一种基于注意力机制和双模态图像的分类方法与流程
本发明涉及图像分类领域,具体涉及一种基于注意力机制和双模态图像的分类方法。
背景技术:
利用不同的成像原理、不同的传感器(设备)对于同一场景所采集到的不同图像即为多模态图像。随着计算机、电子信息等技术的迅速发展,传感器技术也得到飞速发展,图像的模态也越来越多样性,例如,医学图像中的mri(magneticresonanceimaging)图像、pet(positronemissiontomography)图像以及ct(computedtomography)图像等。
面对图像模态的多样性,多模态图像融合应运而生。多模态图像融合的目的是最大限度地提取各模态的图像信息,同时减少冗余信息。图像融合一般分为三个等级:像素级、特征级和决策级。像素级的处理对象是像素,最简单直接;特征级建立在抽取输入图像特征的基础上;决策级是对图像信息更高要求的抽象处理。常用的图像融合算法有加权平均法、ihs变换法、金字塔图像融合法等。
对于分类任务来说,显然,相比于单模态图像,多模态图像具有更多的信息,理应获得更好的分类效果。而目前利用双模态图像来进行分类的分类任务(例如医学图像分类),存在双模态图像信息融合困难、分类精度低等问题;以及双模态图像往往不能使用端到端的模型的问题。
技术实现要素:
本发明的目的在于:提供一种基于注意力机制和双模态图像的分类方法,解决了现有技术中双模态图像信息融合困难、分类精度低的技术问题。
本发明采用的技术方案如下:
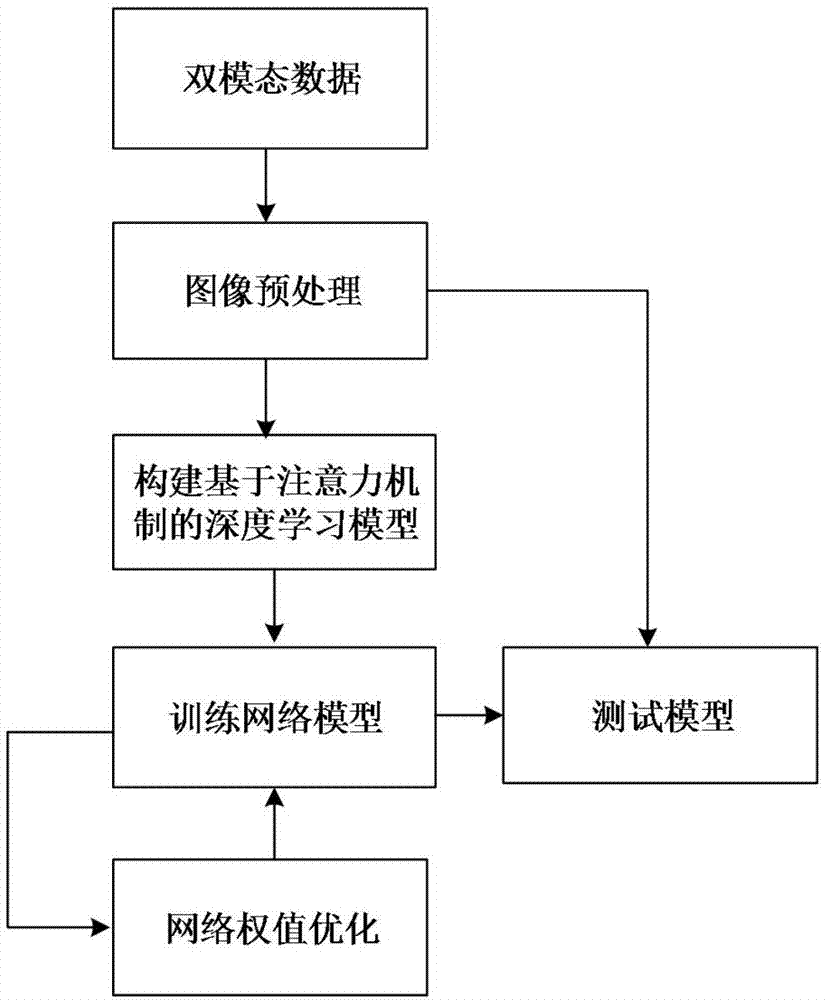
一种基于注意力机制和双模态图像的分类方法,包括以下步骤:
步骤1:对待分类项目的双模态图像数据进行预处理,将预处理后的双模态图像数据分为训练数据和测试数据;
步骤2:构建基于注意力机制的深度学习模型,将训练数据输入所述深度学习模型进行训练;
步骤3:利用反向传播及随机梯度下降算法对深度学习模型的网络参数进行优化,得到测试模型;
步骤4:将所述测试数据输入测试模型,通过前向传播得到该测试数据的分类结果。
进一步的,所述步骤1中,双模态图像数据包括a模态图像数据和b模态图像数据,所述预处理使a模态图像数据和b模态图像数据的尺寸相同。
进一步的,所述步骤2中,基于注意力机制的深度学习模型包括主干网络和attention支干网络,所述attention支干网络用于输入b模态图像数据,输出主干网络特定层特征图的权重;
所述主干网络用于输入a模态图像数据并结合所述权重,输出最终的分类结果。
进一步的,所述主干网络包括若干个卷积层、若干个池化层、若干个relu单元、若干个全连接层、一个attentionmodule和一个softmax分类层;
所述attention支干网络包括若干个卷积层、若干个池化层、若干个relu单元和一个归一化处理单元;
所述attention支干网络归一化处理单元的输出输入至所述主干网络的attentionmodule。
进一步的,所述权重用于更新主干网络中传输至attentionmodule的特征图,且所述权重与特征图尺寸相等,采用的公式为:
其中,
进一步的,所述归一化处理单元使输出位于0-1之间。
进一步的,所述归一化单元采用softmax函数;或
采用尺度变换函数;或
采用自定义函数f(x),所述自定义函数f(x)满足:定义域
综上所述,由于采用了上述技术方案,本发明的有益效果是:
本发明在深度学习模型中引入注意力机制,从b模态图像数据得到相应的a模态图像的权重,一方面以一种新的方式融合了a、b两种模态图像的信息;另一方面在提取每个样本的a模态图像不同空间位置的信息上都有各自不同的侧重,通过模型的学习提取出了样本各自比较重要的特征,最终可以得到更好的分类结果,分类准确率高;此外,虽然输入数据是双模态图像,但本发明提出的模型是端到端的模型。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1是本发明的基本流程图;
图2是本发明的一般模型图;
图3是本发明用于阿尔兹海默病分类的模型图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
下面结合图1-3对本发明作详细说明。
一种基于注意力机制和双模态图像的分类方法,包括以下步骤:
步骤1:对待分类项目的双模态图像数据进行预处理,将预处理后的双模态图像数据分为训练数据和测试数据;
步骤2:构建基于注意力机制的深度学习模型,将训练数据输入所述深度学习模型进行训练;
步骤3:利用反向传播及随机梯度下降算法对深度学习模型的网络参数进行优化,得到测试模型;
步骤4:将所述测试数据输入测试模型,通过前向传播得到该测试数据的分类结果。
进一步的,所述步骤1中,双模态图像数据包括a模态图像数据和b模态图像数据,所述预处理使a模态图像数据和b模态图像数据的尺寸相同。
进一步的,所述步骤2中,基于注意力机制的深度学习模型包括主干网络和attention支干网络,所述attention支干网络用于输入b模态图像数据,输出主干网络特定层特征图的权重;
所述主干网络用于输入a模态图像数据并结合所述权重,输出最终的分类结果。
进一步的,所述主干网络包括若干个卷积层、若干个池化层、若干个relu单元、若干个全连接层、一个attentionmodule和一个softmax分类层;
所述attention支干网络包括若干个卷积层、若干个池化层、若干个relu单元和一个归一化处理单元;
所述attention支干网络归一化处理单元的输出输入至所述主干网络的attentionmodule。
进一步的,所述权重用于更新主干网络中传输至attentionmodule的特征图,且所述权重与特征图尺寸相等,采用的公式为:
其中,
进一步的,所述归一化处理单元使输出位于0-1之间。
进一步的,所述归一化单元采用softmax函数;或
采用尺度变换函数;或
采用自定义函数f(x),所述自定义函数f(x)满足:定义域
具体实施例1
一种基于注意力机制和双模态图像的分类方法,包括以下步骤:
步骤1:对待分类项目的双模态图像数据进行预处理,将预处理后的双模态图像数据分为训练数据和测试数据;双模态图像数据包括a模态图像数据和b模态图像数据,所述预处理采用插值或者下采样方法使a模态图像数据和b模态图像数据的尺寸相同;
步骤2:构建基于注意力机制的深度学习模型,将训练数据输入所述深度学习模型进行训练;
基于注意力机制的深度学习模型包括主干网络和attention支干网络,所述attention支干网络包括若干个卷积层、若干个池化层、若干个relu单元和一个归一化处理单元,用于输入b模态图像数据,输出a模态图像数据的权重,所述权重大小位于0-1;
