机器学习人工智能翻译数据库的更新方法与流程
本发明涉及语音控制技术领域,更具体地,涉及一种机器学习人工智能翻译数据库的更新方法。
背景技术:
随着科学技术的发展和经济全球化,无论是在日常生活中还是学术领域沟通上,在线翻译交流已经存在越来越多的需求。尽管已经存在同声传译、便携式机器翻译设备等应运而生,但在涉及专业领域的会议或课堂等的使用场景里,传统机器翻译设备的准确度以及同声传译人员的效率是令人堪忧的。尤其是当某方语速较快时,机器翻译将难以胜任,而同声传译人员则需要使用重新确认的方式复述没有跟上的语言,从而给一些使用场景带来不顺畅的体验。
为了同时满足在线翻译的效率和准确性的提高需求,申请号为cn201710203439.8的中国发明专利申请公开了一种多语言智能预处理实时统计机器翻译系统,包括:接收模块、预处理模块、机器翻译模块和后处理模块。所述接收模块包括文本语言接收模块和语音识别结果接收模块;所述预处理模块包括文本预处理模块和语音识别结果预处理模块;机器翻译模块,所述机器翻译模块用于学习短语对短语的翻译,并对经过预处理模块处理的短语找出对应的翻译短语,以及把短语连接成完整的句子;后处理模块,所述后处理模块用于对翻译结果做单词标点规范化、大小写规范化和格式规范化处理,使其更加接近目标语言的表达习惯,并作为最终结果输出。然而,这种系统对于现有技术的上述弊端解决力度有限。
技术实现要素:
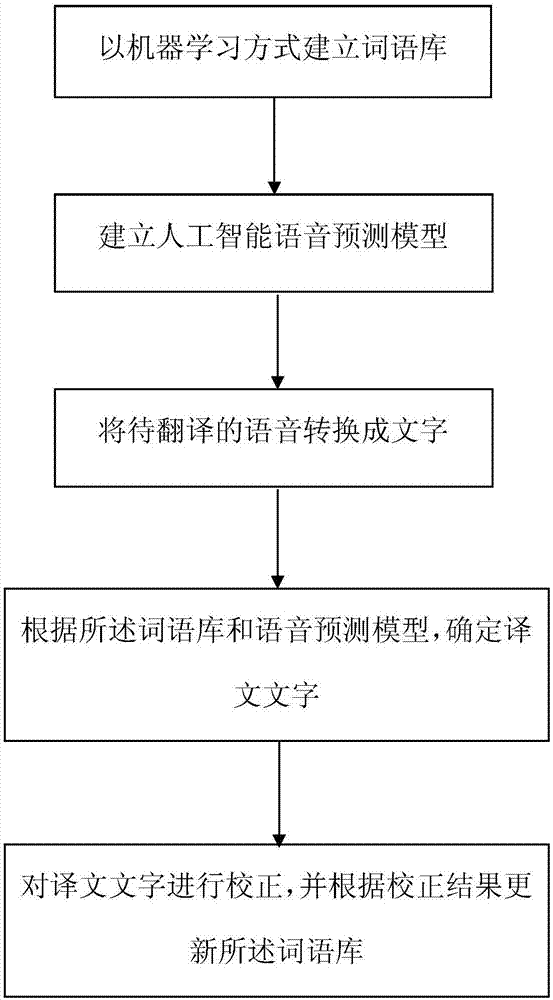
为了进一步提高在线翻译时的效率和准确性,从而提高翻译数据库的更新效率,本发明提供了一种机器学习人工智能翻译数据库的更新方法,包括:
(10)以机器学习方式建立词语库;
(20)建立人工智能语音预测模型;
(30)将待翻译的语音转换成文字;
(40)根据所述词语库和语音预测模型,确定译文文字;
(50)对译文文字进行校正,并根据校正结果更新所述词语库。
进一步地,所述步骤(10)包括:利用机器学习方式,根据词典建立外文词语和与该外文词语对应的中文含义的词语之间的第一关联,其中中文词语的译文为多个时以词典中的第一顺序位置标识的中文译文词语为主要中文译文词语而之后顺序位置的中文译文词语作为次要中文译文词语。
进一步地,所述步骤(20)包括:
(201)根据外文文章进行切词得到外文词语并根据该外文文章的中文译文词语,建立外文词语和中文译文词语以及该中文译文词语之后接续的二级词语的第二关联;
(202)将第一关联和第二关联进行索引;
进一步地,所述步骤(201)包括:根据外文文章以无监督学习方式进行机器学习。
进一步地,所述步骤(201)包括:采用随机梯度下降法对外文文章及其译文进行机器学习。
进一步地,所述步骤(202)包括:
以第一关联为主键,从第二关联中出现的与第一关联相关的信息进行索引。
进一步地,所述以第一关联为主键,从第二关联中出现的与第一关联相关的信息进行索引包括:
(2021)主键信息确定:假设第一关联中,英文词语ei对应主要中文译文词语cj;且根据第二关联,词语cj之后接续的二级词语构成集合{sm,pm},则以词语cj为主键,其中pm是词语sm出现在cj之后作为接续的二级词语的概率,i、j和m均为从1开始的自然数;
(2022)定义词语cj出现的概率:
p(sm|cj)=χgh(pj),
其中
(2023)根据概率p(sm|cj)确定词语cj取当前含义时与语境的匹配度:
计算
计算
(2024)校正sm作为cj的接续的二级词语时与语境的匹配度:
计算
进一步地,所述步骤(30)包括:
(301)对原始语音信号作线性分析,得到加权倒频谱系数作为语音特征参数;
