一种面向案情的关键词提取方法及系统与流程
本发明具体涉及一种面向案情的关键词提取方法及系统。
背景技术:
在一段关于犯罪案情描述中,冗余的信息很多,其实大多数时候,只需要知道三个要素就可以来断案了,分别是:犯罪嫌疑人、犯罪类型和程度。假如能利用机器将这三个关键字自动提取出来,那么案情分析的工作量将会大大减少。
当前的关键词提取技术主要是利用ti-idf方法来提取,该方法的基本思路是,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf并不能准确地提取这三个要素,没有考虑到关键要素的一些特征。利用本发明的这种方法可以大大提高准确性,并减少断案工作量。
技术实现要素:
本发明要解决的技术问题在于,针对上述目前犯罪案情描述关键词提取技术的不足,提供一种面向案情的关键词提取方法及系统解决上述问题。
一种面向案情的关键词提取方法,包括以下步骤:
步骤1:对用于训练模型的案情描述进行关键词标注,标注出第一关键词、第二关键词、第三关键词,对用于训练模型的案情描述采用ltp进行分词,然后采用word2vec将用于训练模型的案情描述中的每个分词转换成词向量,每条案情描述的所有分词的词向量拼接起来,构成用于训练模型的案情描述的词向量矩阵;
步骤2:对第三关键词进行词法特征计算,计算第三关键词的七个特征,包括关键词的长度、关键词的词性、在原文档中位于第一关键词和第二关键词的哪个位置、与第一关键词的距离、与第二关键词的距离、与案情描述开头的距离、与案情描述结尾的距离;
步骤3:分别计算用于训练模型的案情描述中除了第一关键词和第二关键词之外其他每个分词的七个特征,计算每个分词的每个特征在第三关键词的七个特征中对应的特征中所占的比例,并将得到的每个分词的七个比例数字组成一个关于该分词词法特征的七维向量,作为每个分词的词法特征向量,第一关键词和第二关键词的词法特征向量全部设置为0,每一条案情描述中所有分词的词法特征向量拼接起来,得到用于训练模型的案情描述的词法特征矩阵;
步骤4:采用python库中的keras包,将用于训练模型的案情描述的词向量矩阵放入到一个keras的模型中去,用于训练模型的案情描述的词法特征矩阵也放入到一个keras中的模型中去,然后将两个模型利用keras中的merge功能,将两个模型合并为一个模型,然后将合并后的模型运用keras中的fit功能来训练模型;
步骤5:对待预测第三关键词的案情描述进行分词和运用word2vec转换成词向量矩阵,并且和标注出的另外两个关键词一起输入到步骤4训练完成的模型中,利用keras中的predict功能得到待预测第三关键词的案情描述的每个分词是第三关键词犯罪程度的概率,概率最大的就作为提取的第三关键词。
进一步的,关键词的长度就是关键词包含的字数。
进一步的,关键词的词性用ltp进行词性标注。
进一步的,在原文档中位于第一关键词和第二关键词的哪个位置的确定方法是,假如第三关键词犯罪程度在另外两个关键词之前出现在原句中时关键词该特征就标注为1,在另外两个关键词中间出现在原句中时该特征就为2,在原句中位于另外两个关键词后面时该特征就标注为3。
进一步的,与第一关键词的距离是指与第一关键词中间的字数。
进一步的,与第二关键词的距离是指与第二关键词中间的字数。
进一步的,与案情描述开头的距离是指距离案情描述开头的字数。
进一步的,与案情描述结尾的距离是指距离案情描述结尾的字数。
一种面向案情的关键词提取系统,能够实现以下功能:
预处理模块:对用于训练模型的案情描述进行关键词标注,标注出第一关键词、第二关键词、第三关键词,对用于训练模型的案情描述采用ltp进行分词,然后采用word2vec将用于训练模型的案情描述中的每个分词转换成词向量,每条案情描述的所有分词的词向量拼接起来,构成用于训练模型的案情描述的词向量矩阵;
特征计算模块:对第三关键词进行词法特征计算,计算第三关键词的七个特征,包括关键词的长度、关键词的词性、在原文档中位于第一关键词和第二关键词的哪个位置、与第一关键词的距离、与第二关键词的距离、与案情描述开头的距离、与案情描述结尾的距离;
特征拼接模块:分别计算用于训练模型的案情描述中除了第一关键词和第二关键词之外其他每个分词的七个特征,计算每个分词的每个特征在第三关键词的七个特征中对应的特征中所占的比例,并将得到的每个分词的七个比例数字组成一个关于该分词词法特征的七维向量,作为每个分词的词法特征向量,第一关键词和第二关键词的词法特征向量全部设置为0,每一条案情描述中所有分词的词法特征向量拼接起来,得到用于训练模型的案情描述的词法特征矩阵;
模型训练模块:采用python库中的keras包,将用于训练模型的案情描述的词向量矩阵放入到一个keras的模型中去,用于训练模型的案情描述的词法特征矩阵也放入到一个keras中的模型中去,然后将两个模型利用keras中的merge功能,将两个模型合并为一个模型,然后将合并后的模型运用keras中的fit功能来训练模型;
