基于正态分布H阈值的紫色土图像分割提取方法与流程
本发明涉及图像分割提取方法,具体涉及一种基于正态分布h阈值的紫色土图像分割提取方法。
背景技术
在土壤分类中,地理分布、地形部位、土壤颜色、质地和结构是土壤分类基本特征。其中,地理分布决定土类、大的地形部位决定土属,局地的土种分布依赖于土壤颜色、质地和结构。由于表土受风吹、日晒、雨淋、土壤墒情,附着的地衣、苔藓及杂草等影响,颜色不稳定,使用心土颜色作为重要的分类依据。
现代农业的发展,随着农业自动化、传感技术等在农业上的应用,提出了在野外应用机器视觉识别土壤的要求。根据经验,土锹锹土形成自然断面没有受到铁锹、锄头等工具的破坏,完整保持了土壤自然属性,其图像也最大限度保持了土壤的自然信息。因此,心土自然断面图像成为机器视觉识别土壤的理想图像信息载体。
在野外采集心土自然断面图像,受条件的限制,一般不可能先固定一台设备拍摄背景,然后在锹出土壤自然断面采集图像,应用背景差分的方法获得土壤自然断面图像。即使能满足这样的设备条件,在锹出土壤自然断面时,需要人去操作,也会破坏背景,也无法通过简单差分获得土壤自然断面图像。常规的做法是应用便捷的手持拍摄工具拍摄。相应地,就没有单独的背景图像;从一张图像中,将土壤自然断面图像从复杂背景中分割出来成为了机器视觉识别土壤前必不可少的重要预处理工作。这种方式也方便移动设备野外在线土壤识别。
机器视觉辨识土壤是对野外自然条件下拍摄的具有复杂背景的土壤图像进行识别。在机器视觉辨识土壤中,我们只对图像的土壤部分感兴趣,如果我们能将图像的土壤部分从背景中分割出来,一方面只研究、处理我们感兴趣的图像的土壤部分,另一方面可以排除背景区域对进一步图像分析、特征提取、辨识造成干扰。紫色土是我国西南地区最主要耕地,紫色土是机器视觉土壤识别的研究重点。如何将彩色图像的紫色土图像从背景中准确、完整的分割出来是目前的技术难题。目前,已有的图像分割算法准确度低、误差大、时间开销大。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于正态分布h阈值的紫色土图像分割提取方法,充分考虑到紫色土彩色图像的土壤区域在hsv颜色空间h分量有良好的聚集特性,并与背景区域有显著差异,将紫色土彩色图像转换为hsv颜色空间,并考虑到紫色土图像的h分量均值在95%和97%置信度上呈正态分布的特性,建立正态分布h阈值计算模型,计算对图像ⅰ进行分割的阈值,将图像的土壤区域从背景区域中快速、准确、完整分割提取出来,并消除了孤立点且填充了边界点围成的内部区域,提高了分割提取紫色土图像的精度。
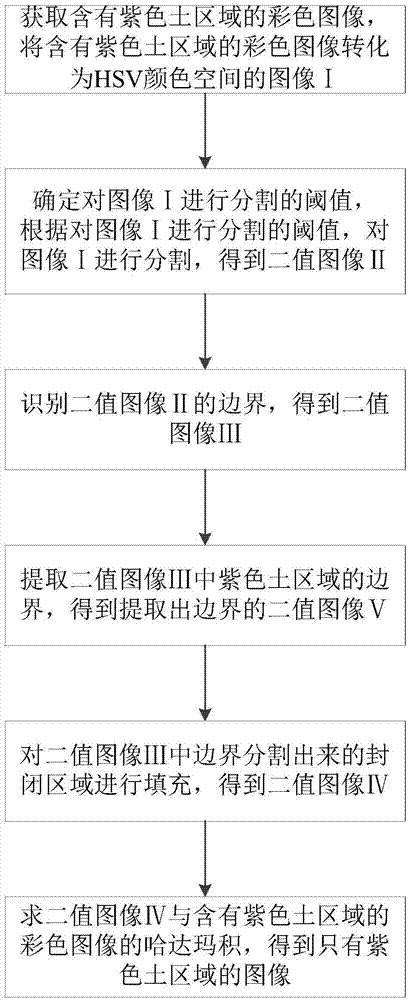
本发明提供一种基于正态分布h阈值的紫色土图像分割提取方法包括步骤:
s1:获取含有紫色土区域的彩色图像,将含有紫色土区域的彩色图像转化为hsv颜色空间的图像ⅰ;
s2:确定对图像ⅰ进行分割的阈值,根据对图像ⅰ进行分割的阈值,对图像ⅰ进行分割,得到二值图像ⅱ;
s3:识别二值图像ⅱ的边界,得到二值图像ⅲ;
s4:提取二值图像ⅲ中紫色土区域的边界,得到提取出边界的二值图像ⅴ;
s5:对二值图像ⅲ中边界分割出来的封闭区域进行填充,得到二值图像ⅳ;
s6:求二值图像ⅳ与含有紫色土区域的彩色图像的哈达玛积,得到只有紫色土区域的图像。
进一步,所述步骤s2具体包括步骤:
s201:在图像ⅰ中提取n个m×n像素的子区域,其中n≥3;
求各个子区域的h分量均值,然后根据n的取值,对m×n像素的子区域进项筛选,获取样本区域,具体筛选过程如下:
若n=3,则求两两子区域之间h分量均值的差值,将差值最小的两个子区域合并,形成一个样本区域,获得样本区域的h分量值的均值和方差;
若n>3时,则对各个子区域的h分量均值进行大小排序,剔除h分量均值最大和最小的子区域,将剩余n-2个区域合并,形成一个样本区域,获得样本区域的h分量值的均值和方差;
s202:建立正态分布h阈值计算模型,根据样本区域的h分量值的均值和方差,确定对图像ⅰ进行分割的阈值;所述对图像ⅰ进行分割的阈值包括上限阈值hupper和下限阈值hlower;
s203:将图像ⅰ转化为矩阵hi,矩阵hi中各元素值等于图像ⅰ中与各元素位置相同的像素点的h分量值,建立与矩阵hi大小一样的二值矩阵h',并将二值矩阵h'中的元素初始化为0;
s204:根据分割更新规则对二值矩阵h'进行更新,将更新后的二值矩阵h'转化为二值图像,得到二值图像ⅱ;
所述分割更新规则为:若hlower≤h(x,y)≤hupper,则置h'(x,y)=1;若h(x,y)<hlower或h(x,y)>hupper,则置h'(x,y)=0;其中h(x,y)为矩阵hi中位置为(x,y)的元素值,h'(x,y)为二值矩阵h'中位置为(x,y)的元素值。
