支持高并发的分布式内存计算集群系统的制作方法
本发明涉及一种软件工程、大数据以及分布式存储和计算等领域,尤其涉及一种支持高并发的分布式内存计算集群系统。
背景技术:
随着计算机硬件和大数据技术的发展,在这个信息爆炸的时代,人们渴望从海量数据中快速地统计和获取有价值的信息,这些信息对于企业的发展以及人们的生活有着重要的决策和参考作用。
目前可行性技术方案总结如下:使用hadoop或spark技术,例如,使用hdfs/habse作为数据存储引擎,使用map/reduce或spark技术作为离线数据分析引擎,使kafka、spark-streaming或storm作为实时数据分析引擎。
虽然上述技术方案也能对数据进行分析计算,但是个人认为仍然有存在一些不足,现总结如下:
a)“框架消耗”现象普遍存在。不少大数据技术框架为了达到“综合性”和“共性”,对于一些用之甚少、较难实现而又必须要有的功能,往往采取一些“折中”的办法来实现它们,这在一定程度上牺牲了框架“整体性能”。使用“二八定律”很容易理解,即使用率较高的百分之八十的功能的运作只需要占用百分之二十的资源,而使用率较低的百分之二十的算法却占用着高达百分之八十的资源。为了满足了“综合性”而削弱了“专业性”。这明显不能满足一些并发性和性能要求较高的需求。
b)存在“数据加载”消耗现象。一般大数据分析引擎完成一次请求需要:①加载数据②分析③保存或返回结果这三个环节,而加载数据环节往往是最耗时的,一般需要建立连接、检索数据、传输数据这三个步骤,每个步骤都需要消耗一定的时间,特别是检索数据和传输数据环节,对于数据量比较大的请求,光“加载数据”就要耗费10s加的时间,这还未考虑非并发数据或并发数不足的情况。
c)请求“预分析”不足。对于像spark这样的大数据分析引擎,当多个并发请求同时到达时,采取的是“不拒绝”方案。即不管目前集群的资源消耗如何,也不管当下有多少个作业正在运行,spark都会给请求分配资源,甚至“抢”占正在运行作业的资源,导致前面运行的所有作业进度变慢,更严重的情况是造成系统瘫痪,即作业之间因为发生资源“抢占”而死锁的现象。
d)非“纯内存”。虽然曾经一度因为spark内存计算而取代map/reduce而轰动整个大数据界,然而spark并非纯内存运作,许多中间结果仍然要保存为文件的形式,特别是发生shuffle的时候,即数据需要跨网络传输的时候,中间结果数据一般都会因为内存不足或多或少地保存为文件的形式,有的甚至还要压缩保存,这在一定程度上降低了系统的性能。
技术实现要素:
本发明提供一种支持高并发的分布式内存计算集群系统,有效降低“框架消耗”,并能实现数据预加载、请求预分析及纯内存操作。
为实现上述目的,本申请实施例提供了如下技术方案:
一种支持高并发的分布式内存计算集群系统,包括:master节点、多个node节点、集群管理部件和数据库;
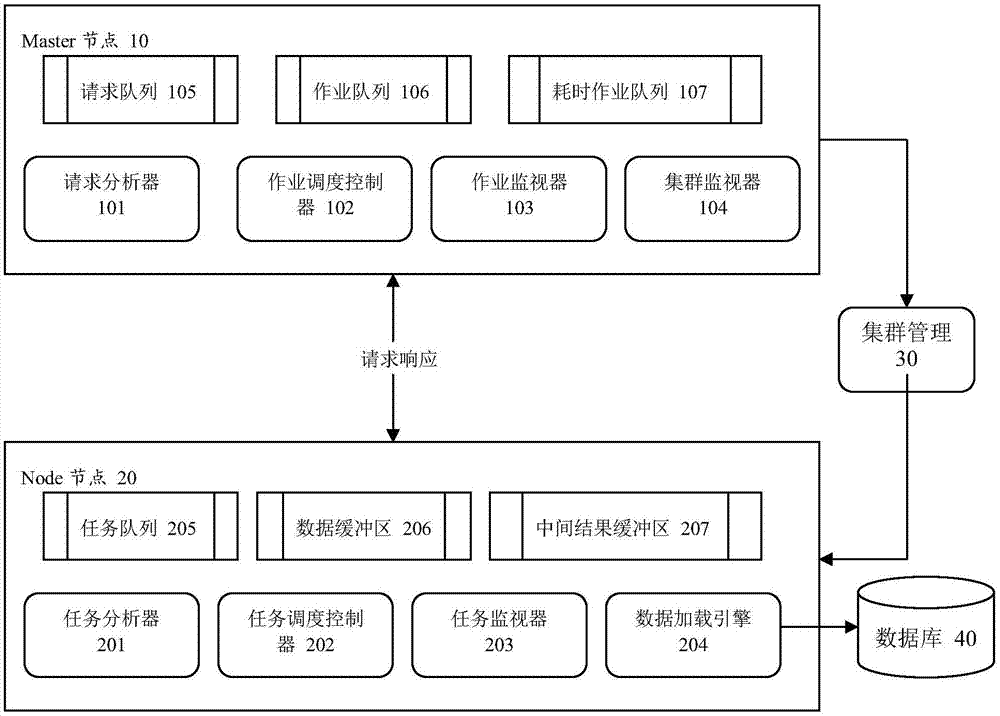
所述master节点,用于接收请求,预分析请求,分配和调度作业、集群监控、收集和返回分析结果,所述master节点具体包括请求分析器、作业调度控制器、作业监视器、集群监视器、请求队列、作业队列和耗时作业队列,其中:
所述请求分析器,用于从请求队列中获取请求,对所述请求进行分析以判断该请求是否为耗时请求,如为非耗时请求则存入作业队列,如为耗时请求则存入耗时作业队列,
所述作业调度控制器,用于定时检查作业队列,当请求分析器分析完请求后,交由作业调度控制器,若作业队列不空,则先处理该作业队列所有作业,否则,检查耗时作业队列,若不空,则从该耗时作业队列里取出一个作业投放运作,
所述作业监视器,用于监视投放运作的每一个作业,当有作业发生异常、完成情况,则立即通知作业调度控制器准备其他作业的投放运作;
所述集群监视器,用于结合集群管理部件随时监控集群的健康状态,集群的各方面的负载;所述node节点包括任务分析器、任务调度控制器、任务监视器、数据加载引擎、任务队列、数据缓冲区和中间结果缓冲区,其中:
所述任务分析器,用于分析由master节点下发的作业的参数和条件,产生一系列任务存放于任务队列里,
