实施例效果图如图4所示。
步骤106,lstm层运算包含遗忘门运算、记忆门运算和输出门运算。其中遗忘门运算用于决定神经元中的长期状态向量是否保留,该门会读取当前的输入xt和神经元当前的短期状态h_t-1,输出一个0到1之间的数值表示对长期状态c_t-1的保留程度,公式如下所示:
ft=σ(wf·[ht-1,xt]+bf)
步骤106,其中wf与bf是随机数,在后面的训练过程中会被自动计算得出,σ是sigmoid函数,公式如下:
步骤106,当句子中出现新的主语,此时我们希望它遗忘原来的主语时,遗忘门就能实现对过去的主语遗忘的功能。
步骤106,记忆门运算基于当前的输入和上一时刻的短期状态计算如何对长期状态进行更新,包括更新选择操作it与更新候选操作c_t。更新选择操作计算哪些候选值用于更新长期操作,更新候选操作用于产生候选值。具体计算公式如下:
it=σ(wi·[ht-1,xt]+bi)
c-t=tanh(wc·[ht-1,xt]+bc)
步骤106,其中wi、wc与bi、bc是随机数在训练过程中被训练。
步骤106,完成记忆门和遗忘门的计算后就可以进行长期状态的更新,更新的公式为:
ct=ct-1·ft+it·c-t
步骤106,最终lstm需要决定需要输出什么值,lstm具有记忆性,能够结合当前时刻的输入、上一时刻的状态以及长期状态做出预测,因此对于序列数据有很好的效果,lstm的输出就是当前时刻的短期状态。当前时刻的输出门计算公式如下:
ot=σ(w0[ht-1,xt]+b0)
ht=ot·tanh(ct)
步骤106,其中wo与bo为随机数,在反向传播中训练,ht作为短期状态,ct作为长期状态传递至下一时刻,且ht作为当前时刻输出。
步骤106,对于序列数据,预测的结果并不总是仅仅和当前输入相关,还和前面的几次状态有关,因此将前面的多次状态输入能够考虑到序列数据的顺序问题,实现较好的预测效果。
步骤106循环神经网络包含num_units个节点,因此lstm层的输出为num_units维的向量。在lstm层后加入一个全连接神经网络,全连接神经网络的计算公式为:
d=relu(input·wd+bd)
步骤106,d是全连接神经网络的输出,input是上一层神经网络输入的向量,wd与bd是随机数,反向传播中被训练。堆叠数个上述全连接神经网络,抽取预测时需要的抽象特征。用最后一层的d计算σ(d),得到分类的概率p。神经网络如附图5所示。
根据损失函数:
步骤106,可以对前面所用的w和b等随机数求取梯度dw和db,对所有的w和b进行如下值更新:
w=w-dw·l
b=b-db·l
步骤106,其中l是管理员设置的一个小数作为学习率,由上述操作完成一次训练过程。
步骤106,重复上述训练过程,loss值会不断下降,管理员可以通过系统设置训练的时间和次数,当训练的时间或次数中的某一限制条件达到后停止训练,保存神经网络模型和权重。
步骤106,对于训练时训练数据不足的问题,由于数据标引需要消耗大量人力物力和时间,绝大多数公司无法负担标引数据的高昂费用。本发明创新性的将word2vector与深度神经网络结合,word2vec作为一种无监督学习算法能够有效的学习词语间关系,挖掘潜在的语义信息。本发明在训练word2vector模型时使用的语料是公共语料,没有领域特征,因此对于不同语境下的信息描述有非常好的扩展性。企业能够使用公开的大量评论语料结合自身的评论语料进行模型训练,在不降低模型效果的情况下能够实现训练数据集的扩增,训练出来的模型也有较好的迁移能力。
对于步骤107,对评论预测时,不需要计算loss和梯度,也不需要进行权重的更新,将预测结果p直接写入数据库中,完成对评论数据的分类。
对于步骤107,管理员能够对分类结果进行定期抽检,当准确率不满足要求时,将最近的数据取出,进行人工标引,不需要进行神经网络的初始化,在现有神经网络的基础上,使用新数据进行训练,直到模型的效果满足要求。由于神经网络中存在大量的权重,训练需要大量的数据和时间,这样的训练方式避免了对模型进行优化时需要重新从头训练一个随机的神经网络,大大节约了训练时间。
步骤107,对于分类的结果,系统会自动汇总不同问题q下差评和问题评论出现的次数和比率,对于出现次数较高和占比较高的问题,系统会进行高亮显示,提示管理员需要向企业内有关部门反应,实现预警的目标。例如,当某天新增的评论中有大量的评论被分类为“材质不好”此时就需要通知质检部门对产品进行检验,如果出现质量问题就通知采购部门联系供应商,反应产品质量存在问题。
本发明主要用于提供一种基于商品评论的舆情监控方法及系统,结合了多种深度学习算法和创新性数据处理方法,对于消极评论的判别以及消极评论点的侦测,使得企业能够即使发现消极评论信息并有针对性的进行干预,维护企业形象;并且能够有效的将非结构化的评论数据,转化为业务需要的、可分析的结构化数据。
以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!