基于蚁狮优化算法的云计算任务调度方法与流程
本发明涉及一种云计算任务调度方法,具体涉及一种基于蚁狮优化算法的云计算任务调度方法,属于云计算任务调度领域。
背景技术
云计算(cloudcomputing)是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。云计算技术是分布式处理、并行处理和网格处理的发展,其包括了虚拟化技术、分布式海量数据存储、海量数据管理技术和云计算平台管理技术,主要将硬件(laas)、软件(saas)和平台(paas)等组成资源池,实现数据的计算、储存、处理和共享的一种托管技术。云计算不仅是一种理论,也是一种商业模式的体现方式,企业技术网络系统的后台服务需要大量的计算、存储资源和移动端及pc端软件服务对资源共享,只能通过云计算技术实现。
在云计算实际环境下,用户将自己的需求作为任务提交给云计算中心,云计算中心将任务划分为子任务,分配给合适的资源节点处理,再把处理好的结果返回给用户。在云计算领域中的对于资源分配策略是一项重要研究,对于不同的需求,资源分配的目标也是不同的:针对用户使用的云平台更加注重用户的服务质量(qos),保证用户的使用感受;针对企业用户的云平台则侧重资源负载平衡,保证可靠和稳定,同时尽可能减少支出。但是调度算法是一个np-hard(non-deterministicpolynomial,非确定性多项式)问题,这类问题的大型实例不能用精确算法求解,必须寻求这类问题的有效的近似算法。目前商用领域通常采用先来先服务(fcfs)/先进先出(fifo)调度算法、短作业优先调度算法(sjf)和高优先权调度算法等方法,上述方法资源利用率低,节点负载均衡未考虑,用户间不同需求的优先级也未考虑。
本发明提出的蚁狮优化算法(antlionoptimizer)是一种启发式算法,它是受到了自然界中蚁狮捕食蚂蚁的启发,算法流程主要包含五个部分:蚂蚁的随机移动、蚁狮构建陷阱,蚂蚁陷入陷阱,蚁狮捕获猎物和重新构建陷阱。蚁狮优化算法具有全局优化、调节参数少、收敛精度高、鲁棒性好的优点。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于蚁狮优化算法的云计算任务调度方法,通过蚁狮算法来优化调度任务的时间和处理任务的功耗成本,能够根据用户需求调整评价函数,侧重对云计算的性能优化,并且能够使用动态权值参数来正反馈地加速结果输出,提高了搜索精度。
为实现以上目的,本发明采用以下技术方案:
本发明提供一种基于蚁狮优化算法的云计算任务调度方法,包括以下步骤:
s1、根据用户提交的任务,确定任务的参数以及适应度函数的权值α;
s2、根据s1中的所述参数,初始化蚁狮算法中蚂蚁和蚁狮的位置;
s3、根据s1中的所述权值α建立适应度函数,通过任务与虚拟机的映射关系计算出适应度结果;根据蚂蚁的坐标使用适应度函数计算出每只蚂蚁的适应度,若蚂蚁的适应度函数小于蚁狮的适应度函数,则更新蚁狮的位置,同时选出适应度最小的蚁狮作为精英蚁狮;
s4、根据每只蚂蚁的适应度函数结果,使用轮盘法选择对应的蚁狮,蚂蚁的新位置由选择的蚁狮和唯一的精英蚁狮通过随机游走获得;
s5、更新蚂蚁位置后,再次使用适应度函数计算蚂蚁和蚁狮的适应函数值;
s6、判断是否大于最大迭代次数;若是,则输出精英蚁狮的位置,由任务与虚拟机的映射关系表得到最终的任务分配方案;若否,则返回步骤s4。
进一步地,步骤s1中,用户提交任务后将n个任务和m台虚拟机之间的关系被抽象成矩阵mtask和mnet,分别为:
其中:mtask中ti,j表示第i个虚拟机、第j个任务的长度,单位是百万条指令;mnet中ni,j表示对第i台虚拟机、接收和提交第j个任务在网络上消耗的时间,单位是秒。
进一步地,所述适应度函数的权值α是qos的权重,且α∈(0,1)。
进一步地,步骤s2中初始化参数,种群数量为k,蚂蚁的位置表示为mant,蚁狮的位置表示为mantlion,即:
其中:ai,j和ali,j初始化为ai,j,ali,j=random*m,random是在[0,1)上随机均匀分布的随机值。
进一步地,步骤s3中,适应度函数表示为:
fitnessk=α(spantime)+(1-α)cost;(5)
其中,spantime表示时间跨度,cost表示功耗消耗。
进一步地,所述时间跨度spantime和功能消耗cost通过下述计算得到:
spantime=max(timei);(7)
cost=(prun-pfree)∑timei+pfree*spantime*m;(8)
其中,ci表示第i台虚拟机的计算能力,单位是mips;prun代表虚拟机满负荷运行时的功耗,pfree代表虚拟机待机时的功耗;蚂蚁和蚁狮的适应度函数矩阵由蚂蚁和蚁狮的坐标所决定:
进一步地,步骤s4中,根据mantlionfitness的结果获得轮盘法所需数据mwheel,其对应关系是:
第i只蚂蚁选择蚁狮的过程表示为:
selectantlioni=random*mwheel[k];(12)
其中,random是在[0,1)上随机均匀分布的随机值。
进一步地,当选择第一个大于selectantlioni的mwheel[j],则j为选择的蚁狮,随机游走表示为:
经过t次迭代后,可得随机游走中的最大值为randomwalkmax、最小值randomwalkmin和当前randomwalk(t),由这三个值归一化计算得到第t次的随机步长:
其中,lbit和ubit表示第t次迭代的搜索边界。
已有技术相比,本发明具有如下有益效果:
本发明考虑了用户对于云任务时效性需求的不同,通过设置自适应度函数的权值调节评价倾向,因为迭代搜索最优解的评价过程严格按照自适应度函数值来评价,所以可以在保证用户体验的前提下降低服务提供商的成本;本发明通过带有随机性的全局搜索和迭代过程中的正反馈调节搜索范围,可以精确调节虚拟机群在本次任务计算中的搜索解,避免出现资源利用率低、节点过载的情况。
附图说明
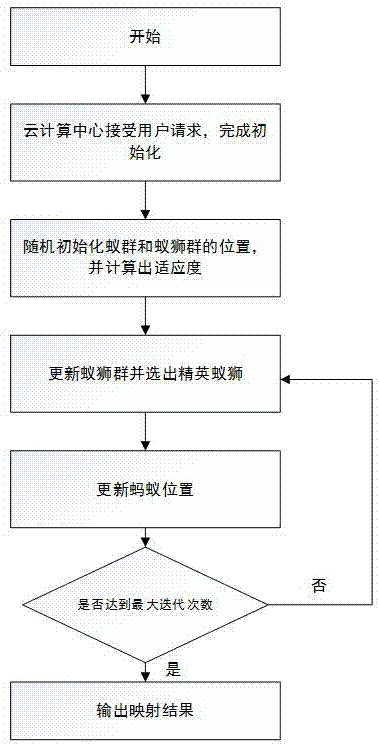
图1是本发明的方法流程图。
具体实施方式
下面结合附图和具体的实施方式对本发明作进一步详细的说明。所述实施例的示例在附图中示出,在下述本发明的实施方式中描述的具体的实施例仅作为本发明的具体实施方式的示例性说明,旨在用于解释本发明,而不构成为对本发明的限制。
本发明提供一种基于蚁狮优化算法的云计算任务调度方法,主要解决云计算任务分配的np-hard问题,如图1所示,主要包括以下步骤:
s1、根据用户提交的任务,确定任务的参数以及适应度函数的权值α;
s2、根据s1中的所述参数,初始化蚁狮算法中蚂蚁和蚁狮的位置;
s3、根据s1中的所述权值α建立适应度函数,通过任务与虚拟机的映射关系计算出适应度结果;根据蚂蚁的坐标使用适应度函数计算出每只蚂蚁的适应度,若蚂蚁的适应度函数小于蚁狮的适应度函数,则更新蚁狮的位置,同时选出适应度最小的蚁狮作为精英蚁狮;
s4、根据每只蚂蚁的适应度函数结果,使用轮盘法选择对应的蚁狮,蚂蚁的新位置由选择的蚁狮和唯一的精英蚁狮通过随机游走获得;
s5、更新蚂蚁位置后,再次使用适应度函数计算蚂蚁和蚁狮的适应函数值;
s6、判断是否大于最大迭代次数;若是,则输出精英蚁狮的位置,由任务与虚拟机的映射关系表得到最终的任务分配方案;若否,则返回步骤s4。
由于蚁狮算法具有全局优化、调节参数少、收敛精度高和鲁棒性好的优点,以及可以避免陷入局部最优解的特点;本发明基于蚁狮优化算法,通过带有随机性地迭代优选来搜索最优解,且搜索最优解的过程中,使用正反馈动态参数,提高了收敛速度。
假设有n个任务,m台虚拟机(计算节点),m≤n,有k个搜索代理,即使用k只蚁狮和1只精英蚁狮来对任务调度的结果进行迭代搜索。算法与云计算任务的映射关系为:每只蚂蚁的搜索坐标是n维,分别代表着n个任务对应的映射虚拟机节点,即每个坐标都对应着一种任务调度解。基于以上提出的数据结构和算法流程,具体操作如下:
步骤s1中,用户提交任务后将n个任务和m台虚拟机之间的关系被抽象成矩阵mtask和mnet,分别为:
其中:mtask中ti,j表示第i个虚拟机、第j个任务的长度,单位是百万条指令(mi);mnet中ni,j表示对第i台虚拟机,接收和提交第j个任务在网络上消耗的时间,单位是秒(s)。适应度函数的权值α∈(0,1)是qos的权重,α∈(0,1),用户的任务时效性要求越高,则α越大。
步骤s2中,初始化参数,种群数量(搜索代理)为k,则蚂蚁的位置表示为mant,蚁狮的位置表示为
其中:ai,j和ali,j初始化为ai,j,ali,j=random*m,其中random是在[0,1)上随机均匀分布的随机值。
步骤s3中,适应度函数表示为:
fitnessk=α(spantime)+(1-α)cost;(5)
spantime表示时间跨度,cost表示功耗消耗,其由(1)式和(2)式通过计算得到:
spantime=max(timei);(7)
cost=(prun-pfree)∑timei+pfree*spantime*m;(8)
其中:ci表示第i台虚拟机的计算能力,单位是mips;prun代表虚拟机满负荷运行时的功耗,pfree代表虚拟机待机时的功耗。
蚂蚁和蚁狮的适应度函数矩阵由蚂蚁和蚁狮的坐标所决定:
步骤s4中,根据mantlionfitness的结果获得轮盘法所需数据mwheel,其对应关系是:
第i只蚂蚁选择蚁狮的过程表示为:
selectantlioni=random*mwheel[k];(12)
其中:random是在[0,1)上随机均匀分布的随机值。
选择第一个大于selectantlioni的mwheel[j],则j为选择的蚁狮。
随机游走表示为:
经过t次迭代后,由(14)可得随机游走中的最大值为randomwalkmax、最小值randomwalkmin和当前randomwalk(t),由这三个值可以归一化计算得到第t次的随机步长:
lbit和ubit表示第t次迭代的搜索边界,其表示为:
(16)、(17)式中ub和lb是整个搜索的边界,本发明中指每个任务对应的虚拟机索引值的取值范围,即lb=0,ub=m-1;权值i是根据本次迭代的适应度函数值正反馈变化的,表示为:
式中:w表示该位置的自适应度函数的正反馈调节权值,t为此次迭代的次数,t为最大迭代次数。ffcfs表示一种基于先到先服务计算得到评价函数值,用以作为评价值基准。
本次迭代中,更新后蚂蚁的位置是:
在(20)式中,rantt表示第t次迭代中蚂蚁的坐标,
本发明提供的基于蚁狮优化算法的云计算任务调度方法,适用于云数据中心的任务调度,在收到用户任务后首先确定本次服务类型,确定评价函数即可确定出适应度函数,通过计算可以得到一种映射结果;根据映射结果,将任务分配到对应的虚拟机上进行处理;在这种分配模式下,可以调和用户与服务提供商之间的冲突,服从于适应度函数的取优。
本发明考虑了用户对于云任务时效性需求的不同,通过设置自适应度函数的权值调节评价倾向,因为迭代搜索最优解的评价过程严格按照自适应度函数值来评价,所以可以在保证用户体验的前提下降低服务提供商的成本;本发明通过带有随机性的全局搜索和迭代过程中的正反馈调节搜索范围,可以精确调节虚拟机群在本次任务计算中的搜索解,避免出现资源利用率低、节点过载的情况。
本发明中使用可自定义的适应度函数作为评价性能的标准,其包括了对于用户满意度和功耗成本两个方面的评估;同时使用带有随机性的搜索解来避免陷入局部最优解,迭代过程中用评价值相关的正反馈来缩减搜索范围,提高搜索精度。
应该注意的是,上述实施例是对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,单词“包含”不排除存在未列在权利要求中的数据或步骤。
- 还没有人留言评论。精彩留言会获得点赞!