一种基于模糊粗糙DEMATEL-ANP的高端精密轴承制造过程误差源诊断方法与流程
本发明涉及轴承制造加工领域,具体为一种基于模糊粗糙dematel-anp的高端精密轴承制造过程误差源诊断方法。
背景技术:
轴承是当代机械设备中一种重要零部件,它的主要功能是支撑机械旋转体,降低其运动过程中的摩擦系数,并保证其回转精度。现代科技的发展使得机械设备对高端精密轴承的需求日趋旺盛。从高端精密轴承的制造过程出发开展误差源的诊断工作,能够为制造过程的质量控制和提高提供支撑和依据。
高端精密轴承的制造过程是一个串、并行相结合的多级系统,前面的制造质量缺陷将传递到后面的工位中,后续工位检测出的质量缺陷是包括前面各工位质量缺陷的综合,而并不仅仅是本道工序的质量缺陷。总体上看,多个误差源在高端精密轴承的多工位制造过程中进行复杂性极高的传递、累计和耦合,从而给误差源诊断带来了极大的困难。现有方法均是在尺寸偏差的基础上仅考虑某单一误差源对制造精度的影响,没有充分利用诊断专家的经验和智慧对制造过程中的多个误差源进行分析。同时,高端精密轴承制造过程的多个误差源之间也存在复杂的影响关系,比如环境的温湿度会影响到工人的心理状态,进而导致工人产生求快心理、影响制造质量;工人的岗位技术熟练程度也会影响工人在操作过程中的疲劳程度等,这些现象使得如何处理误差源之间的影响关系成为高端精密轴承制造过程误差源诊断的关键。
ahp(层次分析法)是一种较为普遍的确定各级因素权重的方法,但该方法忽略了指标之间的依存关系和反馈效应;anp(网络分析法)改进了ahp的不足,但在处理未加权矩阵的归一化时,假设一级因素具有相同的权重;将dematel(决策实验分析法)与anp相结合,能克服ahp和anp的不足,从而在确定各级因素权重时能更准确的反映现实情况。而在诊断专家给出评判意见时,使用准确数值来表达这种带有主观性和不确定性的意见很明显是不科学的,这种情况下使用模糊数更为合理。因此,本发明提出了一种模糊粗糙dematel-anp法来解决高端精密轴承制造过程误差源诊断问题。
技术实现要素:
本发明提供了一种基于模糊粗糙dematel-anp的高端精密轴承制造过程误差源诊断方法。建立高端精密轴承制造过程误差源集合,将误差源分为多个维度,每个误差源维度包含不同的误差源因素;充分考虑高端精密轴承制造过程误差源诊断中每位诊断专家个体认知水平的差异性,引入重要度来处理各位诊断专家的意见;使用梯形模糊数来表达诊断专家对高端精密轴承制造过程误差源的影响程度进行评估时给出的意见;提出一种模糊粗糙dematel-anp,统筹考虑误差源之间的复杂影响关系,进而来求解误差源的权重。本发明简便易行,编程实现快捷。
本发明的技术方案是:
所述一种基于模糊粗糙dematel-anp的高端精密轴承制造过程误差源诊断方法,其特征在于:包括如下步骤:
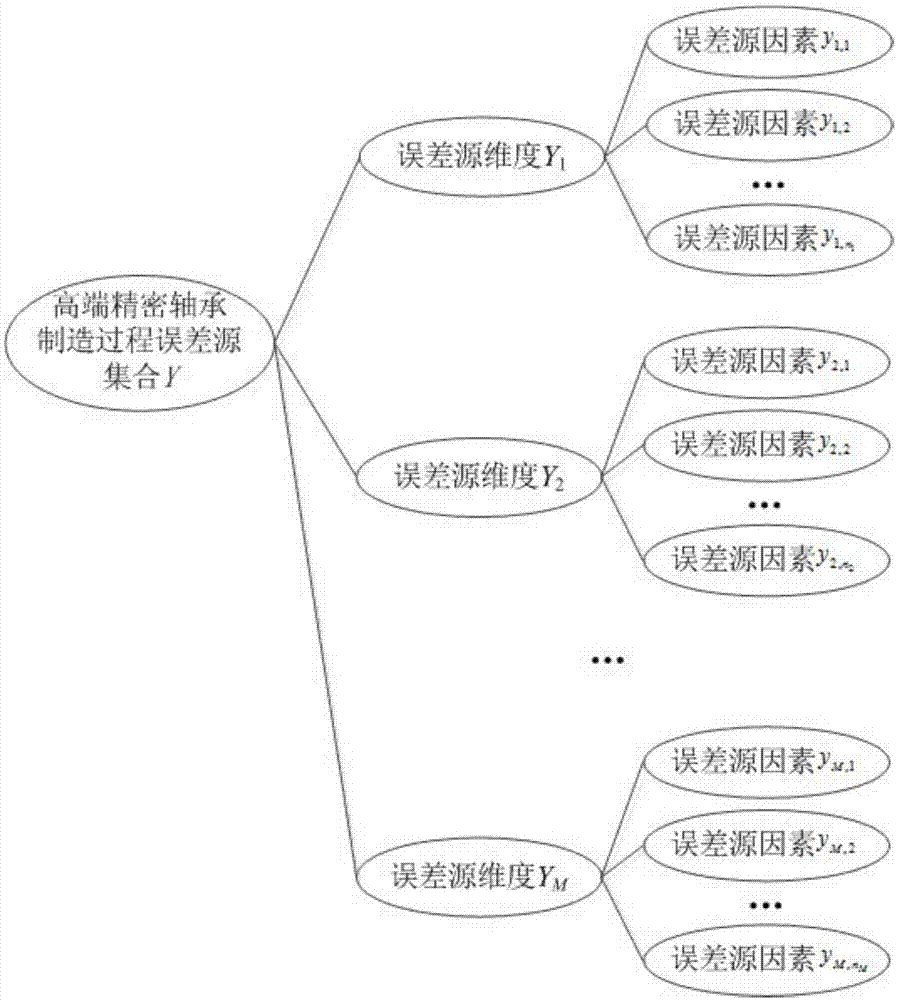
步骤1:建立高端精密轴承制造过程误差源集合y,y中包含n个误差源因素,这里n=11;
y进一步分为m个误差源维度:y1,y2,…,ym,这里m=4;
y1,y2,…,ym中分别包括n1,n2,...,nm个误差源因素;对于误差源维度yg,有
