一种基于投资者讨论内容打分的个股大跌预测模型的制作方法
本发明涉及股票预测领域,尤其涉及一种基于投资者讨论内容打分的个股大跌预测模型。
背景技术:
随着计算机技术和信息技术的发展,量化投资在金融行业得到更加广泛的应用。在上世纪70年代之前,股票金融领域主要以传统的定性投资为主,即通过基本面来进行分析,对上市公司进行调研,了解和分析各类研究报告,来达到对感兴趣公司股票行情的了解,该方式存在着较大的局限性,即每次研究的股票数量有限。上世纪70年代之后,以詹姆斯西蒙斯为主导的大奖章(medallion)对冲基金转变为定量投资,开启了量化投资的新纪元,即利用电脑帮助人脑处理大量的信息。定量搜集海量相关数据,建立数据分析模型,然后借助于计算机强大的数据处理和信息挖掘能力来选择投资方式。用计算机理性判断来代替人的主观思维判断。目前对于股票的预测,大都是基于股票的历史股价信息,股票的市值、市赢率等,结合投资者的购买情况,有许多的片面性。当前,移动互联的高速发展,让更多的投资者可以随时随地分享他们对股票的看法,与更多兴趣人士进行交流。这些看法、交流的信息,汇总形成一个讨论信息的数据库。股票价格波动由很多因素构成,每次价格的波动无不例外都与当前政治、经济、公司自身情况等因素相关。而股民讨论的信息数据恰恰可以反映投资者对当前状况的想法,从而可以从侧面反映出当前公司股票的市场行情。在股市中,“黑天鹅”事件一般都具有意外性和产生重大影响性。它可能由政府决策、突发安全事件,公司内部违法事件曝光等引起。遇到“黑天鹅”事件,投资者就要及时抛售手中的股票,并且越快越好。现有对于股票的预测很少融入投资者近期的评论情况,为了利用股票论坛上活跃的投资者评论,投资者对股票涨跌的看法以及投资者购买、持有、抛出的趋势,来更进一步补充以往历史交易情况、历史股价等数据对于某个股票接下来一段时间的预测,为了更好地预测出接下来最为悲观的股票名单,来帮助投资人避险。
技术实现要素:
本发明融入了投资者近期的评论情况,更进一步补充以往历史交易情况、历史股价等数据对于某个股票接下来一段时间的预测,更好地预测出接下来最为悲观的股票名单,帮助投资人避险,满足实际使用需求。
为了实现上述目的,本发明采用了如下技术方案:
一种基于投资者讨论内容打分的个股大跌预测模型,包括如下步骤:
步骤(1)、获取投资者讨论股票数据和股价信息数据:
(1.1)获取各个股票的股价及交易信息:通过从网易财经网站上下载csv格式的股票历史交易数据,数据包括收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额等,然后将这些历史交易数据导入到mongodb数据库中;
(1.2)爬取各大股票网站、论坛、投资平台的投资者讨论数据:爬取各大股票相关的投资网站、论坛、平台等投资者的讨论数据,例如对于股票的涨跌或者是新闻的讨论等;为解决某些网站的访问限制,我们通过模拟登陆获取cookie值和使用动态转发代理形式,来进行爬取;其次,因为投资者的讨论数据是一种增量的过程,对于某个网页,随着时间的推移,投资者的讨论数量也会不断增加;为此,又新增了讨论数据增量爬取模块;
步骤(2)、对投资者讨论数据建模,并对股票进行投资者情感打分,具体步骤如下:
(2.1)利用文本标注平台对部分投资者讨论数据进行看涨看跌等的标注,构成训练数据:搭建一个简单的文本标注web平台,该平台从数据库中直接按条取出文本数据,页面展示讨论数据,便于用户一条条进行标注,标注好后存入数据库,并且具有任务分发功能,可以将文本数据发送给多人,多人同时标注,标注的类别为看涨、看跌、持有、观望和无关这五类态度,无关表示文本内容和投资者对该股票的涨跌无关,标注的数据在万条以上;
(2.2)利用卷积网络构建文本分类器,利用标注好的讨论数据进行训练:构造一个卷积神经网络来作为我们的文本分类器,第一层为字嵌入层,将句子的每个字符做一个字嵌入,映射成一个一维向量,整个句子形成一个二维矩阵,每一行为一个字向量;接着加一层卷积层,提取句子特征以及句子中每个字的前后结构信息;然后加一个池化层,最后是全连接和softmax层,训练时将文本统一到相同的长度,将标注数据分为训练集和验证集,利用训练集训练,用验证集来调整超参数;
