洪水全要素异变的诊断方法与流程
本发明涉及水文水资源领域,更具体地,涉及一种洪水全要素异变的诊断方法。
背景技术:
洪水作为一种复杂的自然现象,它所包含多个特征值。因此洪水的异变问题需要考虑洪水全要素的异变性。洪水全要素异变的诊断结果更加科学合理地度量了各场洪水之间的差异,对于建立洪水调度规则、评估洪水危害大小、以及洪水预测预报等,具有重要的意义。目前,解决洪水异变的问题主要集中在:1.依据相关方法(如:mann-kendall、pettitt等)识别洪水过程中某单一要素的异变点;2.从洪水频率角度阐述洪水的异变;3.从分类的角度探讨洪水的异变性。前面两种渠道已经做了大量的研究,取得较为的相关研究成果,但是仅解析了洪水某项指标的异变性,并未将洪水全要素的异变性进行诊断。分类的角度,可以综合洪水事件的多要素特性,从而达到研究洪水全要素异变的目的,目前所做的研究主要集中在两方面,一方面是通过建立目标方程,进行优化求解得出最佳的分类结果,其主要不足在于以牺牲目标函数的优化效果为代价,其次有些目标方程的计算复杂,通用性较差;另一方面是求得综合评价值,利用综合评价值对洪水强度进行分类,其主要不足体现在缺乏确定洪水分类类别数的理论依据。总体来说,由于洪水存在高度的复杂性、随机性,并且反应洪水过程的各要素与洪水的评价因子之间的非线性关系,大大增加了洪水全要素异变性识别的难度。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种洪水全要素异变的诊断方法,
为解决上述技术问题,本发明采用的技术方案是:一种洪水全要素异变的诊断方法,包括以下步骤:
s1.获取洪水全要素的指标数据;
s2.对各个指标进行归一化处理;由于不同指标的量纲不用,为了消除量纲对分类结果的影响,在建立模型之前对各个指标进行归一化处理;
s3.从分类的角度对洪水全要素的异变诊断进行界定,利用afs-fcm模型确定分类数;洪水全要素的异变诊断从分类的角度进行界定,因此分类数的确定是一个关键性的问题,在本专利中用afs-fcm模型来确定分类数;分类,是指按照种类、等级或性质分别归类。通过分类的思想诊断洪水全要素异变的思路为:以反应洪水过程的指标作为输入,相似的洪水过程划为一类,即利用分类的手段来诊断洪水全要素的异变性;
s4.确定各个要素的权重值大小;由于洪水全要素涉及多项指标,不同指标对洪水是件(如洪水强度、洪水灾害程度)的影响性不同,因此需要确定各指标的权重大小;
s5.依据归一化的指标、分类数、各要素的权重值大小,依据云模型的计算方式,计算得到洪水全要素异变的诊断结果;
s6.根据分类结果解读洪水全要素的异变性。
进一步的,所述的s1步骤中的洪水全要素的指标数据包括洪峰流量值、洪峰水位、最大3天洪量值、最大7天洪量值和洪水历时。
进一步的,由于所选的指标均表明指标越大,带来的灾害越加严重,因此这些指标可定义为反应洪水过程的正向型指标;所述的s2步骤具体包括:假设第i场洪水第j个指标为
式中,
进一步的,所述的s3步骤中利用afs-fcm模型确定分类数的核心为利用平均目标函数值来确定最佳分类数,平均目标函数越小的分类数越好,其中,平均目标函数的计算公式为:
式中x={xi,i=1,2…,n}为训练样本集,c是预设的类别数目,
vi(i=1,2,…,c)为各类别的聚类中心,其中:
且
进一步的,所述的s4步骤具体包括:
s41.计算多维样本数据的一维投影:
式中xij(j=1,2,…,n)是一个n维样本值,a=(a1,a2,…,an),aj∈[-1,1],为一个投影向量;
s42.构造投影指标函数:
qa=sa·da
式中的sa为类间距离函数,da为类内密度函数,其中:
式中,
s43.构建投影追踪模型:
s44.根据投影值(zi)和归一化的各要素值(xij)得到各指标在各场洪水中的投影值:
zij=aj×xij;
s45.计算各要素在各场洪水中的权重cij:
s46.计算各要素的平均权重值cj:
为了使得到的权重均为正值,即cj>0,在此将投影向量a=(a1,a2,…,an)的范围进行调整为:a∈(0,1]。
进一步的,所述的s5步骤具体包括:
s51.依据步骤s3中确定最佳分类数,划定各要素的类别标准集;
s52.依据标准集,计算云模型的数字特征,并生成云模型;
s53.结合各要素的平均权重,计算综合确定度;
s54.利用综合确定度,判定样本级别。
进一步的,所述的s61步骤中采用等距离法划分各指标的标准集,其计算公式包括:
mj和mj分别是第j项指标的最大、最小值;
式中:detaj=(mj-mj)/c;f=1,2,…,c,c为分类数,
进一步地,所述的s62步骤中计算云模型的数字特征具体包括:
s521.以各指标的标准集作为输入的样本点;
s522.以第j项指标的第f个分类标准集为输入的样本点,计算均值:
s523.计算熵:
s524.超熵为:hej=0.1;则式中
进一步地,所述的s63步骤中计算综合确定度具体包括:
s531.生成以
s532.计算xij在每个标准集下的隶属度
s533.计算第i场洪水在每个标准集下的综合确定度μi:
与现有技术相比,有益效果是:本发明提供的一种洪水全要素异变的诊断方法,利用afs-fcm模型中的平均目标函数值,为分类数的划分寻找到了科学的依据;平均目标函数值能够刻画样本到所属中心的平均距离,因此能够用于比较不同分类数分类方案的优劣,在确定权重时,将各要素对洪水事件的影响性进行量化,依据量化结果为各洪水要素提供权重值,为洪水全要素的异变性分析提供了有益的支撑。
附图说明
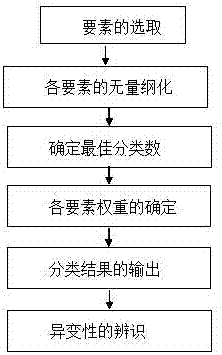
图1是本发明方法流程图。
图2是本发明实施例中洪水要素的权重图。
图3是本发明实施例洪峰流量、洪峰水位、最大3天洪量、最大7天洪量、洪水总量和洪水历时评价标准云图。
图4是本发明实施例根据云模型的分类结果,得出洪水全要素异变识别结果图。
图5是本发明实施例中采用模糊c-均值聚类算法(fcm)和采用基于人工鱼群改进的模糊c-均值聚类算法(afs-fcm)获取的平均目标函数值。
具体实施方式
附图仅用于示例性说明,不能理解为对本发明的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本发明的限制。
如图1所示,一种洪水全要素异变的诊断方法,包括以下步骤:
步骤1.如图3所示,获取洪水全要素的指标数据;洪水全要素的指标数据包括洪峰流量值、洪峰水位、最大3天洪量值、最大7天洪量值和洪水历时。
步骤2.对各个指标进行归一化处理;由于不同指标的量纲不用,为了消除量纲对分类结果的影响,在建立模型之前对各个指标进行归一化处理;
由于所选的指标均表明指标越大,带来的灾害越加严重,因此这些指标可定义为反应洪水过程的正向型指标;具体包括:假设第i场洪水第j个指标为
式中,
步骤3.从分类的角度对洪水全要素的异变诊断进行界定,利用afs-fcm模型确定分类数;洪水全要素的异变诊断从分类的角度进行界定,因此分类数的确定是一个关键性的问题,在本专利中用afs-fcm模型来确定分类数;分类,是指按照种类、等级或性质分别归类。通过分类的思想诊断洪水全要素异变的思路为:以反应洪水过程的指标作为输入,相似的洪水过程划为一类,即利用分类的手段来诊断洪水全要素的异变性;