进一步,所述步骤s202中正态分布h阈值计算模型为
hlower=μ-tα/2×σ(1)
hupper=μ+tα/2×σ(2)
其中,μ为h分量值的均值,σ为h分量值的标准差,α为非置信水平在正态分布内的覆盖面积,tα/2是t分布在置信度为1-α的分位数,hlower为对图像ⅰ进行分割的下限阈值,hupper为对图像ⅰ进行分割的上限阈值。
进一步,所述步骤s3包括步骤:
s301:将二值图像ⅱ图像转化为二值矩阵a,二值矩阵a中各元素值等于二值图像ⅱ中与各元素位置相同的像素点值;
s302:建立边界识别模板;
s303:求二值矩阵a中的各个元素的8邻域矩阵与边界识别模板的卷积,
s304:根据二值矩阵a中的元素值和卷积结果,识别背景点、孤立点和边界点,具体如下:
当二值矩阵a中的元素值为0时,则该元素为背景点;
当二值矩阵a中的元素值为1时,若卷积结果为0,则该元素对应的二值图像ⅱ中的像素点为孤立点;若卷积结果为8,则该元素对应的二值图像ⅱ中的像素点为边界内部点;若卷积结果∈[1,7],则该元素对应的二值图像ⅱ中的像素点为边界点;其中,所述边界内部点为由边界点围成封闭区域内部的点。
s305:在二值矩阵a中,将识别出的背景点、孤立点和边界内部点对应的元素置0,边界点对应的元素置1,然后将二值矩阵a变换为二值图像,得到二值图像ⅲ。
进一步,所述边界识别模板为
进一步,所述步骤s4包括步骤
s401:将二值图像ⅲ图像转化为二值矩阵b,二值矩阵b中各元素值等于二值图像ⅲ中与各元素位置相同的像素点值;
建立与二值矩阵b大小一样的遍历矩阵c,并将遍历矩阵c中的元素均初始化为0;
建立与二值矩阵b大小一样的边界矩阵d,
建立堆栈ⅰ;
确定二值矩阵b的中心点位置(xm,ym);
设定二值矩阵b中的边界点的位置中最小行号为x1,最大行号为x2,最小列号为y1,最大列号为y2;
s402:设置二值矩阵b左上角点为搜索起始点,将搜索起始点;
s403:初始化堆栈ⅰ;将边界矩阵d中的元素均初始化为0;
s404:在二值矩阵b中,跳过已搜索过的点,按照预设的搜索顺序,对二值矩阵b中的点进行搜索,判断搜索的点是否为边界点;若搜索到点为边界点,则将该边界点的行号赋值给最小行号为x1和最大行号为x2,将该边界点的列号赋值给最小列号为y1和最大列号为y2,将该边界点压入堆栈ⅰ,将边界矩阵d中与该边界点在二值矩阵b中的位置相同的点置1,将遍历矩阵c中与该边界点在二值矩阵b中的位置相同的点置1,并将该边界点作为当前遍历点,进入步骤s405;
若未搜索到边界点,则结束对紫色土区域边界的提取,将边界矩阵d转换为二值图像,得到二值图像ⅴ;
所述预设的搜索顺序为:按照从上至下的顺序搜索各行的点,且对各行内部的点进行搜索时按照从左到右的顺序进行搜索;所述判断搜索的点是否为边界点,即判断在二值矩阵b该搜索到点的值是否为1;
s405:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的右邻点值是否为1,如果为1,则进入步骤s406;
如果为0,则在二值矩阵b中判断与右邻点在遍历矩阵c中位置相同的点值是否为1,如果与右邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该右邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该右邻点在遍历矩阵c中位置相同的点,判断当前遍历点的列号值是否大于y2,如果大于y2,则y2更新为当前遍历点的列号值,返回步骤s405;如果与右邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s406;
s406:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的下邻点值是否为1,如果为1,则进入步骤s407;
如果为0,则在二值矩阵b中判断与下邻点在遍历矩阵c中位置相同的点值是否为1,如果与下邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该下邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该下邻点在遍历矩阵c中位置相同的点,判断当前遍历点的行号值是否大于x2,如果大于x2,则x2更新为当前遍历点的行号值,返回步骤s405;如果与下邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s407;
