一种分布式大数据计算引擎及架构方法与流程
本发明涉及计算引擎架构,尤其涉及一种分布式大数据计算引擎及架构方法。
背景技术:
目前越来越多的企业都认识到了大数据对于自身未来发展的重要性,于是纷纷开始使用并逐渐依赖大数据处理相关技术。但随着需要处理数据越来越多,业务场景也越发复杂,在实际执行过程中也遇到了很多问题,如大数据人才紧缺、导致人力成本高,相关技术缺乏沉淀,短期内又难以培养一支较为成熟的大数据团队,同时不同业务部门的业务需求繁多且各异,导致不同项目代码重复开发、重复造轮子、项目技术架构五花八门的情况也较为常见,给后期维护和迭代带来很大的挑战。
随着大数据处理技术的发展和成熟,由于以上的现实问题,我们认为有必要基于博睿数据过往众多实际大数据项目经验,抽象和设计出一套灵活轻便、场景通用、稳定高效的统一大数据处理引擎框架来解决这些问题。
现有技术中,大数据处理引擎完全基于内存计算,吞吐量不如传统批量计算框架,如spark、mapreduce等;且其内置聚合时间粒度固定,无法变更,也无法支持天粒度以上更大粒度聚合;对mq的支持仅限于kafka,后期可考虑支持其他mq;此外,现有技术仅适合做结构化时序指标数据处理,对其他如非结构化大数据处理场景并不支持。
技术实现要素:
为了解决上述技术所存在的不足之处,本发明提供了一种架负责范围包括原始数据预处理、准实时计算、多种时间粒度批量计算、数据落地及各种容错处理的分布式大数据计算引擎及架构方法。
为了解决以上技术问题,本发明采用的技术方案是:一种分布式大数据计算引擎,包括:
分布式协调服务集群,用于为分布式应用提供协调服务、保存相关插件程序和业务数据库对象集合schema配置文件,所述协调服务包括配置服务、分布式同步、节点监控;
消息中间集群,为一个分布式的、支持多分区的、多副本的,基于的分布式消息系统,用于传输不同类型的业务数据,所述业务数据包括原始数据、计算结果、快照数据、基线数据和报警数据;
流式计算集群,基于storm的底层计算框架,用于将时序指标大数据处理过程抽象为以下几个主要流程:预处理、准实时计算、小批量计算、大批量计算、落地入库;流式计算集群包括预处理拓扑、统计拓扑、储存拓扑;
可视化控制模块,用于将数据通过web的方式进行展现和管理;
数据缓存集群,为流式计算集群辅助内存存储集群,用于降低大批量计算时对流式计算集群内存的开销。
进一步地,所述流式计算集群中:
预处理拓扑用于从消息中间集群订阅原始数据源并对数据进行预处理,将预处理结果进行准实时聚合处理;
统计拓扑用于对预处理之后的数据进行按不同时间粒度的批量聚合,包括两个子计算拓扑:小批量计算拓扑和大批量计算拓扑。
存储拓扑用于语言数据落地入库,对于最终计算结果落地提供基本框架支持;落地数据包括时序指标数据和快照文件数据两种。
进一步地,所述预处理拓扑中,预处理用插件由用户开发,计算规则由用户在数据库对象集合schema中描述,负责对每一条原始数据执行具体的清洗策略。
进一步地,预处理拓扑在数据预处理后把数据镜像一份发往消息中间集群,由用户进行后续备份处理。
进一步地,所述统计拓扑中,中小粒度的中间计算结果都会缓存到数据缓存集群中,供下一大粒度计算使用;同时,各粒度计算结果会落地到消息中间集群中,由存储拓扑订阅进行后续存储操作,从而实现数据计算和落地之间的解耦。
进一步地,数据缓存集群缓存各粒度中间计算结果,以备下一时间粒度计算直接使用,从而减少数据处理量级。
进一步地,所述流式计算集群还包括基线拓扑和/或报警拓扑。
本发明的内容还包括上述分布式大数据计算引擎的架构方法,包括:
明确源数据格式,对数据需要做统一格式的封装,并标识数据时间戳;
配置数据源中各业务数据具体处理规则的schema.xml文件,所有数据指标和维度的运算处理规则都由此文件进行描述;
通过实现提供的数据预处理插件接口类,来开发数据预处理插件,数据预处理插件运行在数据预处理拓扑中,负责对每一条原始数据执行具体的清洗策略;