其中,利用afs-fcm模型确定分类数的核心为利用平均目标函数值来确定最佳分类数,平均目标函数越小的分类数越好,平均目标函数的计算公式为:
式中x={xi,i=1,2…,n}为训练样本集,c是预设的类别数目,vi(i=1,2,…,c)为各类别的聚类中心,其中:
且
将分类数c设为2,3,…,8和9,采用人工鱼群算法(afs)对目标函数进行优化,并将最得到的结果与不采用人工鱼群优化得到的结果进行比较,结果如图5所示。不论是采用模糊c-均值聚类算法(fcm)还是采用基于人工鱼群改进的模糊c-均值聚类算法(afs-fcm),按照平均目标函数最小的依据,即当min(jb)下的c值即为最佳分类数。可见,最佳分类个数是2,其次是4、3和7。由于2作为分类数时,分类过泛,无法展示洪水之间的强度差异,因此4作为最佳分类数,分别对应:特大洪水(i)、大洪水(ii)、较大洪水(iii)和一般洪水(iv)四类。
步骤4.确定各个要素的权重值大小;由于洪水全要素涉及多项指标,不同指标对洪水是件(如洪水强度、洪水灾害程度)的影响性不同,因此需要确定各指标的权重大小;常用的确定指标权重的方法有专家打分法、层次分析法,由于各要素对洪水事件影响性不同,因此洪水各要素对洪水事件影响力大小可以作为各要素的权重值。
具体包括:
s41.计算多维样本数据的一维投影:
式中xij(j=1,2,…,n)是一个n维样本值,a=(a1,a2,…,an),aj∈[-1,1],为一个投影向量;
s42.构造投影指标函数:
qa=sa·da
式中的sa为类间距离函数,da为类内密度函数,其中:
式中,
s43.构建投影追踪模型:
s44.根据投影值(zi)和归一化的各要素值(xij)得到各指标在各场洪水中的投影值:
zij=aj×xij;
s45.计算各要素在各场洪水中的权重cij:
s46.计算各要素的平均权重值cj:
为了使得到的权重均为正值,即cj>0,在此将投影向量a=(a1,a2,…,an)的范围进行调整为:a∈(0,1]。
步骤5.依据归一化的指标、分类数、各要素的权重值大小,依据云模型的计算方式,计算得到洪水全要素异变的诊断结果。
具体包括:
s51.依据步骤s3中确定最佳分类数,划定各要素的类别标准集;
其计算公式包括:
mj和mj分别是第j项指标的最大、最小值;
式中:detaj=(mj-mj)/c;f=1,2,…,c,c为分类数,
s52.依据标准集,计算云模型的数字特征,并生成云模型;
以各指标的标准集作为输入的样本点;
s522.以第j项指标的第f个分类标准集为输入的样本点,计算均值:
s523.计算熵:
s524.超熵为:hej=0.1;则式中
s53.结合各要素的平均权重,计算综合确定度;
具体包括:
s531.生成以
s532.计算xij在每个标准集下的隶属度
s533.计算第i场洪水在每个标准集下的综合确定度μi:
s54.利用综合确定度,判定样本级别。
步骤6.根据分类结果解读洪水全要素的异变性。
图4是分类结果图,通过分类结果可以解读洪水全要素的异变性,具体地:根据计算所得的最佳分类数,分别对应:特大洪水(i)、大洪水(ii)、较大洪水(iii)和一般洪水(iv)四类。图4表明,一般洪水在整个年份跨度内未产生变异,较大洪水在研究时段内的出现从频繁出现到出现频次较少的异变,而大洪水则表现为二十一世纪前后出现较多的异变性,特大洪水仅在本世纪出现。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!