s407:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的左邻点值是否为1,如果为1,则进入步骤s408;
如果为0,则在二值矩阵b中判断与左邻点在遍历矩阵c中位置相同的点值是否为1,如果与左邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该左邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该左邻点在遍历矩阵c中位置相同的点,判断当前遍历点的列号值是否小于y1,如果大于y1,则y1更新为当前遍历点的列号值,返回步骤s405;如果与左邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s407;
s408:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的上邻点值是否为1,如果为1,则进入步骤s409;
如果为0,则在二值矩阵b中判断与上邻点在遍历矩阵c中位置相同的点值是否为1,如果与上邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该上邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该上邻点在遍历矩阵c中位置相同的点,判断当前遍历点的行号值是否小于x1,如果大于x1,则x1更新为当前遍历点的行号值,返回步骤s405;如果与上邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s409;
s409:将堆栈ⅰ的当前栈顶点出栈后,再判断堆栈ⅰ是否为空或者堆栈ⅰ的栈顶点是否是遍历起始点;
如果堆栈ⅰ不为空,且堆栈ⅰ的栈顶点不是遍历起始点,则将出栈的点作为当前遍历点,返回步骤s405;
如果堆栈ⅰ为空,或者堆栈ⅰ的栈顶点是遍历起始点,则判断x1<xm<x2且y1<ym<y2)是否成立,如果为不成立,返回步骤s403:如果成立,则结束对紫色土区域边界的提取,将边界矩阵d转换为二值图像,得到二值图像ⅴ。
进一步,所述步骤s5包括步骤
s501:将二值图像ⅴ转化为二值矩阵e,二值矩阵e中各元素值等于二值图像ⅴ中与各元素位置相同的像素点值;
s502:设定与二值矩阵e大小一样的填充矩阵f,并将填充矩阵f中的元素均初始化为0;建立并初始化堆栈ⅱ,获取填充矩阵f的中心点位置(xm,ym(,以该中心点为遍历起点,且将遍历起点作为当前遍历点;
s503:将当前遍历点压入堆栈ⅱ,
s504:在填充矩阵f中,将当前遍历点的对应元素值置1;
s505:判断填充矩阵f中当前遍历点的右邻点值是否为0,且在二值矩阵e中与该右邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该右邻点;返回步骤s503;
如果不均为0,则进入步骤s506;
s506:判断填充矩阵f中当前遍历点的下邻点值是否为0,且在二值矩阵e中与该下邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该下邻点;返回步骤s503;
如果不均为0,则进入步骤s507;
s507:判断填充矩阵f中当前遍历点的左邻点值是否为0,且在二值矩阵e中与该左邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该左邻点;返回步骤s503;
如果不均为0,则进入步骤s508;
s508:判断填充矩阵f中当前遍历点的上邻点值是否为0,且在二值矩阵e中与该上邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该上邻点;返回步骤s503;
如果不均为0,则进入步骤s509;
s509:将堆栈ⅱ的栈顶点出栈后,将堆栈ⅱ的当前栈顶点对应的填充矩阵f的点作为当前遍历点,
然后判断当前遍历点是否回到遍历起点,如果当前遍历点没有回到遍历起点,则返回步骤s503;如果当前遍历点回到遍历起点,将结束遍历,将填充矩阵f转化成二值图像,得到二值图像ⅳ。
进一步,所述中心点位置(xm,ym)的计算公式为
其中,m为二值图像ⅲ中像素点的总行数或填充矩阵f中元素的总行数;n为二值图像ⅲ中像素点的总列数或填充矩阵iv中元素的总列数,xm为中心点位置的行号,ym为中心点位置的列号;二值图像ⅲ中像素点的总行数等于填充矩阵f中元素的总行数;二值图像ⅲ中像素点的总列数等于填充矩阵f中元素的总列数。