(2.3)利用训练好的文本分类器,对每天每个股票的不同平台的讨论数据进行分类,然后计算看涨看跌的得分,得到每只股票每天每个平台的讨论情感分;利用训练好的分类器对所有的讨论数据进行分类,可以得到每条讨论数据是看涨、看跌、持有、观望和无关中的一种,然后按照看涨给0.9分,看跌给0.1分,持有给0.7分,观望给0.55分,无关给0分,将单个股票当日所有的讨论数据对应分加起来,得到该股票当日的讨论情感分,分数越大说明投资者对该股票越看好;
步骤(3)、利用投资者讨论得分和其他信息对股票是否会大跌进行建模及预测:
(3.1)利用交易日t前n天的各平台情感分序列,前n天的历史交易序列,历史交易数据,来进行建模,建模目标为后三天t+3内是否大跌:构造一个基于lstm的循环神经网络来对股票三天内是否大跌这个二分类问题进行建模。若股票在后三天内股价跌幅最大超过了5%则认为大跌,否则即为未大跌。由步骤二得到的每支股票每天的讨论情感分,取交易日t前n天的各个网络平台的讨论情感分序列,以及前n天的股票的收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额序列作为模型的输入。在输入层后加一层lstm层,lstm单元的个数为n,lstm能够有效地提取时序信息。在lstm层后加一层全连接层,最后加dropout层和softmax进行二分类;
(3.2)将所建预测模型用于当前股票数据上,概率越高说明该股票在接下来的三天越有可能大跌,提供给投资人,助其避险;将当前股票的前n天的各平台讨论情感分序列,和前n天的股票的收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额序列输入模型,预测接下来三天是否会大跌的概率,超过80%即认为非常有可能大跌。
作为上述技术方案的改进,步骤(1.2)中主要方式为重新访问之前已经爬取的网页,查看网页中是否有新增的讨论内容,若有则更新mongodb中的数据,并且将新增的讨论数据插入到mysql数据库中。
作为上述技术方案的改进,步骤(2)主要包括爬虫爬取的投资者讨论数据,其包含了投资者对每个股票的看法,例如投资者对该股票看好,会买入,或者觉得该股票会跌,打算抛出,或者是根本不相关的,例如“呵呵”“你运气真好”等;这些讨论数据都是长短不一的文本,为了更好地提取出投资者的看法,构建一个文本分类器,输入为投资者发表的讨论文本,输出为看涨、看跌、持有、观望和无关这5个选项中的一个,然后利用分类器对新的讨论数据进行分类,并给出打分,描述投资者对于该股票的情感分。
本发明的有益效果:利用了一段时间内的各大股票投资网站和论坛上,投资者对于股票的讨论信息,利用卷积神经网络将讨论数据分类为看涨、看跌、持有、观望、无关等投资者态度,对于判断接下来股票是否会大跌提供了更多的信息,并且结合股票过去一段时间的股价变化信息,采用单向的lstm循环神经网络,更好地利用了时序特征,使得预测更加准确利用了一段时间内的各大股票投资网站和论坛上,投资者对于股票的讨论信息,利用卷积神经网络将讨论数据分类为看涨、看跌、持有、观望、无关等投资者态度,对于判断接下来股票是否会大跌提供了更多的信息,并且结合股票过去一段时间的股价变化信息,采用单向的lstm循环神经网络,更好地利用了时序特征,使得预测更加准确。
附图说明
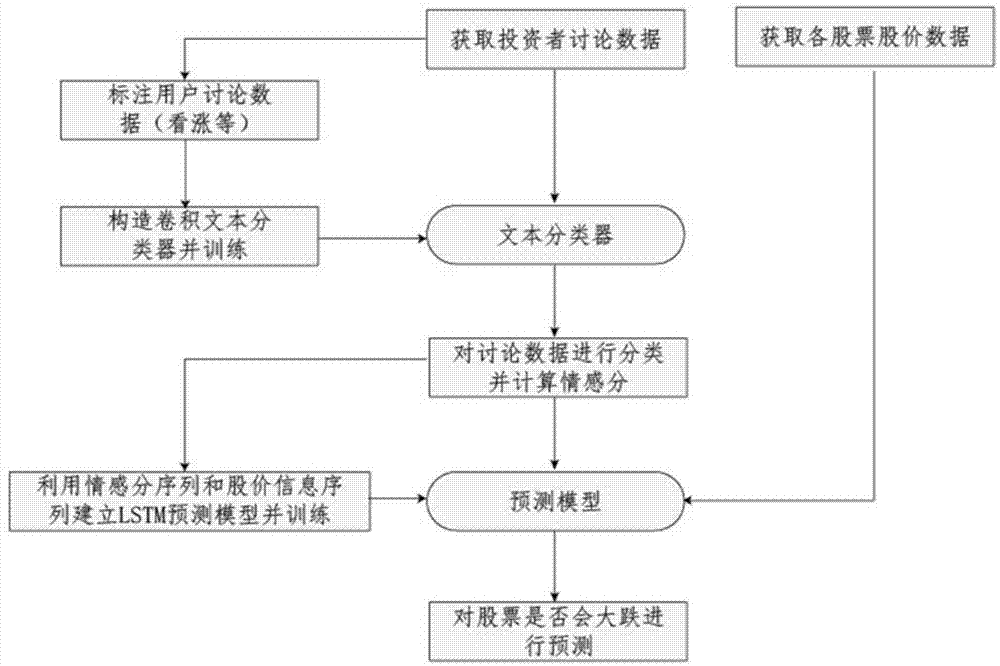
图1为本发明整体流程示意图;
图2为本发明股票讨论数据爬取框架图;
图3为本发明卷积文本分类器结构示意图;
图4为本发明循环神经网络预测模型结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1至图4所示:首先,获取股票价格等数据,通过从网易财经网站上下载csv格式的股票历史交易数据,数据包括收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额等,然后将这些历史交易数据导入到mongodb数据库中。
