一种基于注意力机制的显著物体检测方法与流程
本发明涉及计算机视觉与数字图像处理领域,具体涉及一种基于注意力机制的显著物体检测方法。
背景技术
显著物体检测是计算机视觉领域的一个热门研究课题,其目的是提取图像中吸引人注意的物体或区域,并为其赋予显著性值。作为一个预处理步骤,它可以应用于其他高层视觉任务,如弱监督语义分割、物体识别等。传统的显著物体检测方法都是基于人工设计的特征,如对比度、背景中心差异等,这些手工设计的低层视觉特征难以捕获语义信息,因而在复杂场景中效果不佳。近年来,得益于深度学习的飞速发展,显著物体检测的性能已经取得了大幅地提升。然而,现有的显著物体检测模型都是基于图像分类模型微调,由于两者任务的差异性,图像分类网络学习得到的特征无法精确定位物体边界,直接将其用于显著物体检测无法得到高分辨率的显著性图,特别是在物体边界处。另外,为了能够检测多尺度的显著物体,通常需要将不同尺度的卷积特征进行融合,然而现有的特征融合方法只是简单地相加或合并,容易弱化残差特征,从而影响小显著物体检测。
技术实现要素:
为了克服以上弊端,本发明提供了一种基于注意力机制的显著物体检测方法,首先设计自顶向下的注意力网络用于提纯各层卷积特征,然后引入二阶项设计残差特征融合网络以更好地保留残差特征;
实现以任意的静态彩色图像为输入,其输出是与输入图像大小一致的显著性图,显著性图中白色表示显著物体区域,黑色表示背景区域。
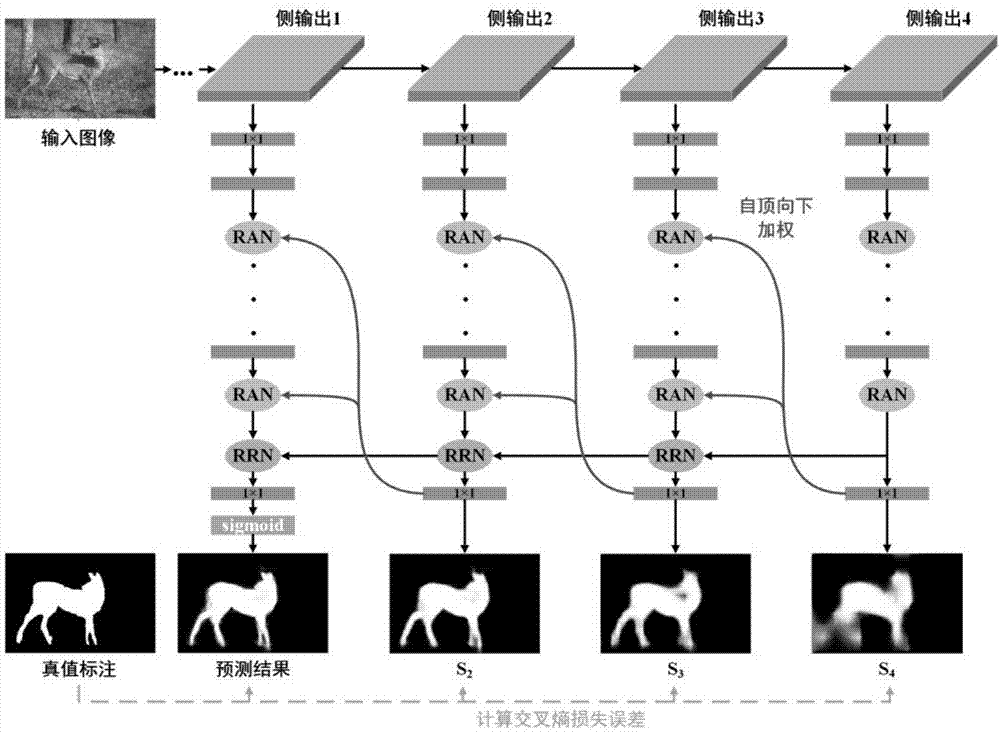
本发明的技术方案为:包括如下步骤:
s1、以vgg-16作为预训练模型,选取四个侧输出特征(conv3_3,conv4_3,con5_3,pool5),分别记为侧输出1~4;侧输出1~4后各增加一个卷积层,卷积层的参数为{1×1×256},卷积层后的输出分别记为f1~f4;
s2、在f4后增加四个卷积层,前三个卷积层的参数为{9×9×256},每个卷积层后都附有一个非线性激活层,最后一个卷积层的参数为{1×1×1},得到侧输出4的显著性概率图s4;
s3、在f1~f3后分别增加三个注意力模块,用于提纯卷积特征,每个注意力模块的输出作为下一个注意力模块的输入,最后一个注意力模块提纯后的卷积特征分别记为a1~a3;
s4、在a1~a3后分别增加一个残差特征融合模块,用于融合不同侧输出的卷积特征,融合后的特征分别记为r1~r3;
s5、在r1~r3后分别增加一个卷积层,卷积层的参数为{1×1×1},分别得到侧输出1~3的显著性概率图s1~s3;
s6、模型训练:将待检测图像输入至构建后的网络模型,得到不同分辨率的显著性概率图s4~s1,将显著性概率图s4~s1上采样至原图像大小得到显著性概率图
其中,i(z)和g(z)分别表示输入图像和真值标注图在坐标z处的像素值,|i|表示图像总的像素数目,pr(g(z)=1|i(z))表示预测为显著物体的概率;
s7、模型检测:将待检测图像直接输入到训练后的网络模型中预测其对应的显著性概率图,并将预测的显著性概率图
步骤s3包括以下步骤:
s3.1、采用反卷积层分别将显著性概率图s4~s2上采样两倍,作为侧输出3~1的特征权值图,记为w3~w1;
s3.2、定义如下注意力模块:该模块有两个输入,一个是卷积特征,另一个是权值图,输出是加权后的特征,通过下式计算:
其中,f和a分别表示注意力模块的输入和加权后特征,w表示权值图,c为特征的通道索引,取值1~256,i为侧输出索引,取值1~3,j为注意力模块索引,取值1~3;