本发明的有益效果:本发明充分考虑到紫色土彩色图像的土壤区域在hsv颜色空间h分量有良好的聚集特性,并与背景区域有显著差异,将紫色土彩色图像转换为hsv颜色空间,并考虑到紫色土图像的h分量均值在95%和97%置信度上呈正态分布的特性,建立正态分布h阈值计算模型,计算对图像ⅰ进行分割的阈值,将图像的土壤区域从背景区域中快速、准确、完整分割提取出来,并消除了孤立点且填充了边界点围成的内部区域,提高了分割提取紫色土图像的精度。
附图说明
下面结合附图和实施例对本发明作进一步描述:
图1为本发明的方法流程图;
图2为样本图像中紫色土图像的h域直方图;
图3为样本图像中紫色土图像的s域直方图;
图4为样本图像中紫色土图像的v域直方图;
图5为样本图像中紫色土图像的hsv聚集度图;
图6为样本图像中杂质和背景区域的h域直方图;
图7为样本图像中杂质和背景区的hsv聚集度图;
图8为样本图像通过本文步骤s1和步骤s2处理得到二值图像ⅱ;
图9为图8经过本文步骤s3处理后得到的二值图像ⅲ;、
图10为图8经过形态学边界识别处理后得到的二值图像;
图11为图10比图9多出来的孤立点的图像;
图12为当前遍历点四连通域的遍历顺序示意图;
图13为样本图像通过人工分割提取得到的紫色土区域图像;
图14为样本图像通过直方图极小值分割法分割提取得到的紫色土区域图像;
图15为样本图像通过算法1分割提取得到的紫色土区域的灰度图像;
图16为样本图像通过算法5分割提取得到的紫色土区域的灰度图像;
图17为样本图像通过算法6分割提取得到的紫色土区域的灰度图像;
图18为样本图像通过算法7分割提取得到的紫色土区域的灰度图像;
图19为样本图像通过算法8分割提取得到的紫色土区域的灰度图像;
具体实施方式
如图1所示,本发明提供的一种基于正态分布h阈值的紫色土图像分割提取方法,包括步骤:
s1:获取含有紫色土区域的彩色图像,将含有紫色土区域的彩色图像转化为hsv颜色空间的图像ⅰ;
s2:确定对图像ⅰ进行分割的阈值,根据对图像ⅰ进行分割的阈值,对图像ⅰ进行分割,得到二值图像ⅱ;
s3:识别二值图像ⅱ的边界,得到二值图像ⅲ;
s4:提取二值图像ⅲ中紫色土区域的边界,得到提取出边界的二值图像ⅴ;
s5:对二值图像ⅲ中边界分割出来的封闭区域进行填充,得到二值图像ⅳ;
s6:求二值图像ⅳ与含有紫色土区域的彩色图像的哈达玛积,得到只有紫色土区域的图像。通过上述方法,充分考虑到紫色土彩色图像的土壤区域在hsv颜色空间h分量有良好的聚集特性,并与背景区域有显著差异,将紫色土彩色图像转换为hsv颜色空间,并考虑到紫色土图像的h分量均值在95%和97%置信度上呈正态分布的特性,建立正态分布h阈值计算模型,计算对图像ⅰ进行分割的阈值,将图像的土壤区域从背景区域中快速、准确、完整分割提取出来,并消除了孤立点且填充了边界点围成的内部区域,提高了分割提取紫色土图像的精度。
本实施例中,在野外拍摄包含有紫色土图像的60张彩色图像作为样本图像,每张图像人工提取3个100×100像素正常紫色土和3个100×100像素背景杂质图像分别在rgb、hsv等颜色空间,进行直方图聚集度分析,图2至图7依次为对其中一个样本图像进行直方图聚集度分析得到的样本图像中紫色土图像的h域直方图、s域直方图、v域直方图、hsv聚集度图、以及杂质和背景区域的h域直方图和hsv聚集度图。每张彩色图像分别含有4个土属和20个土种之一的紫色土图像。所述4个土属包括暗紫泥、红棕紫泥、灰棕紫泥和黄棕紫泥。从图2至图7可以得到包含有紫色土图像的彩色图像在hsv颜色空间h域有良好的聚集特性,并与背景有显著差异,对另外59张样本图像做同样的分析,有相同或类似的结果。考虑到紫色土图像的该特性,提出了基于h阈值的分割提取紫色土图像的方案。
随机选取上述样本图像中的每种土种的样本图像随机选取一张,对其人工提取3或5个100*100像素正常紫色土,对应取h域均值最接近的2或3个区块为样本区域,在95%和97%置信度上正态分布区间,统计区间内像素点数,与置信度上理论像素点数进行差异显著性检验,结果如表1所示。
表1
分析表1中的结果,可以得出:95%和97%置信度上理论与实际像素点数无差异。故可以建立正态分布h阈值计算模型,从紫色土h域呈正态分布确定阈值从彩色图像中分割提取紫色土图像。
本实施例中,步骤s1中的获取含有紫色土区域的彩色图像,是人工将紫色土置于镜头的中心位置附近进行采集的,保证含有紫色土区域的彩色图像的中心点位置在所要提取的紫色土区域中。
所述步骤s2具体包括步骤:
s201:在图像ⅰ中提取n个m×n像素的子区域,其中n≥3;
