一种基于深度学习的混合动作捕捉系统的制作方法
本发明涉及计算机技术领域,尤其涉及一种基于深度学习的混合动作捕捉系统。
背景技术:
传统的计算机视觉三维重建具有高精度、高成本、高延时的特点,而虚拟现实采用的动作捕捉技术具有成本低、延时低和高精度的特点。目前国内主要的动作捕捉技术可分为惯性动作捕捉技术,光学动作捕捉技术等运动捕捉方式。惯性动作捕捉技术采用惯性传感器采集运动对象各个关节的运动信息,捕捉精度不高,但是实时性好,可采集遮挡的运动;光学动作捕捉采用一个或多个摄像头拍摄运动对象同一个接收点产生的视差计算其空间位置和旋转信息,捕捉精度高,但是易受动作遮挡影响。
技术实现要素:
有鉴于此,本发明实施例期望提供一种基于深度学习的混合动作捕捉系统,本发明的技术方案是这样实现的:
一种基于深度学习的混合动作捕捉系统,所述系统包括:
惯性动作捕捉模块,用于获取对象的惯性姿态信息;
光学动作捕捉模块,用于获取所述对象的光学姿态信息;
通讯模块,用于发送所述惯性姿态信息、光学姿态信息至分析模块;
分析模块,用于根据预设的混合模型对所述惯性姿态信息、光学姿态信息进行融合处理,得到所述对象的最优运动估计。
上述方案中,所述惯性动作捕捉模块,包括:
惯性测量单元,所述惯性测量传感器固定在所述对象上,用于获取所述对象的角速度信息、加速度信息和磁力信息。
上述方案中,所述惯性测量传感器包括:
三轴陀螺仪、三轴加速度计、三轴磁力计。
上述方案中,所述光学动作捕捉模块,包括:光学测量标记和光学摄像头,所述光学测量标记贴在所述对象的关节处,用于获取所述对象的光学姿态信息。
上述方案中,所述光学动作捕捉模块,还用于:获取所述对象的三维位置信息和运动矢量信息。
上述方案中,所述光学摄像头的数量为一个或者多个。
上述方案中,所述分析模块对所述惯性姿态信息、光学姿态信息进行融合处理之前,还包括:
基于多个样本对象的惯性姿态信息、光学姿态信息进行学习训练,获得所述混合模型。
上述方案中,所述系统还包括:
图像处理模块,用于创建三维场景,根据最优运动估计创建所述对象的虚拟体,并生成将所述虚拟体合成至所述三维场景中的图像。
上述方案中,所述系统还包括:
vr模块,用于显示根据所述图像处理模块生成的所述图像。
本发明实施例所提供的一种基于深度学习的混合动作捕捉系统,所述系统包括:惯性动作捕捉模块,用于获取对象的惯性姿态信息;光学动作捕捉模块,用于获取所述对象的光学姿态信息;通讯模块,用于发送所述惯性姿态信息、光学姿态信息至分析模块;分析模块,用于根据预设的混合模型对所述惯性姿态信息、光学姿态信息进行融合处理,得到所述对象的最优运动估计。如此,通过综合利用惯性动作捕捉不受遮挡和光学动作捕捉数据准确的特点,并且经过深度学习训练,得到综合了惯性动作捕捉和光学动作捕捉的混合模型,保证了最终数据的精确性。
附图说明
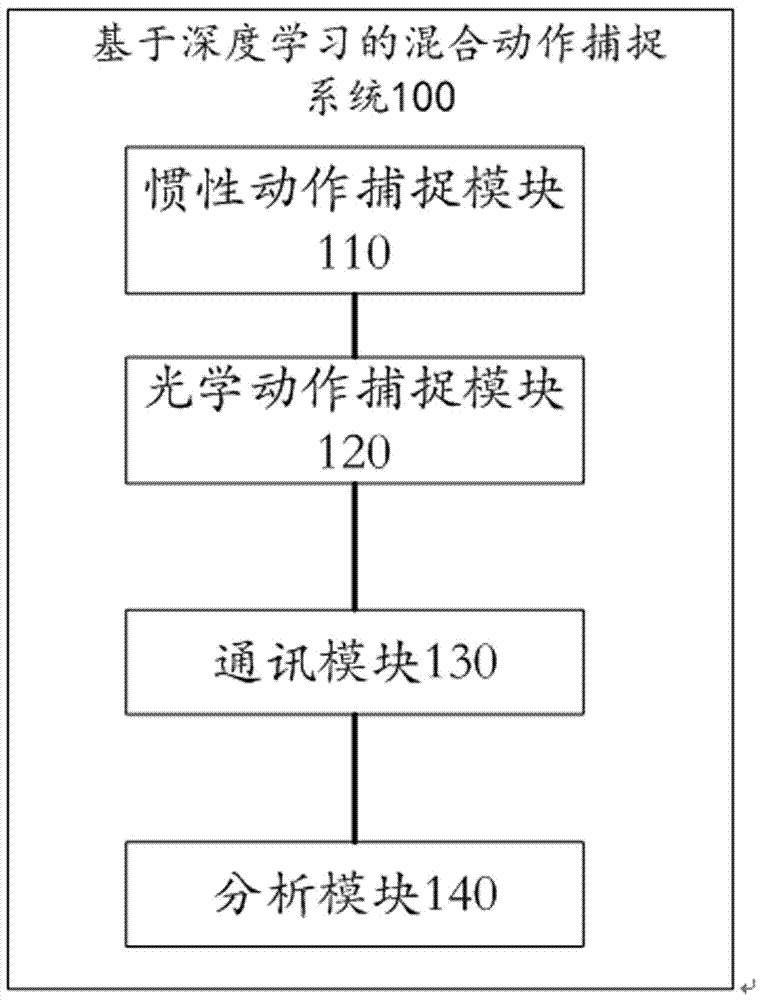
图1为本发明实施例基于深度学习的混合动作捕捉系统组成示意图;
图2为本发明实施例基于深度学习的混合动作捕捉系统的惯性动作捕捉模块组成示意图;
图3为本发明实施例基于深度学习的混合动作捕捉系统的光学动作捕捉模块组成示意图;
图4为本发明另一实施例基于深度学习的混合动作捕捉系统组成示意图;
图5为本发明另一实施例基于深度学习的混合动作捕捉系统组成示意图。
具体实施方式
下面结合实施例对本发明再作进一步详细的说明。
本发明实施例提供的基于深度学习的混合动作捕捉系统100,如图1所示,所述系统100包括:
惯性动作捕捉模块110,用于获取对象a的惯性姿态信息。