(1)y1表示人为维度,包括n1个误差源因素:y1,1=y1=工人生理特征状况,y1,2=y2=工人求快心理,y1,3=y3=工人疲劳程度,y1,4=y4=工人侥幸心理,即n1=4;
(2)y2表示设备维度,包括n2个误差源因素:y2,1=y5=设备故障,y2,2=y6=设备精度误差,y2,3=y7=设备老旧磨损,即n2=3;
(3)y3表示管理维度,包括n3个误差源因素:y3,1=y8=规程遵守状况,y3,2=y9=技术培训状况,即n3=2;
(4)y4表示环境维度,包括n4个误差源因素:y4,1=y10=温湿度,y4,2=y11=混入杂质,即n4=2;
步骤2:采用模糊粗糙dematel-anp,由具有不同重要度的多位诊断专家对高端精密轴承制造过程中的误差源进行诊断;
步骤2.1:计算n个误差源因素之间的总关系矩阵;
步骤2.1.1:设置l位诊断专家的重要度依次为
步骤2.1.2:l位诊断专家对不同误差源因素之间的直接影响程度进行模糊评估,依次给出误差源因素直接影响程度模糊矩阵为e1,e2,...,el,其中诊断专家k给出的误差源因素直接影响程度模糊矩阵为:
步骤2.1.3:l位诊断专家给出的误差源因素yi对误差源因素yj直接影响程度的模糊评估值依次为
步骤2.1.4:计算集合ai,j中所有元素的粗糙边界区间,其中元素
步骤2.1.5:计算集合ai,j的粗糙边界区间为
步骤2.1.6:设置五级评语:很差g1、差g2、中等g3、好g4、很好g5,依次对应效能值:π1=0.1,π2=0.3,π3=0.5,π4=0.7,π5=0.9;
步骤2.1.7:计算rn(ai,j)属于评语gu的隶属度θu,这里u=1,2,3,4,5;计算方法为:
若
若
若
(1)λ=1,δ=3,则
(2)λ=2,δ=4,则θ1=0,
(3)λ=1,δ=4,则
步骤2.1.8:计算集合ai,j的效能值π(ai,j),(1)若
步骤2.1.9:采用与步骤2.1.4-步骤2.1.8同样的方法,计算集合bi,j的效能值π(bi,j)、集合ci,j的效能值π(ci,j)、集合di,j的效能值π(di,j),从而得到误差源因素yi对误差源因素yj直接影响程度的综合模糊评估值为ei,j=(π(ai,j),π(bi,j),π(ci,j),π(di,j));
步骤2.1.10:采用与步骤2.1.3-步骤2.1.9同样的方法,计算出n个误差源因素之间的模糊初始平均矩阵:
步骤2.1.11:对模糊初始平均矩阵e=(ei,j)n×n进行去模糊化处理,转换为标准初始平均矩阵
步骤2.1.12:将标准初始平均矩阵e′=(ei′,j)n×n规范化为直接影响矩阵d=(di,j)n×n,其中
步骤2.1.13:计算n个误差源因素之间的总关系矩阵t=(ti,j)n×n=d(i-d)-1,其中i为单位矩阵;
步骤2.2:采用与步骤2.1同样的方法,计算出m个误差源维度之间的总关系矩阵k=(kg,h)m×m,这里g=1,2,...,m,h=1,2,...,m;
步骤2.3:基于n个误差源因素之间的总关系矩阵t=(ti,j)n×n计算未加权超级矩阵w;
步骤2.3.1:将t=(ti,j)n×n规范化处理为
步骤2.3.1.1:将t表示为:
其中
步骤2.3.1.2:计算
其中
步骤2.3.2:将
步骤2.4:将m个误差源维度之间的总关系矩阵k=(kg,h)m×m规范化处理为
步骤2.5:计算加权超级矩阵