求各个子区域的h分量均值,然后根据n的取值,对m×n像素的子区域进项筛选,获取样本区域,具体筛选过程如下:
若n=3,则求两两子区域之间h分量均值的差值,将差值最小的两个子区域合并,形成一个样本区域,获得样本区域的h分量值的均值和方差;
若n>3时,则对各个子区域的h分量均值进行大小排序,剔除h分量均值最大和最小的子区域,将剩余n-2个区域合并,形成一个样本区域,获得样本区域的h分量值的均值和方差;
本实施例中,在设计表1的试验数据时,将n分别取3或5,得到表1,分析表1中的结果,可以得出:95%和97%置信度上理论与实际像素点数无差异。故可以建立正态分布h阈值计算模型,从紫色土h域呈正态分布确定阈值从彩色图像中分割提取紫色土图像。
本实施例中,在步骤s201中,在图像ⅰ中心区域选取5个m×n像素的子区域,且这5个子区域相互之间可重叠,但不可完全重合,保证这5个子区域包含有全部或部分紫色图像。求这5个子区域的h分量均值,并对h分量均值进行大小排序,去掉h分量均值最大和最小的子区域,将剩余3个子区域合并,形成一个样本区域,获得样本区域的h分量值的均值和方差;
s202:建立正态分布h阈值计算模型,根据样本区域的h分量值的均值和方差,确定对图像ⅰ进行分割的阈值;所述对图像ⅰ进行分割的阈值包括上限阈值hupper和下限阈值hlower;
s203:将图像ⅰ转化为矩阵hi,矩阵hi中各元素值等于图像ⅰ中与各元素位置相同的像素点的h分量值,建立与矩阵hi大小一样的二值矩阵h',并将二值矩阵h'中的元素初始化为0;
s204:根据分割更新规则对二值矩阵h'进行更新,将更新后的二值矩阵h'转化为二值图像,得到二值图像ⅱ;
所述分割更新规则为:若hlower≤h(x,y)≤hupper,则置h'(x,y)=1;若h(x,y)<hlower或h(x,y)>hupper,则置h'(x,y)=0;其中h(x,y)为矩阵hi中位置为(x,y)的元素值,h'(x,y)为二值矩阵h'中位置为(x,y)的元素值。
所述步骤s202中正态分布h阈值计算模型为
hlower=μ-tα/2×σ(1)
hupper=μ+tα/2×σ(2)
其中,μ为h分量值的均值,σ为h分量值的标准差,α为非置信水平在正态分布内的覆盖面积,tα/2是t分布在置信度为1-α的分位数,hlower为对图像ⅰ进行分割的下限阈值,hupper为对图像ⅰ进行分割的上限阈值。
所述步骤s3包括步骤:
s301:将二值图像ⅱ图像转化为二值矩阵a,二值矩阵a中各元素值等于二值图像ⅱ中与各元素位置相同的像素点值;
s302:建立边界识别模板;
s303:求二值矩阵a中的各个元素的8邻域矩阵与边界识别模板的卷积,所述卷积公式为:
f(i,j)表示二值矩阵a中位置为(i,j)的元素值,g(i,j)表示卷积结果,b(a,b)表示边界识别模板上的点,k=3表示边界识别模板为3×3的矩阵,a,b∈[-1,0,1]。
s304:根据二值矩阵a中的元素值和卷积结果,识别背景点、孤立点和边界点,具体如下:
当二值矩阵a中的元素值为0时,则该元素为背景点;
当二值矩阵a中的元素值为1时,若卷积结果为0,则该元素对应的二值图像ⅱ中的像素点为孤立点;若卷积结果为8,则该元素对应的二值图像ⅱ中的像素点为边界内部点;若卷积结果∈[1,7],则该元素对应的二值图像ⅱ中的像素点为边界点;其中,所述边界内部点为由边界点围成封闭区域内部的点。
s305:在二值矩阵a中,将识别出的背景点、孤立点和边界内部点对应的元素置0,边界点对应的元素置1,然后将二值矩阵a变换为二值图像,得到二值图像ⅲ。
所述边界识别模板为
图8为样本图像通过本文步骤s1和步骤s2处理得到二值图像ⅱ;
图9为图8经过本文步骤s3处理后得到的二值图像ⅲ;
图10为图8经过形态学边界识别处理后得到的二值图像;
图11为图10比图9多出来的孤立点的图像;
设定本文的步骤s2为算法1,本文的步骤s3为算法2,本文的步骤s4为算法3,本文的步骤s5为算法4。
图8至图11显示,采用本文算法2进行边界识别,能准确识别边界点,同时可有效剔除孤立点。采用形态学方法进行边界识别也只需要两步,耗时与本文算法2基本相同,但后续处理中对孤立点进行单独处理,增加了总的时间花销。当然,就识别二值图像的边界而言,还可采用2×2、3×3或更大的全1模板识别,判断方式与本文算法2相似。但,2×2全1模板不能有效剔除孤立点,比3×3更大的全1模板以o(n2)时间复杂度增大了时间花销,而3×3全1模板比本文算法2判断边界点更复杂。由于步骤s3后要进行步骤s4的操作,即识别了边界后要进行提取边界的操作,为了避免一些不必要的判断,应在识别边界时将孤立点排除,所述步骤s3实现了对孤立点的有效去除,保证了步骤s4的有效操作。
