一种策略规则对话推进以及意向判别方法及系统与流程
本发明涉及人工智能技术领域,尤其涉及一种策略规则对话推进以及意向判别方法及系统。
背景技术:
人机对话系统是一种基于自然语言的人机交互系统,通过对话系统,用户可以使用神经网络对话生成模型在多轮对话过程中完成特定的任务。人机对话系统提供了一种更自然更便捷的人机交互方式,应用前景广泛。
其中,策略规则是策略系统的基础模块,它把一系列行为和条件进行捆绑,其中,评估条件以决定是否执行行为。
现有的人机对话系统中,神经网络对话生成模型在多轮对话过程中存在容易产生万能回复以及多轮对话没有考虑整体走向之类的问题,使得人机交互存在不自然、不连贯、用户体验差等特点。
技术实现要素:
本发明的目的在于提供一种策略规则对话推进以及意向判别方法及系统,旨在解决现有人机对话系统中基于人机多轮对话的对话模型絮乱,无法预测对话走向及判别用户意向的问题。
为实现上述目的,本发明的技术方案如下:
一种策略规则对话推进以及意向判别方法,包括以下步骤:
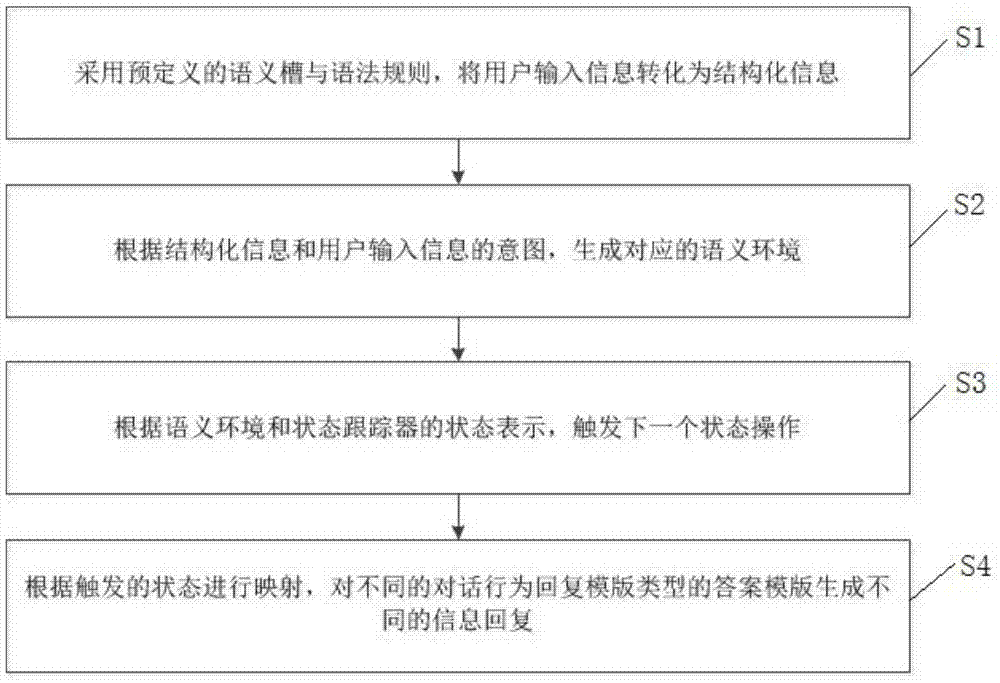
s1,采用预定义的语义槽与语法规则,将用户输入信息转化为结构化信息;
s2,根据结构化信息和用户输入信息的意图,生成对应的语义环境;
s3,根据语义环境和状态跟踪器的状态表示,触发下一个状态操作;
s4,根据触发的状态进行映射,对不同的对话行为回复模版的答案模版生成不同的信息回复。
上述方案中,所述步骤s2具体包括:
根据结构化信息与当前用户输入信息的意图相结合,对当前对话状态下每一句回复进行评估,通过后台建立的语义环境数据库检索,多轮对话建模,最终选择出概率最高的状态作为下一步的语义环境。
上述方案中,所述步骤s3具体包括:
根据语义环境和状态跟踪器的状态表示,利用监督学习的算法,通过数据挖掘双方对话信息,针对相应的学习规则触发操作,选择合适的对话行为回复模版。
上述方案中,所述步骤s4具体包括:
根据触发的状态进行映射,利用深度学习的算法,结合结构化信息和对话行为回复模版的答案模版,同时,将用户输入信息利用注意力机制处理解码器解码状态的关键信息进行匹配,选择出最合适的信息回复。
一种策略规则对话推进以及意向判别系统,该系统包括:
自然语言理解模块,通过语言理解技术解析为预定义的语义槽与语法规则,将用户输入信息转化为结构化的信息;
用户意图选择模块,根据结构化的信息,预估用户输入信息的意图目标,选择合适的语义环境;
规则触发模块,根据当前的语义环境,选择合适的对话行为回复模版类型;
答案生成模块,将对话行为回复模版类型的答案模版与结构化信息相结合,生成最合适的信息回复。
本发明的策略规则对话推进以及意向判别方法及系统,能够预先定义语义槽,针对不同的对话内容,检索后台数据库,生成语义环境,并根据相应的规则触发操作,策略推进与用户的多轮对话,从对话中判别用户的意向,系统在对话过程中不断根据当前状态决定下一步应该采取的最优动作,如:提供结果,询问特定限制条件,澄清或确认需求,从而最有效的辅助用户完成信息或服务获取的任务。