这里,如图2所示,惯性动作捕捉模块110包括:惯性测量单元210,所述惯性测量单元210固定在所述对象a上,用于获取所述对象a的角速度信息、加速度信息和磁力信息。所述惯性测量单元210包括:三轴陀螺仪211、三轴加速度计212、三轴磁力计213。
具体的,所述惯性测量单元210中包括姿态传感器,所述姿态传感器为9轴传感器,包括三轴陀螺仪211、三轴加速度计212、三轴磁力计213,所述惯性测量单元210根据对象a的动作轨迹采集角速度信息、加速度信息和磁力信息,即对象a的骨骼姿态信息。三轴陀螺仪211、三轴加速度传感器212和三轴磁力计213分别对人体接触部位的加速度、角速度和地磁场强度进行采集。
另外,所述姿态传感器也可以是ahrs传感器,通过所述ahrs传感器获取对象a的骨骼姿态信息。
进一步的,所述惯性测量单元210的数量和固定在对象a上的位置可以根据实际应用场景进行设定,一般设置为至少4个,用来捕捉对象a的四肢、躯干和头部的动作信息。可以将所述惯性测量单元体210的数量设置为四个,分别固定在对象a的双大臂、双小腿,用来捕捉对象a四肢的动作姿态信息。也可以将惯性测量单元210的数量设置为8个,固定在对象a的双大臂、双小臂、双大腿、双小腿的关节处,用来捕捉对象a更加详细的动作姿态信息。
例如,设置惯性测量单元g的数量为10个,分别固定在对象a的双大臂、双小臂、双手、双大腿、双小腿的关节处,用来获取对象a运动轨迹的角速度信息、加速度信息和磁力信息。
光学动作捕捉模块120,用于获取所述对象a的光学姿态信息。
这里,如图3所示,光学动作捕捉模块120包括:光学测量标记310和光学摄像头320,所述光学测量标记310贴在所述对象a的关节处,用于获取所述对象a的光学姿态信息,所述光学摄像头320的个数为一个或者多个。
这里,光学动作捕捉模块120还可以捕获对象a的三维位置信息和运动矢量信息。
具体的,光学测量标记的数量可以是多个,分别贴在对象a的关节处,所述光学摄像头可以根据追踪光学测量标记的运动来捕捉对象a的光学姿态信息。
进一步的,所述光学测量标记310可以是反光标记,反光标记的数量可以是多个,例如是四个,分别贴在对象a的关节处,这样,可以降低反光标记在对象a运动的过程中,反光标记被遮挡的可能性。光学摄像头320的数量可以是一个或者多个,当有多个光学摄像头320时,可以将所述多个光学摄像头320排列成扇形,使得对象a的活动范围在所述多个光学摄像头320可以追踪的空间范围之内。所述光学姿态信息还包括对象a的三维位置信息和运动矢量信息。
例如,设置光学测量标记l的数量设置为4个,分别标记在对象a的双肩、前胸、后背上,光学摄像头c的数量设置为2个,分别排列在一个房间的对角线上,光学摄像头c可以根据光学测量标记来追踪对象a的光学姿态信息,所述光学姿态信息还包括对象a的三维位置信息和运动矢量信息。
通讯模块130,用于发送所述惯性姿态信息、光学姿态信息至分析模块140。
具体的,在惯性运动捕捉模块和光学运动捕捉模块上分别都设置有通信单元,将所述惯性测量单元获取的对象a的惯性姿态信息和所述光学运动捕捉模块获取的对象a的光学姿态信息发送至分析模块140。通信单元与分析模块140的连接方式可以是通过无线网络、蓝牙、usb等连接方式进行数据的传输。具体的连接方式,可以根据实际的应用和采用的惯性测量单元和光学摄像头的型号和装置进行选择。
例如,惯性运动捕捉模块g将所述对象a的惯性姿态信息通过无线通信网络发送至分析模块e,光学摄像头c将所述对象a的光学姿态信息通过usb接口进行有线数据传输,将所述光学姿态信息发送至分析模块e。
分析模块140,用于根据预设的混合模型对所述惯性姿态信息、光学姿态信息进行融合处理,得到所述对象a的最优运动估计。