所述步骤s4包括步骤
s401:将二值图像ⅲ图像转化为二值矩阵b,二值矩阵b中各元素值等于二值图像ⅲ中与各元素位置相同的像素点值;
建立与二值矩阵b大小一样的遍历矩阵c,并将遍历矩阵c中的元素均初始化为0;
建立与二值矩阵b大小一样的边界矩阵d,
建立堆栈ⅰ;
确定二值矩阵b的中心点位置(xm,ym);
设定二值矩阵b中的边界点的位置中最小行号为x1,最大行号为x2,最小列号为y1,最大列号为y2;
本实施中,所述遍历矩阵c用于标记二值图像ⅲ中的点是否被遍历;所述边界矩阵d用于标记二值图像ⅲ中被识别出的边界点。
s402:设置二值矩阵b左上角点为搜索起始点,将搜索起始点;
s403:初始化堆栈ⅰ;将边界矩阵d中的元素均初始化为0;
s404:在二值矩阵b中,跳过已搜索过的点,按照预设的搜索顺序,对二值矩阵b中的点进行搜索,判断搜索的点是否为边界点;若搜索到点为边界点,则将该边界点的行号赋值给最小行号为x1和最大行号为x2,将该边界点的列号赋值给最小列号为y1和最大列号为y2,将该边界点压入堆栈ⅰ,将边界矩阵d中与该边界点在二值矩阵b中的位置相同的点置1,将遍历矩阵c中与该边界点在二值矩阵b中的位置相同的点置1,并将该边界点作为当前遍历点,进入步骤s405;
若未搜索到边界点,则结束对紫色土区域边界的提取,将边界矩阵d转换为二值图像,得到二值图像ⅴ;
所述预设的搜索顺序为:按照从上至下的顺序搜索各行的点,且对各行内部的点进行搜索时按照从左到右的顺序进行搜索;所述判断搜索的点是否为边界点,即判断在二值矩阵b该搜索到点的值是否为1;
对当前遍历点四连通域的按照图12的遍历顺序,进行步骤s405至步骤s408的遍历;图12中的实心圆表示当前遍历点,标记有1的空心圆表示当前遍历点四连通域的右邻点,标记有2的空心圆表示当前遍历点四连通域的下邻点,标记有3的空心圆表示当前遍历点四连通域的左邻点,标记有4的空心圆表示当前遍历点四连通域的上邻点,搜索顺序是从右邻点开始遍历,依次遍历右邻点、下邻点、左邻点、上邻点,一旦搜索到当前遍历点四连通域的邻点有未经遍历的边界点,则停止对当前遍历点四连通域的遍历。
s405:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的右邻点值是否为1,如果为1,则进入步骤s406;
如果为0,则在二值矩阵b中判断与右邻点在遍历矩阵c中位置相同的点值是否为1,如果与右邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该右邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该右邻点在遍历矩阵c中位置相同的点,判断当前遍历点的列号值是否大于y2,如果大于y2,则y2更新为当前遍历点的列号值,返回步骤s405;如果与右邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s406;
本实施例中,遍历矩阵c中元素值为1,表示在二值矩阵b中与该元素在遍历矩阵c中位置相同的点已被遍历,遍历矩阵c中元素值为0,表示在二值矩阵b中与该元素在遍历矩阵c中位置相同的点未被遍历,
本实施例中,二值矩阵b中元素值为1,表示该元素为边界点,二值矩阵b中元素值为0,表示该元素不是边界点。
s406:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的下邻点值是否为1,如果为1,则进入步骤s407;
如果为0,则在二值矩阵b中判断与下邻点在遍历矩阵c中位置相同的点值是否为1,如果与下邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该下邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该下邻点在遍历矩阵c中位置相同的点,判断当前遍历点的行号值是否大于x2,如果大于x2,则x2更新为当前遍历点的行号值,返回步骤s405;如果与下邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s407;
s407:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的左邻点值是否为1,如果为1,则进入步骤s408;