其次,获取投资者讨论数据:图2为本发明的股票讨论数据爬取框架,为解决某些网站的访问限制,本爬虫系统采用了两种措施:第一种,通过获取手机验证码来全自动模拟登陆股票网站,得到登陆后的cookie值,并将这些cookie值都存放在本地的mongodb数据中,每次爬取时都随机选择一个cookie值放入请求头中,若出现异常,则删除该cookie值,并重新随机选取;第二种,使用动态转发代理,通过动态转发服务器,让它随机选择ip结点,来访问所需的目标网站。同时,由于投资者在对某个公告、新闻等的讨论数据也是一种增量的过程;为此,本发明又增加了讨论数据增量爬取模块,该模块将mongodb中保存的30天的数据根据它们的url,重新查看网页中是否有新增的讨论数据,若有则重新更新mongodb中的数据并且把新增的数据插入到mysql数据库中;爬虫模块每天定时爬取前24小时的股票的讨论数据,将这些讨论数据存储到mongodb数据库中,并在每条数据中设置一个计数器,每天将计数器的值加1,当计数值大于1小于等于30时也就是前2~30天内的讨论数据自动存放到另外一个数据库,该数据库作为一种中间数据库,存放的是一些较新的数据,最后将超过30天的数据转存到mongodb里面另一个历史数据库中。
然后,利用文本标注web平台对各网站的投资者讨论数据进行标注,将其标为看涨、看跌、持有、观望和无关五类中的一个。我们将这些讨论数据分发给三个人进行标注,为了使得标注的结果更加准确,对每条记录的标注结果,取标注最多的那个类作为标注结果,标注数据为2万条。
接着,如图3所示:构造一个卷积神经网络,第一层为字嵌入层,将句子的每个字符做一个字嵌入,映射成一个128维的一维向量,整个句子形成一个二维矩阵,每一行为一个字向量,句子长度统一成20,超过20个字符的去掉后面的,不够的用占位符填充;接着加一层卷积层,共使用了3个卷积核,每个卷积的大小为3*128,4*128和5*128,使得卷积的结果为一个个列向量,将这些列向量头尾连接在一起作为下一层的输入;接着为一层池化层,将数据维度降低,最后加一层全连接层,用softmax来得到分类概率;训练时利用标注好的2万条样本,1.8万条样本用于训练,2千条样本用来验证,训练时使用的目标函数为交叉熵,优化算法为adam。
然后,利用训练好的文本分类器,对每个股票的每个网络平台的每条讨论数据进行分类,得到每条讨论数据是看涨、看跌、持有、观望和无关中的一种,按照看涨给0.9分,看跌给0.1分,持有给0.7分,观望给0.55分,无关给0分,将单个股票当日所有的讨论数据对应分加起来,得到该股票当日的讨论情感分;若某股票的评论数特别少,则放弃对于该股票的计算,不将该股票纳入考虑范围。
接着,如图4所示:我们构造一个基于lstm的循环神经网络来对股票三天内是否大跌的二分类问题建模。若股票在后三天内股价跌幅最大超过了5%则认为大跌,否则即为未大跌。本实施例中n取14,输入层为14个输入单元,每个单元由当前交易日前i天的每个网络平台的投资者讨论情感分、股票的收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额组成;接着输入到lstm层,激活函数选择tanh;然后加一层全连接层,最后加上dropout和softmax层。分类的目标损失函数选择为交叉熵,优化算法选择为adam,我们选取过去一年内股票出现大跌的数据和未大跌的数据进行训练。
最后,将所建预测模型用于当前股票数据上,将当前股票的前14天的每个平台的讨论情感分序列,和前14天的股票的收盘价、开盘价、最高价、最低价、涨跌幅、成交量、成交额序列输入模型,预测接下来三天是否会大跌的概率,超过80%即认为非常有可能大跌。
附注:本发明的核心点在于利用了各大股票投资网站和论坛的投资者讨论数据,来对股票是否会大跌进行预测;利用卷积网络对投资者讨论数据分类,分成看涨、看跌、持有、观望、无关等投资者态度,并且结合股票过去一段时间的股价变化信息,采用单向的lstm循环神经网络进行建模,更好地利用了时序特征,使得预测更加准确。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!