用户通过实现提供的自定义算子插件接口类,来开发自定义算子插件;自定义算子插件运行在数据计算拓扑中,负责实现用户对数据指标和维度处理所需的自定义算子;所述自定义算子插件会接收到一批数据,将这些数据按自定义的计算规则计算后,将结果返回给调用者。
最终计算结果落地内置支持mysql存储方案,如采用mysql作为最终落地数据库,则建表和结果数据入库过程均可由框架自动完成;如需采用其他落地方案,则通过实现运行在数据存储拓扑中数据存储插件接口类,来开发数据存储插件,负责计算后的数据进行存储。
进一步地,数据存储插件接收到最终计算结果数据,并将数据按自身业务需要进行存储。
进一步地,所述方法还包括,用户根据自身业务需求来开发可扩展的拓扑来自定义处理或计算数据,并以独立计算拓扑的方式提交给引擎,由于引擎加载运行。
进一步地,所述方法还包括配置app.xml文件中基础依赖集群地址和各计算拓扑运行时的关键控制参数,通过脚本启动运行各业务拓扑。
本发明提供了一种分布式大数据计算引擎,引擎整体架构设计大量采用插件和扩展机制,其将与业务强关联的个性化处理,如数据预处理策略抽象为预处理插件,将数据和维度指标处理的算子开放为统计插件,而将处理结果落盘策略抽象为存储插件。同时,在支持插件技术外,为了丰富引擎框架功能,还支持扩展机制。用户可以在现有引擎框架基础上开发自己需要的插件,并以独立计算拓扑的方式提交给引擎,由于引擎加载运行,从而实现功能的延伸。
此外,bonreeants还支持插件动态更新和schema.xml动态更新功能,这样能够帮助用户实现不重启即可更新业务处理逻辑的支持,对用户复杂多变的业务场景带来极大的灵活性。
本发明的有益效果有:
1、简洁开放的架构,较少的组件依赖,开发部署及维护成本低;
2、引擎框架自身与业务无耦合,数据处理流程高度抽象,通用性强;
3、秒级时延,实时性好,同时内置批量计算支持;
4、支持extension机制,用户可自行丰富业务场景功能支持;
5、内置多种容错策略,保证稳定与数据安全;
6、支持可视化管理和监控;
本发明可以帮助大数据技术积累较少的企业,或者项目周期和人力紧张的项目团队便捷快速的实现海量时序指标数据的在线流式处理。对于常见的时序指标流式处理的业务场景可不需要研发人员参与,只需非研发业务人员对数据应用进行简单配置和业务脚本描述,即可实现其目标;而对于复杂业务场景我们则希望通过研发人员通过引擎的插件机制,进行少量编码来实现相关与业务强关联的逻辑,而将大数据处理中底层复杂的资源调度、任务编排、容错处理交给引擎负责,快速实现相关大数据处理业务开发,极大降低企业相关开发和维护成本。通过在众多内部项目的实践,应用本发明的引擎框架之后,大数据处理开发工作量整体降低了80%,整体项目周期缩短40%以上。
附图说明
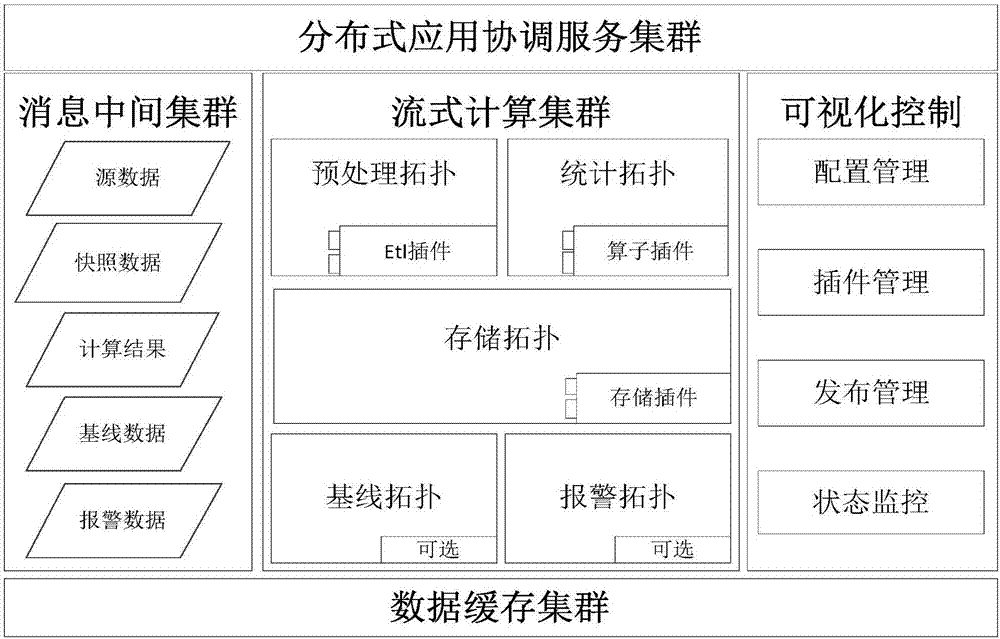
图1为本发明的分布式数据引擎架构图的示意图。
图2为本发明的分布式数据引擎连接关系流程图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。
【实施例1】
如图1所示,分布式数据引擎框架主要由分布式协调服务集群(zookeeper)、消息中间件集群(kafka)、流式计算集群(storm)、数据缓存集群(redis)、可视化控制等五部分组成,其中zookeeper、kafka、storm、redis等都是当前比较流行的开源组件。其中,
分布式协调服务集群:zookeeper是一个分布式应用程序协调服务,为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如配置服务、分布式同步、节点监控等分布式基础服务。在分布式数据引擎中它除了用来维护kafka集群和storm集群的状态外,我们还用它来保存相关插件程序和业务schema.xml配置文件。实现了插件和schema.xml可以动态生效,不用重启拓扑程序,从而降低了拓扑维护难度和因重启拓扑带来的数据丢失问题。