如果为0,则在二值矩阵b中判断与左邻点在遍历矩阵c中位置相同的点值是否为1,如果与左邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该左邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该左邻点在遍历矩阵c中位置相同的点,判断当前遍历点的列号值是否小于y1,如果大于y1,则y1更新为当前遍历点的列号值,返回步骤s405;如果与左邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s407;
s408:在遍历矩阵c中,首先判断与当前遍历点在二值矩阵b中的位置相同的点的上邻点值是否为1,如果为1,则进入步骤s409;
如果为0,则在二值矩阵b中判断与上邻点在遍历矩阵c中位置相同的点值是否为1,如果与上邻点在遍历矩阵c中位置相同的点值为1,将边界矩阵d中该上邻点在遍历矩阵c中位置相同的元素值置1,并将在二值矩阵b中将当前遍历点更新为该上邻点在遍历矩阵c中位置相同的点,判断当前遍历点的行号值是否小于x1,如果大于x1,则x1更新为当前遍历点的行号值,返回步骤s405;如果与上邻点在遍历矩阵c中位置相同的点值为0,则进入步骤s409;
s409:将堆栈ⅰ的当前栈顶点出栈后,再判断堆栈ⅰ是否为空或者堆栈ⅰ的栈顶点是否是遍历起始点;
如果堆栈ⅰ不为空,且堆栈ⅰ的栈顶点不是遍历起始点,则将出栈的点作为当前遍历点,返回步骤s405;
如果堆栈ⅰ为空,或者堆栈ⅰ的栈顶点是遍历起始点,则判断x1<xm<x2且y1<ym<y2)是否成立,如果为不成立,返回步骤s403:如果成立,则结束对紫色土区域边界的提取,将边界矩阵d转换为二值图像,得到二值图像ⅴ。最后得到的最小行号为位于二值矩阵b中最下方的边界点的行号,最大行号为位于二值矩阵b中最上方的边界点的行号,最小列号为位于二值矩阵b中最左边的边界点的列号,最大列号为位于二值矩阵b中最右边的边界点的列号。通过该方法,将剩余孤立点删除,并且提取的边界点围成所要分割提取的紫色土区域的边界,位于该边界内的点即为所要分割提取的紫色土区域的点。上述方法优化了提取边界点的遍历结束判别条件,减小了时间开销,提高了分割提取紫色土图像的精度。
所述步骤s5包括步骤
s501:将二值图像ⅴ转化为二值矩阵e,二值矩阵e中各元素值等于二值图像ⅴ中与各元素位置相同的像素点值;
s502:设定与二值矩阵e大小一样的填充矩阵f,并将填充矩阵f中的元素均初始化为0;建立并初始化堆栈ⅱ,获取填充矩阵f的中心点位置(xm,ym),以该中心点为遍历起点,且将遍历起点作为当前遍历点;
s503:将当前遍历点压入堆栈ⅱ,
s504:在填充矩阵f中,将当前遍历点的对应元素值置1;
按照与图12一样的顺序,对当前遍历点的四连通域的右邻点、下邻点、左邻点、上邻点依次进行步骤s505至s508的遍历,一旦发现右邻点、下邻点、左邻点、上邻点中存在没有填充且不为边界的点,则停止对剩余的邻点进行遍历。
本实施例中,填充矩阵f中的元素为0表示该元素未被填充,二值矩阵e的元素为1表示该元素为步骤s4提取的紫色土区域的边界。
s505:判断填充矩阵f中当前遍历点的右邻点值是否为0,且在二值矩阵e中与该右邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该右邻点;返回步骤s503;
如果不均为0,则进入步骤s506;
s506:判断填充矩阵f中当前遍历点的下邻点值是否为0,且在二值矩阵e中与该下邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该下邻点;返回步骤s503;
如果不均为0,则进入步骤s507;
s507:判断填充矩阵f中当前遍历点的左邻点值是否为0,且在二值矩阵e中与该左邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该左邻点;返回步骤s503;
如果不均为0,则进入步骤s508;
s508:判断填充矩阵f中当前遍历点的上邻点值是否为0,且在二值矩阵e中与该上邻点在二值矩阵e位置相同的元素值是否为0,
如果均为0,则将当前遍历点更新为该上邻点;返回步骤s503;
如果不均为0,则进入步骤s509;
s509:将堆栈ⅱ的栈顶点出栈后,将堆栈ⅱ的当前栈顶点对应的填充矩阵f的点作为当前遍历点,
然后判断当前遍历点是否回到遍历起点,如果当前遍历点没有回到遍历起点,则返回步骤s503;如果当前遍历点回到遍历起点,将结束遍历,将填充矩阵f转化成二值图像,得到二值图像ⅳ。通过上述方法,将步骤s4提取的紫色土区域的边界围成的封闭区域进行填充,得到要分割提取的紫色土图像的对应的二值图像ⅳ。上述方法中,填充矩阵f的中心点即为种子点,相较于随机选取的种子点,上述方法的种子点选取方法保证了种子点一定置于提取的紫色土区域的边界围成的封闭区域内,减少不必要的遍历开销,从而减小时间开销,提高了填充精度。