这里,分析模块140对所述惯性姿态信息、光学姿态信息进行融合处理之前,还包括:基于多个对象的样本惯性姿态信息、光学姿态信息进行学习训练,获得所述混合模型m。
具体的,分析模块140可以预先采集不同对象的惯性姿态信息和光学姿态信息,进行学习训练,采用的深度学习神经网络可以根据不同的精度进行不同的选择,例如,选择卷积神经网络,得到不同对象的混合模型m。
进一步的,决定混合模型m的是采集的样本的惯性姿态信息和光学姿态信,因此,应当确保样本的准确性,在样本数据采集的过程中,应当确保样本对象运动过程中,数据采集的准确性和完整性。
具体的,分析模块140通过数据滤波传感器将获取到的加速度、角速度和地磁场强度信息进行初级滤波处理,然后将处于正常范围内的加速度、角速度和地磁场强度信号信息,生成四元数或者欧拉角,然后通过卡尔曼滤波器采用卡尔曼滤波算法将接收到的加速度、角速度和地磁场强度数据进行深层次滤波与融合,生成对象a的惯性姿态信息。
具体的,分析模块140根据对象a的惯性姿态信息和光学姿态信息根据预设的模型m进行融合处理,得到对象a的最优运动估计。
例如,分析模块e首先根据采集到的样本数据进行学习训练,得到混合模型m。然后,根据获取到的对象a的惯性姿态信息和光学姿态信息进行处理,得到对象a的最优运动估计。
如此,通过综合利用惯性动作捕捉不受遮挡和光学动作捕捉数据准确的特点,并且经过深度学习训练,得到综合了惯性动作捕捉和光学动作捕捉的混合模型,保证了最终数据的精确性。
本发明实施例提供的基于深度学习的混合动作捕捉系统400,如图4所示,所述系统400还包括:图像处理模块410,用于创建三维场景,根据最优运动估计创建所述对象a的虚拟体,并生成将所述虚拟体合成至所述三维场景中的图像。
具体的,图像处理模块410、分析模块140都可以运行于上位计算机,上位计算机上可以设置有存储器,所述存储器上可以存储有预先拍摄的场景的图片,图像处理模块410可以根据所述图片通过算法创建三维场景;或者,所述图像处理模块可以与摄像头相连接,实时根据摄像头拍摄的图片创建三维场景。
具体的,图像处理模块410可以通过对象a的最优运动估计数据创建所述对象a的虚拟体,并且将所述虚拟体合成至创建的三维场景的图像中。
例如,图像处理模块p运行于上位计算机m上,基于上述实施例得到所述对象a的最优运动估计,图像处理模块p通过存储器上存储的图片创建三维场景s,通过对象a的最优运动估计得到对象a的虚拟体,并将所述虚拟体合成至三维场景s中。
如此,可以根据不同的图片生成不同的三维场景,将通过深度学习得到的精确的最优运动估计创建对象的虚拟体,可以将所述虚拟体合成至不同的三维场景中,这样,就可以得到不同场景下的虚拟体运动,增加了所述系统的应用场景。
本发明实施例提供的基于深度学习的混合动作捕捉系统500,如图5所示,所述系统500还包括:vr设备510,用于显示根据所述图像处理模块410生成的所述图像。
具体的,所述vr设备510的型号可以根据实际应用进行选择,所述vr设备510可以跟图像处理模块410相连,vr设备510上设置有显示屏,通过所述显示屏,将图像处理模块410生成的图像进行显示。
例如,vr设备r与上位计算机m相连,vr设备佩戴在对象a头上,vr设备的显示屏上显示上述实施例创建的三维图像s。
如此,可以根据不同的图片生成不同的三维场景,将通过深度学习得到的精确的最优运动估计创建对象的虚拟体,可以将所述虚拟体合成至不同的三维场景中,这样,就可以得到不同场景下的虚拟体运动,并且可以将所述三维场景显示在vr设备上,大大提高了用户体验感。
以上所述,仅为本发明的最佳实施例而已,并非用于限定本发明的保护范围,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!