所述主干网络包括若干个卷积层、若干个池化层、若干个relu单元、若干个全连接层、一个attentionmodule和一个softmax分类层;用于输入a模态图像数据并结合所述权重,输出最终的分类结果;
所述归一化处理单元的输出输入至所述主干网络的attentionmodule,
所述权重用于更新主干网络中传输至attentionmodule的特征图,且所述权重与特征图尺寸相等,采用的公式为:
其中,
所述归一化单元采用softmax函数;或
采用尺度变换函数;或
采用自定义函数f(x),所述自定义函数f(x)满足:定义域
假设深度学习模型为3d卷积神经网络,主干网络对attentionmodule的输入是一个m×n×p×c的张量,attention支干网络对attentionmodule的输入是m×n×p×1的张量,通过点乘操作得到一个新的大小m×n×p×c的张量。
对模型进行训练的过程为:
(1)若a、b模态图像为三维数据则使用在行为识别数据集ucf101上预训练的主干网络卷积层参数作为模型主干网络卷积层参数初始值;若a、b模态图像为二维数据则使用在imagenet上预训练的主干网络卷积层参数作为模型主干网络卷积层参数初始值;支干网络及主干网络其他层的参数随机初始化。
(2)本方法以每个训练数据的交叉熵损失作为损失函数,使用随机梯度下降法为优化方法,初始学习率设置为0.0001,后面根据参数优化效果适当调整学习率,当loss下降到一定程度不再有明显下降时停止训练。
步骤3:利用反向传播及随机梯度下降算法对深度学习模型的网络参数进行优化,得到测试模型;
步骤4:将所述测试数据输入测试模型,通过前向传播得到该测试数据的分类结果。
具体实施例2
本实施例基于实施例1,以具体的双模态图像为例,进一步说明本发明的内容。
以阿尔兹海默病为例,a模态图像为mri图像,b模态图像为pet图像。attention支干网络由6个卷积层、4个池化层和一个normunit(归一化单元)构成。其中每个卷积层的kernelsize都是3×3×3、步长是1,conv6的filter个数为64、conv7的filter个数是128、conv8a的filter个数是256、conv8b的filter个数是128、conv9a的filter个数是64、conv9b的filter个数是1;每个池化层的filtersize都是2×2×2,步长也是2×2×2;normunite直接使用尺度变换函数,将normunite的输入变换到[0,1]区间上。
主干网络去除attentionmodule是一个类似c3d的模型。共有8个3d卷积层、5个3d池化层、2个全连接层以及一个softmax层,具体结构如图3所示。其中每个卷积层的kernelsize都是3×3×3、步长是1,conv1的filter个数为64、conv2的filter个数是128、conv3a和conv3b的filter个数是256、conv4a和conv4b的filter个数是512、conv5a和conv5b的filter个数也是512;每个池化层的filtersize都是2×2×2,步长也是2×2×2;
全连接层fc6的输出是大小为4096的列向量,fc7的输出是大小为2048的列向量;softmax层输出一个大小为3的列向量,表示当前受试者属于ad、mci和nc的概率,取概率最大的为最终的分类结果。
- 还没有人留言评论。精彩留言会获得点赞!