结果获取模块:对待预测第三关键词的案情描述进行分词和运用word2vec转换成词向量矩阵,并且和手工标注的另外两个关键词一起输入到步骤4训练完成的模型中,利用keras中的predict功能得到待预测第三关键词的案情描述的每个分词是第三关键词犯罪程度的概率,概率最大的就作为提取的第三关键词。
本发明针对传统的关键词提取只是利用词频和逆文件频率(tf-idf)来对文中的关键词进行提取,而没有考虑词语的特征。本发明方案是对案情描述进行关键词提取,利用本发明的这种方法可以大大提高关键词提取的准确性,并减少断案工作量。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1为本发明的一种面向案情的关键词提取方法结构图;
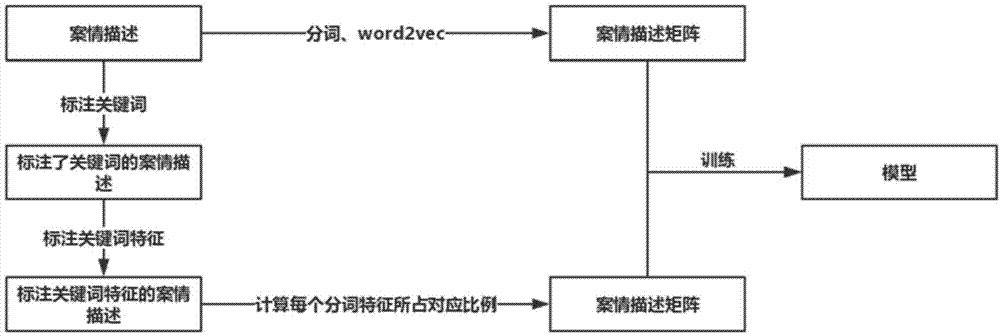
图2为本发明的提取受贿犯罪程度关键词建立模型过程的结构图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
一种面向案情的关键词提取方法,以提取第三关键词犯罪程度为例,包括以下步骤:
步骤1:对用于训练模型的案情描述手动进行关键词标注,标注出第一关键词犯罪嫌疑人、第二关键词犯罪类型、第三关键词犯罪程度,对案情描述采用ltp进行分词,然后采用word2vec将案情描述中的每个分词转换成词向量,然后每条案情描述的所有分词的词向量拼接起来,构成了案情描述的词向量矩阵。
步骤2:对第三关键词犯罪程度进行词法特征计算,计算第三关键词犯罪程度的关键词的长度、关键词的词性、在原文档中位于第一关键词犯罪嫌疑人和第二关键词犯罪类型的哪个位置、与第一关键词的距离、与第二关键词的距离、与案情描述开头的距离、与案情描述结尾的距离,得到第三关键词犯罪程度的七个特征。
其中,(1)关键词的长度就是看关键词包含多少个字;(2)关键词的词性用ltp可以自动对词语进行词性标注;(3)在原文档中位于第一关键词犯罪嫌疑人和第二关键词犯罪类型的哪个位置指的是,假如第三关键词犯罪程度在另外两个关键词之前出现在原句中时关键词该特征就标注为1,在另外两个关键词中间出现在原句中时该特征就为2,在原句中位于另外两个关键词后面时该特征就标注为3;(4)与第一关键词的距离指的是,要提取的犯罪程度关键词与犯罪嫌疑人中间有多少个字;(5)与第二关键词的距离指的是,犯罪程度关键词与第二关键词(犯罪类型)中间有多少个字;(6)与案情描述开头的距离是,要提取的犯罪程度关键词距离案情描述开头有多少个字;(7)与案情描述结尾的距离是,犯罪程度关键词距离案情描述结尾有多少个字。
步骤3:分别计算案情描述中除了第一关键词犯罪嫌疑人和第二关键词犯罪类型之外其他每个分词的七个特征:长度、词性、在原文档中位于第一关键词犯罪嫌疑人和第二关键词犯罪类型的哪个位置、与第一关键词的距离、与第二关键词的距离、与案情描述开头的距离、与案情描述结尾的距离。计算每个分词的每个特征在第三关键词犯罪程度的七个特征中对应的特征中所占的比例,并将得到的每个分词的七个比例数字组成一个关于该分词词法特征的七维向量,作为每个分词的词法特征向量,第一关键词犯罪嫌疑人和第二关键词犯罪类型的词法特征向量全部设置为0,每一条案情描述中所有分词的词法特征向量拼接起来,得到该条案情描述的词法特征矩阵。
步骤4:安装python库中的keras包。将案情描述的词向量矩阵放入到一个keras的模型中去,案情描述的词法特征矩阵也放入到一个keras中的模型中去,然后将两个模型利用keras中的merge功能,将两个模型合并为一个模型,然后将合并后的模型运用keras中的fit功能来训练模型。
步骤5:对待预测第三关键词犯罪程度的案情描述进行分词和运用word2vec转换成词向量矩阵,并且和已标注的另外两个关键词一起输入到步骤4训练完成的模型中,利用keras中的predict功能来预测在待预测第三关键词的案情描述的分词结果中哪一个词是要提取的第三关键词犯罪程度,得到每个分词是第三关键词犯罪程度的概率,概率最大的就作为提取的第三关键词犯罪程度。
如图2所示,展示了一个关于提取受贿犯罪程度关键词建立模型过程的具体实例。提取第三关键词犯罪类型时将犯罪嫌疑人和犯罪程度分别作为第一关键词和第二关键词,过程与提取犯罪程度是相同的。
本发明针对传统的关键词提取只是利用词频和逆文件频率(tf-idf)来对文中的关键词进行提取,而没有考虑词语的特征。本发明方案是对犯罪案情描述进行关键词提取,主要提取犯罪嫌疑人、犯罪类型和犯罪程度。犯罪嫌疑人通过ltp命名实体识别功能找出,通常实体识别出来的第一个名词就是犯罪嫌疑人。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!