附图说明
图1是本发明一个实施例的策略规则对话推进以及意向判别方法的流程图;
图2是本发明一个实施例的策略规则对话推进以及意向判别系统的结构示意图。
具体实施方式
下面结合附图和实施例对本发明的技术方案做进一步的详细说明。
如图1所示,本发明的一种策略规则对话推进以及意向判别方法,包括:
s1,根据用户输入结果,采用语言理解技术解析为预定义的语义槽与语法规则,将用户输入信息转化为结构化信息,同时根据用户输入信息检测用户意图目标。
其中,自然语言理解后需要使用一种语义来表示,语义表示主要有三种方式,分布语义、框架语义和模型论语义,语义槽根据不同的场景预先定义,典型的有两种表示类型,一种是话语层次类别,如用户的意图和话语类别,另一种是字级信息提取,如命名实体识别和槽填充。检测用户意图目标是为了将话语分化为一个预先定义的意图。
举例而言,假设用户输入信息为“我想要预定从北京到南京的飞机”,根据预定义的语义槽与语法规则,将用户输入信息转化为结构化信息为(from:北京,to:南京,intent:预定机票)。
s2,根据结构化信息和用户输入信息的意图,生成对应的语义环境。
通常,结合结构化信息和用户意图目标,进行对话状态跟踪,对当前对话状态下每一句回复进行评估,检索后台建立的语义环境数据库,实现多轮对话建模,生成对应的语义环境。其中语义环境数据库为语义环境的集合。
举例而言,假设用户输入信息为“我想要预定从北京到南京的飞机”,将用户输入信息转化为结构化信息为(from:北京,to:南京,intent:预定机票),生成语义环境为:第一句“确定用户预订时间”,第二句“确定搜索内容”。
s3,根据语义环境和状态跟踪器的状态表示,利用监督学习的算法,通过数据挖掘双方对话信息,针对相应的学习规则触发操作,选择合适的对话行为回复模版类型。
其中,状态跟踪器是一种预设的状态集合。例如(from:北京,to:南京)为一个状态跟踪器,根据监督学习算法,挖掘出对话信息缺乏时间信息,针对相应的规则触发下一个状态为获取时间。
举例而言,假设用户输入信息为“我想要预定从北京到南京的飞机”,将用户输入信息转化为结构化信息为(from:北京,to:南京,intent:预定机票),生成语义环境为:第一句“确定用户预订时间”,第二句“确定搜索内容”。根据当前的语义环境,根据监督学习算法挖掘出对话缺乏时间信息,得到对话行为回复模版类型为“问时间”模版和“搜索结果”模版。
用户再次输入信息为“周二早上”,再次根据预定义的语义槽和语法规则,转化成结构化信息为(time:周二早上)。
s4,根据触发的状态操作进行映射,对不同的对话行为回复模版的答案模版生成不同的信息回复。
根据触发的操作进行映射,利用深度学习的算法,结合结构化信息和对话行为回复模版,同时,将用户输入信息利用注意力机制处理解码器解码状态的关键信息进行匹配,选择出最合适的信息回复。
根据对话行为回复模版类型为“问时间”模版的结果为(time:周二早上)以及历史结构化信息(from:北京,to:南京,intent:预定机票),提取最合适的信息回复为“正在为你搜索周二早上从北京到南京的飞机”。