所述任务调度控制器,根据情况从任务队列取出任务执行,任务调度控制器维护了一个执行任务的线程池,每个任务对应一个执行线程,线程会根据任务的条件从数据缓冲区或中间结果缓冲区中检索数据进行分析,
所述任务监视器,用于监视正在运行的每一个任务,一旦有任务发生异常、完成情况,立即通知任务调度控制器准备其他任务的执行;
所述数据加载引擎,用于根据分片规则在系统启动或发生扩缩容的时候从数据库加载数据到数据缓冲区;
所述任务队列,每个作业会分配若干个任务,分散到各个node节点执行,这些任务由任务分析器产生,并以fifo方式存放在任务队列里面,
所述数据缓冲区,用于存放分析数据的数据结构,
所述中间结果缓冲区,用于暂存最小运行单位的任务的产出;
所述集群管理部件,用于监控和维护整个集群的健康状态;
所述数据库,用于储存历史分片数据和实时数据。优选的,所述请求分析器对所述请求进行分析时,相关的分析因素为数据量,时间跨度,算法难易程度。
优选的,每个因素可以根据需要设置加权参数。
优选的,所述数据分为历史分片数据和实时数据。
优选的,所述历史分片数据一天加载一次,而实时数据根据情况可加载或不加载,每天产生数据量在100w以上时加载。
优选的,所述请求队列按照fifo的方式存放分析请求。
优选的,所述作业队列按照fifo方式存放的非耗时的作业。
优选的,所述耗时作业队列按照fifo方式存放的耗时的作业。
优选的,所述任务分析器产生的任务以批次的形式产生,每个任务仅属于某一批次,批次靠前的先执行,靠后的后执行,每一批次的任务执行的前提条件是前一批次任务执行完毕。
优选的,所述集群管理部件主要用于监控和维护整个集群的健康状态具体为:每个node节点在系统启动时以服务的形式向集群管理部件注册自己,并提供健康检查的方式,集群管理部件定时通过这种方式回访每个node节点,如果回访成功,则表示该node节点是健康的,更新并记录下来;master节点中的集群监视器定时向集群管理部件获取这些状态,以判断整个集群是否健康运行。
根据上述技术方案可知,本发明至少具有如下技术效果或优点:
1.专注。专注离线分析,即席分析,不会显得鱼龙混杂。
2.高并发。数据预先加载到了“内存”之中,提供分区和索引两种检索方式并存的方法,加快了数据存取速率,降低了单个请求的资源消耗,而且各个请求之间的资源完全隔离,真正做到了多并发和高并发。
3.高性能。尽量map,本地合并,本地计算,减少shuffle次数,减少shuffle数据量,让每个node的使用发挥到极致,真正做到分布式并发计算。
4.轻量。由于框架功能实现比较单一,只提供离线数据的“即席分析”功能,而且内部结构是优化的,各个组件之间有机结合,因此整体框架显得非常轻量。
附图说明
图1为表示本发明实施例的流程示意图;
具体实施方式
本申请实施例提供了一种支持高并发的分布式内存计算集群系统,能够有效降低“框架消耗”,并能实现数据预加载、请求预分析及纯内存操作。
为使得本申请实施例的发明目的、特征、优点能够更加的明显和易懂,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本申请实施例一部分实施例,而非全部的实施例。基于本申请实施例中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请实施例保护的范围。
请参阅图1,本申请实施例提供的一种支持高并发的分布式内存计算集群系统的实施例包括:
如图1所示,一种支持高并发的分布式内存计算集群系统,包括:master节点10、多个node节点20、集群管理30和数据库40。
master节点10,用于接收请求,预分析请求,分配和调度作业、集群监控、收集和返回分析结果等。master节点包括请求分析器101、作业调度控制器102、作业监视器103、集群监视器104、请求队列105、作业队列106和耗时作业队列107。
请求分析器101用于从请求队列里面获取一个请求,按照预先的一些配置或者经验(例如机器学习)对请求进行分析,以判断该请求是否是耗时请求,如为非耗时请求则存入作业队列,如为耗时请求则存入耗时作业队列。