所述中心点位置(xm,ym)的计算公式为
其中,m为二值图像ⅲ中像素点的总行数或填充矩阵f中元素的总行数;n为二值图像ⅲ中像素点的总列数或填充矩阵iv中元素的总列数,xm为中心点位置的行号,ym为中心点位置的列号;二值图像ⅲ中像素点的总行数等于填充矩阵f中元素的总行数;二值图像ⅲ中像素点的总列数等于填充矩阵f中元素的总列数。
本实施例中,图像ⅰ、二值图像ⅱ、二值图像ⅲ、二值图像ⅴ、二值图像ⅳ、矩阵hi、二值矩阵h'、二值矩阵a、二值矩阵b、遍历矩阵c、边界矩阵d、二值矩阵e、填充矩阵f的大小均为m×n,m为其行数,n为其列数。
本实施例中,算法1可以避免文献1中采用极小值分割图像可能出现的多峰困扰算法的时间开销,该时间开销为o(m·n)。
所述文献1为“lidm,wangyz,dub.researchonsegmentationmethodsofweedandsoilbackgroundunderhsvcolormodel[c]//2009secondinternationalworkshoponknowledgediscoveryanddatamining,2009,628–631”。
进一步,将算法2、算法3和算法4与文献2的算法进行比较分析,相对于文献2的算法,算法2、算法3和算法4有明确的终止条件,能更好地清除离散小土壤区域及空洞填充,而文献1的算法没有终止条件,故本申请方法在能完成分割提取出紫色土图像的基础上,时间开销更少。算法2、算法3和算法4的时间复杂度分别是o(m·n)、o(m·n/4+l1)和o(2t),其中,l1是紫色土图像边界点像素的总个数,且l1<<m·n,t为紫色土图像的像素点个数,且t<m·n,算法2、算法3和算法4没有增加额外的时间花销。而文献2中分割算法中形态学区域填充步骤的时间花销为o(l2·m·n),其中,l2为填充时膨胀的次数,且当l2≤5时文献2中的分割算法中形态学区域填充步骤不能实现填充空洞的目的。
所述文献2为“梁喜凤,章艳.串番茄采摘点的识别方法[j].中国农机化学报,2016,37(11):131-134+149.liangxf,zhangy.recognitionmethodofpickingpointfortomatocluster[j].journalofchineseagriculturalmechanization,2016,37(11):131-134,149”。
本实施例中,设文献1中公开的算法为算法5,设结合本申请中利用算法1进行初始分割和利用形态学去空洞的算法为算法6、设结合本申请算法1、算法2、算法3和利用形态学填充的算法为算法7,设本申请方法,即结合算法1、算法2、算法3和算法4为算法8。
本实施例中,所述利用形态学去空洞和利用形态学填充的算法的模板为
4种算法的仿真实验的时间开销如表2所示。
表2
从表2分析可以得到,4种算法中,算法8的总时间开销最小,即本申请的方法的总时间开销最小,比算法4快10%,比算法2快30%,比算法7快10倍;本申请中提取边界与填充算法的时间花销最少,比算法5快51倍,比算法6快57倍,比算法7快近130倍。
图13为样本图像通过人工分割提取得到的紫色土区域图像;
图14为样本图像通过直方图极小值分割法分割提取得到的紫色土区域图像;
图15为样本图像通过算法1分割提取得到的紫色土区域的灰度图像;
图16为样本图像通过算法5分割提取得到的紫色土区域的灰度图像;
图17为样本图像通过算法6分割提取得到的紫色土区域的灰度图像;
图18为样本图像通过算法7分割提取得到的紫色土区域的灰度图像;
图19为样本图像通过算法8分割提取得到的紫色土区域的灰度图像;
图13至图19分别为随机选取的一个样本图像分别通过人工、直方图极小值分割法、算法1、算法5、算法6、算法7、算法8分割提取得到的紫色土灰度图像,在图13至图19中不同灰度代表不同的h分量值,用二值图并不能很好表示h分量值的差别,故在此附上的是灰度图。将图13作为分割提取紫色图图像的标准参照。
图13至图19显示:算法1比算法5分割效果好,空洞小,空洞少;算法5分割提取得到的紫色土图像还存在少量空洞;算法6分割提取得到的紫色土图像相对于算法5分割提取得到的紫色土图像存在空洞要少一些,但也不能完全去除空洞,算法8,也就是本申请算法的分割效果最好,能够分割出完整的紫色土的自然土图像。在其他样本图像中也有类似的结果。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!