s3.3、在每个注意力模块加权得到的特征后再增加一个卷积层,每个卷积层后都附有一个非线性激活层,侧输出3中的卷积层的参数为{7×7×256},侧输出2中的卷积层的参数为{5×5×256},侧输出1中的卷积层的参数为{3×3×256}。
步骤s4中的残差特征融合模块为:
该模块以相邻两个侧输出的卷积特征为输入,输出是融合后的特征,在侧输出3中通过下式计算:
在侧输出1和2中通过下式计算:
其中r为融合后的特征,i为侧输出索引,取值1~2。
本发明与现有技术相比,具有以下优点:
1)本发明设计了一种基于注意力机制的特征提纯网络,通过自顶向下特征加权可以有效滤除背景区域的干扰,从而提升显著物体检测的准确性;
2)本发明设计了一种残差特征融合网络,通过引入二阶项滤除两者的共同特征,引导网络更好地学习残差特征(物体细节部分),最终可以得到高分辨率的显著性图。
基于以上两个网络,本发明可以得到高分辨率的显著性图,同时能够较好地检测小显著物体。
附图说明
图1为本发明方法的总体流程图;
图2为本发明的注意力加权模块示意图(图1中的ran);
图3为本发明的残差特征融合网络示意图(图1中的rrn);
图4为本发明的显著性检测结果示例,第一行为输入图像,第二行为显著性检测结果;
具体实施方式
下面结合附图对本发明的技术方案作进一步的详细说明:
本发明如图1-4所示,包括如下步骤:
s1、以vgg-16作为预训练模型,选取四个侧输出特征(conv3_3,conv4_3,con5_3,pool5),分别记为侧输出1~4;侧输出1~4后各增加一个卷积层,卷积层的参数为{1×1×256},卷积层后的输出分别记为f1~f4;该卷积层将各个侧输出特征的通道数降为256,一是降低通道冗余,二是便于后续的特征相加;本发明中卷积层的参数为{k×k×c},k表示卷积核大小,c表示卷积通道数;
s2、在f4后增加四个卷积层,前三个卷积层的参数为{9×9×256},用于学习显著性语义特征,每个卷积层后都附有一个非线性激活层relu,用以去除小于零的特征响应值,最后一个卷积层的参数为{1×1×1},用于降低卷积通道数,得到侧输出4的显著性概率图s4;
s3、在f1~f3后分别增加三个注意力模块,用于提纯卷积特征,每个注意力模块的输出作为下一个注意力模块的输入,最后一个注意力模块提纯后的卷积特征分别记为a1~a3;
s4、在a1~a3后分别增加一个残差特征融合模块,用于融合不同侧输出的卷积特征,融合后的特征分别记为r1~r3;
s5、在r1~r3后分别增加一个卷积层,卷积层的参数为{1×1×1},分别得到侧输出1~3的显著性概率图s1~s3;
s6、模型训练:将待检测图像输入至构建后的网络模型,得到不同分辨率的显著性概率图s4~s1,将显著性概率图s4~s1上采样至原图像大小得到显著性概率图
其中,i(z)和g(z)分别表示输入图像和真值标注图在坐标z处的像素值,|i|表示图像总的像素数目,pr(g(z)=1|i(z))表示预测为显著物体的概率;pr(g(z)=0|i(z))表示预测为非显著物体的概率;l表示损失函数;
公式中,对图像中的每一个像素位置分别计算g(z)logpr(g(z)=1|i(z))和(1-g(z))logpr(g(z)=0|i(z)),当模型预测非常准确时,显著性概率和非显著性概率均为1,则两个对数结果均为0,此时损失函数值为0。
步骤s6中,给定输入图像和标注图像,通过不断迭代更新网络权值使得损失函数值不断减小,直至收敛得到最终的网络模型。
s7、模型检测:将待检测图像直接输入到训练后的网络模型中预测其对应的显著性概率图,并将预测的显著性概率图