通常,答案生成模块通常依赖于几个因素,如适当性、流畅性、可读性和变化性。传统的nlg方法通常是执行句子计划,它将输入语义符号映射到代表话语的中介形式,如树状或模版结构,然后通过表面实现将中间结构转换为最终响应。深度学习比较成熟的方法是基于lstm的encoder-decoder形式,将问题信息、语义槽和对话行为回复模版类型结合起来生成正确的答案。同时利用了注意力机制来处理对解码器解码当前状态的关键信息,根据不同的行为类型回复模版类型生成不同的回复。
一种策略规则对话推进以及意向判别系统,如图2所示,包括自然语言理解模块、用户意图选择模块、规则触发模块和答案生成模块。
其中,自然语言理解模块,根据用户输入结果,采用语言理解技术解析为预定义的语义槽与语法规则,将用户输入信息转化为结构化信息,同时根据用户输入信息检测用户意图目标。
用户意图选择模块,结合结构化信息和用户意图目标,进行对话状态跟踪,对当前对话状态下每一句回复进行评估,检索后台建立的语义环境数据库,实现多轮对话建模,生成对应的语义环境。其中语义环境数据库为语义环境的集合。
规则触发模块,根据语义环境和状态跟踪器的状态表示,利用监督学习的算法,通过数据挖掘双方对话信息,针对相应的学习规则触发操作,选择合适的对话行为回复模版类型。其中,状态跟踪器是一种预设的状态集合。
答案生成模块,将对话行为回复模版类型与结构化信息相结合,生成最合适的信息回复。
举例而言:
user:我想要预定从北京到南京的飞机。bot:需要什么时间的?
user:周二早上。bot:正在为你搜索周二早上从北京到南京的飞机。
自然语言理解模块用于将用户输入信息“我想要预定从北京到南京的飞机”转换为结构化信息(from:北京,to:南京,intent:预定机票)。
用户意图选择模块根据结构化信息(from:北京,to:南京,intent:预定机票)与用户输入信息的意图目标,选择合适的语义环境,选择出状态为(确定用户预订时间)和(确定搜索内容)。
规则触发模块根据当前的语义环境,选择合适的对话行为回复模版类型,例如“问时间”模版和“搜索结果”的模版。
用户再次输入信息为“周二早上”,再次根据自然语言理解模块,转化成结构化信息为(time:周二早上)。
答案生成模块,将对话行为回复模版类型的回复结果与历史结构化信息相结合,生成最合适的信息回复,“正在为你搜索周二早上从北京到南京的飞机”。
本发明的策略规则对话推进以及意向判别方法及系统,能够预先定义语义槽,针对不同的对话内容,检索后台数据库,生成语义环境,并根据相应的规则触发操作,策略推进与用户的多轮对话,从对话中判别用户的意向,系统在对话过程中不断根据当前状态决定下一步应该采取的最优动作,如:提供结果,询问特定限制条件,澄清或确认需求,从而最有效的辅助用户完成信息或服务获取的任务。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!