优选的,相关的分析因素如:数据量,时间跨度,算法难易程度等。
优选的,每个因素可以根据需要设置加权参数。
作业调度控制器102用于定时检查作业队列,当请求分析器分析完请求后,交由作业调度控制器,若队列不空,则先处理该队列所有作业,否则,检查耗时作业队列,若不空,则从该队列里取出一个作业投放运作。作业监视器103会监视投放运作的每一个作业,如作业的状态、进度等,一旦有作业发生异常、完成等情况,立即通知作业调度控制器准备其他作业的投放运作。
集群监视器104,用于结合集群管理部件随时监控集群的健康状态,集群的各方面的负载,如cpu、内存、磁盘等信息。
优选的,请求队列按照fifo的方式存放分析请求。
优选的,作业队列按照fifo方式存放的非耗时的作业。
优选的,耗时作业队列按照fifo方式存放的耗时的作业。
node节点20包括任务分析器201、任务调度控制器202、任务监视器203、数据加载引擎204、任务队列205、数据缓冲区206和中间结果缓冲区207。
任务分析器201,通过分析由master下发的作业的参数和条件,产生一系列任务存放于任务队列里。
优选的,这些任务以批次的形式产生,每个任务仅属于某一批次,批次靠前的先执行,靠后的后执行,每一批次的任务执行的前提条件是前一批次任务执行完毕。
任务调度控制器202,根据情况从任务队列取出任务执行。
任务调度控制器202维护了一个执行任务的线程池,每个任务对应一个执行线程,线程会根据任务的条件从数据缓冲区或中间结果缓冲区中检索数据进行分析。
任务监视器203监视正在运行的每一个任务,如任务的状态、进度等,一旦有任务发生异常、完成等情况,立即通知任务调度控制器202准备其他任务的执行。
数据加载引擎204主要功能是根据分片规则在系统启动或发生扩缩容的时候从数据库加载数据到数据缓冲区。
数据分为历史分片数据和实时数据,历史分片数据一天加载一次,而实时数据根据情况可加载或不加载,每天产生数据量在100w以上时加载。
数据缓冲区206和数据加载引擎204实现了数据预加载功能,如果有需要可按照常用的需求做好内存排序,这样大大提高了数据加载的效率,极大地减少了因为数据加载而产生的性能消耗。
任务队列205:每个作业会分配若干个任务,分散到各个node节点执行,这些任务由任务分析器产生,并以fifo方式存放在任务队列里面。
数据缓冲区206:用于存放分析数据的数据结构。
优选的,数据分为历史数据和实时数据,这些数据以分区的形式存在,分区的方案可以参考业务需求,一般以时间作为分区参考比较多,必要时,可以将历史数据预先以某些字段排好序,这样进一步提高了检索的效率,从而提高的并发性和性能。实时数据因为数据量较少,可以区别对待而无需排序。
中间结果缓冲区207:任务是最小的运行单位,每个任务都会有所产出,这些产出将不会以文件的形式存在,而是直接暂存于中间结果缓冲区中。这些中间结果数据要么以最终结果的形式发给master,要么以shuffle的方式发送给其他节点,异或在本地作为下一批任务的输入。
集群管理30主要用于监控和维护整个集群的健康状态。
优选的,集群管理30监控和维护整个集群的健康状态具体为:每个node节点在系统启动时以服务的形式向集群管理部件注册自己,并提供健康检查的方式,集群管理部件定时通过这种方式回访每个node节点,如果回访成功,则表示该node节点是健康的,更新并记录下来。master节点中的集群监视器定时向集群管理部件获取这些状态,以判断整个集群是否健康运行。
数据库40,用于存储历史分片数据和实时数据。
本申请实施例提供的一种支持高并发的分布式内存计算集群系统,不提供实时流功能,只提供离线分析功能,降低了“框架消耗”;通过请求分析器,实现和加强了“请求预分析”,而“数据缓冲区”和“数据加载引擎”实现了数据预加载功能,提高了数据加载效率,减少了因数据加载而产生的性能消耗。对于需要shuffle的数据,直接通过网络传输,而尽量不通过保存为文件再发送的方式,这样可大大提高系统运作的性能,实现了“纯内存”操作。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!