步骤s7中,预测得到的显著性概率图中s1的分辨率最高,检测效果最好,通过sigmoid层还可以加大显著物体和背景的对比度,所以将其输出作为最终的检测结果。
步骤s3包括以下步骤:
s3.1、采用反卷积层分别将显著性概率图s4~s2上采样两倍,作为侧输出3~1的特征权值图,记为w3~w1;
s3.2、定义如下注意力模块:该模块有两个输入,一个是卷积特征,另一个是权值图,输出是加权后的特征,通过下式计算:
其中,f和a分别表示注意力模块的输入和加权后特征,w表示权值图,c为特征的通道索引,取值1~256,i为侧输出索引,取值1~3,j为注意力模块索引,取值1~3;
s3.3、在每个注意力模块加权得到的特征后再增加一个卷积层,每个卷积层后都附有一个非线性激活层relu,侧输出3中的卷积层的参数为{7×7×256},侧输出2中的卷积层的参数为{5×5×256},侧输出1中的卷积层的参数为{3×3×256},不同的卷积核大小用于捕获不同尺度的显著性特征。
步骤s4中的残差特征融合模块为:
该模块以相邻两个侧输出的卷积特征为输入,输出是融合后的特征,在侧输出3中通过下式计算:
在侧输出1和2中通过下式计算:
其中r为融合后的特征,i为侧输出索引,取值1~2。
具体应用中:
一、基于注意力机制的特征提纯网络
(1)以vgg-16net作为预训练模型,移除vgg-16中“pool5”后的网络层,然后选取“conv3_3”、“conv4_3”、“conv5_3”、“pool5”作为侧输出特征,分别记为侧输出1~4。为了保证各侧输出特征通道数一致,其后各增加一个1×1卷积核的卷积层(记为conv),将通道数(channel)降低为256。
(2)在“pool5”的1×1卷积后增加三个9×9卷积核的卷积层,通道数皆为256,用于特征学习,再通过一个1×1卷积核的卷积层得到通道数为1的侧输出4显著性概率图s4。
(3)在“conv5_3”的1×1卷积后增加一个7×7卷积核的卷积层,通道数为256,用于特征学习,学习得到的特征记为f3,1。
(4)采用反卷积层(记为deconv)将全局显著性概率图s4上采样两倍至“conv5_3”大小,作为侧输出3的特征权值图,记为w3。
(5)定义如下注意力模块:该模块有两个输入,一个是卷积特征,另一个是权值图,输出是加权后的特征,通过下式计算:
其中,f和a分别表示注意力模块的输入和加权后特征,w表示权值图,c为特征的通道索引,取值1~256,i为侧输出索引,取值1~3,j为注意力模块索引,取值1~3;
(6)在f3,1后增加一个注意力模块,以f3,1和w3为输入,得到提纯后的特征,紧接着再增加一个7×7卷积核的卷积层,通道数为256,用于特征学习,学习得到的特征记为f3,2,再以此为输入,经过一个注意力模块最后得到特征f3,3。最后通过一个1×1卷积核的卷积层得到通道数为1的侧输出3显著性概率图s3。
(7)同理,与侧输出4相似,侧输出3的显著性图上采样用于侧输出2加权,再把侧输出2的显著性图上采样用于侧输出1加权。在侧输出1和2中也分别叠加三个注意力模块,最后得到显著性概率图s1和s2。
二、残差特征融合网络
为了能够融合多尺度卷积特征,提升显著性图的分辨率,在各个侧输出最后的1×1卷积层前增加一个残差特征融合模块。该模块以相邻两个侧输出的卷积特征为输入,输出是融合后的特征,在侧输出3中通过下式计算:
在侧输出1和2中通过下式计算:
其中r为融合后的特征,i为侧输出索引(取值1~2)。
- 还没有人留言评论。精彩留言会获得点赞!