消息中间件集群:kafka是一个分布式的、支持多分区的、多副本的,基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。所以它是一种高吞吐量的分布式发布和订阅消息系统。其稳定性和效率,也是被业内认可度最高的消息中间件。可以传输不同类型的业务数据,如:原始数据、计算结果、快照数据、报警数据等,它不仅可以保证数据的实时性、安全性(数据不会丢失),还能起到缓冲访问压力的目的,把数据和业务进行了很好的解耦。
流式计算集群:底层计算框架基于storm,之所以选择storm作为底层计算框架,主要考虑到storm自身的实时性高、资源开销小,外部依赖少、纯内存计算、容错性好等特性。分布式数据引擎将时序指标大数据处理过程抽象为以下几个主要流程,即:预处理、准实时计算、小批量计算、大批量计算、落地入库等5个流程。以上流程均由运行于storm之上的preprocessingtopology、calculationtopology、storagetopology三类拓扑负责完成。
预处理拓扑(preprocessingtopology):此拓扑负责从kafka订阅原始数据源并调用etl-plugin插件对数据进行预处理(etl-plugin插件由客户自己来实现),并对将etl后的结果进行准实时聚合处理(计算规则由用户在schema.xml中描述)。如果用户想要备份etl后的原始明细数据,则只需在schema.xml中开启相关配置,则由此拓扑在etl后把数据镜像一份发往kafka集群指定topic,由用户自行消费进行后续备份处理;
统计拓扑(calculationtopology):此拓扑负责对etl之后的数据进行按不同时间粒度的批量聚合(规则由schema.xml描述)。此过程内部有两个子计算拓扑:小批量计算(分钟级),大批量计算(小时级和天级)。计算过程中小粒度的中间计算结果都会缓存到redis集群中,供下一大粒度计算使用。同时,各粒度计算结果会落地到kafka相应的topic,由“数据存储拓扑”订阅进行后续存储操作,从而实现数据计算和落地之间的解耦。批量计算是基于时间粒度的聚合计算,默认支持1秒、1分钟、10分钟、1小时、1天等五个不同时间粒度的聚合。由于各粒度计算之间存在递进依赖关系,因此为减少计算资源开销,加速计算过程,在redis集群缓存了各粒度中间计算结果,以备下一时间粒度计算直接使用,从而减少数据处理量级。
存储拓扑(storagetopology):此拓扑负责数据落地入库,落地数据包括两种,即时序指标数据(结构化)和快照文件数据(非结构化,如业务中存在此类数据的话)两种,对于最终计算结果落地只提供了基本框架支持。由于不负责最终数据存储,因此也不会对最终数据落地存储组件有任何限制。bonreeants默认内置支持mysql存储方案,如采用mysql作为最终落地数据库,则建表和结果数据入库过程均可由引擎自动完成。如需采用其他落地方案,如hbase等,则由用户开发storage-plugin插件进行自定义支持来实现具体的落盘策略。
缓存数据集群:分布式数据引擎整个数据处理过程中数据不落地,均在内存中完成。由于需支持大时间粒度批量计算业务场景,分布式数据引擎引入redis作为storm集群辅助内存存储集群,以降低大批量计算时对storm集群内存的开销。由于采用内存计算的方式,分布式数据引擎实时性高,对磁盘i/o几乎无影响,但这也带来一定的数据处理吞吐量上的牺牲。
可视化控制模块:整个大数据的相关环境都可通过web的方式进行展现和管理,以解决部署维护繁琐的问题。其具体功能如下:基础配置管理;schema业务配置管理;插件发布管理;拓扑发布管理;storm、kafka、redis等集群运行状态监控;日志业务链追踪。