(302)根据语音特征参数获得语音模型;
(303)对待识别的语音用语音模型进行匹配,利用帧同步网络搜索,对每一帧语音针对不同的模型确定一个输出概率值,在匹配过程中保留多条路径,最后回溯出匹配结果;
(304)对匹配的结果用状态持续时间分布及最佳路径概率分布进行判别拒识掉识别范围之外的语音,获得正确的识别结果。
进一步地,所述步骤(40)包括:
基于stt技术、利用中文译文词语产生语音。
本发明的有益效果包括:能够通过机器学习得到的大数据外文-中文对照词典,基于6阶深度概率分析方法进行语义和语境的匹配,从而相比现有技术的做法降低了超过40%以上的运算量,在确保翻译准确性的同时提高了翻译效率和更新效率。
附图说明
图1示出了本发明方法的流程图。
具体实施方式
如图1所示,根据本发明的优选实施例,本发明提供了一种机器学习人工智能翻译数据库的更新方法,包括:
(10)以机器学习方式建立词语库;
(20)建立人工智能语音预测模型;
(30)将待翻译的语音转换成文字;
(40)根据所述词语库和语音预测模型,确定译文文字;
(50)对译文文字进行校正,并根据校正结果更新所述词语库。
其中,该校正是通过人工干预的方式参与的人为校正。
优选地,所述步骤(10)包括:利用机器学习方式,根据词典建立外文词语和与该外文词语对应的中文含义的词语之间的第一关联,其中中文词语的译文为多个时以词典中的第一顺序位置标识的中文译文词语为主要中文译文词语而之后顺序位置的中文译文词语作为次要中文译文词语。
优选地,所述步骤(20)包括:
(201)根据外文文章进行切词得到外文词语并根据该外文文章的中文译文词语,建立外文词语和中文译文词语以及该中文译文词语之后接续的二级词语的第二关联;
(202)将第一关联和第二关联进行索引;
优选地,所述步骤(201)包括:根据外文文章以无监督学习方式进行机器学习。
优选地,所述步骤(201)包括:采用随机梯度下降法对外文文章及其译文进行机器学习。
优选地,所述步骤(202)包括:
以第一关联为主键,从第二关联中出现的与第一关联相关的信息进行索引。该主键为表示外文与中文的文字对应关系的数据库的主键。
优选地,所述以第一关联为主键,从第二关联中出现的与第一关联相关的信息进行索引包括:
(2021)主键信息确定:假设第一关联中,英文词语ei对应主要中文译文词语cj;且根据第二关联,词语cj之后接续的二级词语构成集合{sm,pm},则以词语cj为主键,其中pm是词语sm出现在cj之后作为接续的二级词语的概率,i、j和m均为从1开始的自然数;
(2022)定义词语cj出现的概率:
p(sm|cj)=χgh(pj),
其中
(2023)根据概率p(sm|cj)确定词语cj取当前含义时与语境的匹配度:
计算
计算
(2024)校正sm作为cj的接续的二级词语时与语境的匹配度:
计算
优选地,所述步骤(30)包括:
(301)对原始语音信号作线性分析,得到加权倒频谱系数作为语音特征参数;
(302)根据语音特征参数获得语音模型;
(303)对待识别的语音用语音模型进行匹配,利用帧同步网络搜索,对每一帧语音针对不同的模型确定一个输出概率值,在匹配过程中保留多条路径,最后回溯出匹配结果;
(304)对匹配的结果用状态持续时间分布及最佳路径概率分布进行判别拒识掉识别范围之外的语音,获得正确的识别结果。
优选地,所述步骤(40)包括:
基于stt技术,即speechtotext技术、利用中文译文词语产生语音。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!