分布式数据引擎整体架构设计大量采用插件和扩展机制,其将与业务强关联的个性化处理,如数据预处理策略抽象为预处理插件etl-plugin,将数据和维度指标处理的算子(内置支持sum、max、min等基本算子)开放为统计插件operator-plugin,而将处理结果落盘策略抽象为存储插件storage-plugin。同时,在支持插件技术外,为了丰富分布式数据引擎框架功能,还支持扩展机制。用户可以在现有引擎框架基础上开发自己需要的扩展,并以独立计算拓扑的方式提交给引擎,由于引擎加载运行,从而实现功能的延伸。目前,分布式数据引擎默认内置动态基线扩展和报警条件判断扩展。此外,还支持插件动态更新和schema.xml动态更新功能,这样能够帮助用户实现不重启即可更新业务处理逻辑的支持,对用户复杂多变的业务场景带来极大的灵活性。
本实施例中:
app.xml:用于配置基础依赖集群地址和各计算拓扑运行时的关键控制参数;
schema.xml:用于配置数据源中各业务数据具体处理规则,所有数据指标和维度的运算处理规则都由此文件进行描述;
etl(数据预处理)插件:由用户开发,运行在数据预处理拓扑中,负责对每一条原始数据执行具体的清洗策略;
算子插件:此插件可选,由用户开发,运行在数据计算拓扑中,负责实现用户对数据指标和维度处理所需的自定义算子;
存储插件:此插件可选,由用户开发,运行在数据存储拓扑中,负责实现数据处理结果具体的落地入库操作。
【实施例2】
如图2所示,架构的实现包括以下步骤:
(1)、明确源数据格式,由于架构自身对源数据的格式不受限制,所以发送到此构架的数据需要做统一格式的封装,并标识数据时间戳。
(2)、配置数据源中各业务数据具体处理规则的schema.xml文件,所有数据指标和维度的运算处理规则都由此文件进行描述。
(3)、通过实现提供的数据预处理插件接口类,来开发数据预处理插件,它运行在数据预处理拓扑中,负责对每一条原始数据执行具体的清洗策略。在开发此插件时需要根据schma.xml中的配置项把接收到的每条原始数先进行清洗策略,然后将清洗后的数据,封装成特定对象返回给调用者。
(4)、架构设计内置支持sum、max、min等基本算子。如果用户需要特定的算子,可通过实现提供的自定义算子插件接口类,来开发自定义算子插件。它运行在数据计算拓扑中,负责实现用户对数据指标和维度处理所需的自定义算子。此插件会接收到一批数据,将这些数据按自定义的计算规则计算后,将结果返回给调用者。
(5)、架构设计最终计算结果落地内置支持mysql存储方案,如采用mysql作为最终落地数据库,则建表和结果数据入库过程均可由框架自动完成。如需采用其他落地方案,如hbase、elasticsearch等,可通过实现提供的数据存储插件接口类,来开发数据存储插件,它运行在数据存储拓扑中,负责计算后的数据进行存储。此插件会接收到一批数据,将这些数据按自身业务需要进行存储即可。
(6)、架构设计在支持插件技术外,为了丰富引擎框架功能,还支持extensions扩展机制。用户根据自身业务需求来开发可扩展的拓扑来自定义处理或计算数据。它以独立计算拓扑的方式提交给引擎,由于引擎加载运行,从而实现引擎功能的延伸。
(7)、配置app.xml文件中基础依赖集群地址和各计算拓扑运行时的关键控制参数,通过脚本启动运行各业务拓扑。
引擎的中数据处理包括,其中分布式应用协调服务集群用于协调各部分工作:
1.消息中间集群从数据源获取源数据;
2.消息中间集群将源数据传送到预处理拓扑,预处理插件进行处理后,传送给消息中间集群;
3.数据缓存集群从预处理拓扑获得预处理后的结果;
4.计算拓扑或其他扩展拓扑从数据缓存集群或消息中间集群获取数据,处理后俺需要发送回执数据缓存集群;
6.存储拓扑从计算拓扑、其他扩展拓扑或直接从消息中间集群中获取数据;
6.存储拓扑将数据发送至数据仓库。
本发明在storm计算拓扑中引用了插件化和schema业务规则配置这两种处理机制,而且可以动态生效,这对现有的分布式大数据技术开发起到了极大的简化作用。本发明的引擎架构中引入的插件化机制(etl预处理插件,自定义算子插件,存储插件),schema业务规则配置机制,拓扑扩展机制。相关插件、schema业务规则配置、拓扑扩展可动态生效的机制。
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!