步骤2.6:将
步骤2.7:
步骤2.8:分别将m个误差源维度、n个误差源因素按权重从大到小排序,排在首位的误差源维度和误差源因素即为高端精密轴承制造过程误差源诊断结果。
本发明的有益效果是:
(1)综合考虑高端精密轴承制造过程的误差源特征,建立4个维度、11个因素的误差源集合;
(2)充分考虑高端精密轴承制造过程误差源诊断中每位诊断专家个体认知水平的差异性,引入重要度来处理各位诊断专家的意见,更加合理;
(3)使用梯形模糊数来表达诊断专家对高端精密轴承制造过程误差源的影响程度进行评估时给出的意见,相比准确数值更加科学;
(3)提出一种模糊粗糙网络分析法,统筹考虑误差源之间的复杂影响关系,进而来求解误差源的权重;
(4)简便易行,编程实现较为快捷。
附图说明
图1是本发明的高端精密轴承制造过程误差源集合的示意图;
具体实施方式
下面结合具体实施例描述本发明,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
实施例:
某高端精密轴承制造企业需要对制造过程中对误差源进行诊断。
实施步骤如下:
步骤1:建立高端精密轴承制造过程误差源集合y,y中包含n个误差源因素,这里n=11;
y进一步分为m个误差源维度:y1,y2,…,ym,这里m=4;
y1,y2,…,ym中分别包括n1,n2,...,nm个误差源因素;对于误差源维度yg,有
(1)y1表示人为维度,包括n1个误差源因素:y1,1=y1=工人生理特征状况,y1,2=y2=工人求快心理,y1,3=y3=工人疲劳程度,y1,4=y4=工人侥幸心理,即n1=4;
(2)y2表示设备维度,包括n2个误差源因素:y2,1=y5=设备故障,y2,2=y6=设备精度误差,y2,3=y7=设备老旧磨损,即n2=3;
(3)y3表示管理维度,包括n3个误差源因素:y3,1=y8=规程遵守状况,y3,2=y9=技术培训状况,即n3=2;
(4)y4表示环境维度,包括n4个误差源因素:y4,1=y10=温湿度,y4,2=y11=混入杂质,即n4=2;
步骤2:采用模糊粗糙网络分析法,由具有不同重要度的多位诊断专家对高端精密轴承制造过程中的误差源进行诊断;
步骤2.1:计算n个误差源因素之间的总关系矩阵;
步骤2.1.1:3位诊断专家参与诊断,设置其重要度依次为
步骤2.1.2:3位诊断专家对不同误差源因素之间的直接影响程度进行模糊评估,依次给出误差源因素直接影响程度模糊矩阵为e1,e2,e3,其中:
步骤2.1.3:以误差源因素y1对误差源因素y2的直接影响程度为例,3位诊断专家给出的误差源因素y1对误差源因素y2直接影响程度的模糊评估值依次为:
步骤2.1.4:计算集合a1,2中所有元素的粗糙边界区间,其中元素
步骤2.1.5:计算集合a1,2的粗糙边界区间为
步骤2.1.6:设置五级评语:很差g1、差g2、中等g3、好g4、很好g5,依次对应效能值:π1=0.1,π2=0.3,π3=0.5,π4=0.7,π5=0.9;
步骤2.1.7:计算rn(a1,2)属于评语gu的隶属度θu,这里u=1,2,3,4,5;
步骤2.1.8:计算集合a1,2的效能值π(a1,2),这里
步骤2.1.9:采用与步骤2.1.4-步骤2.1.8同样的方法,计算集合b1,2的效能值π(b1,2)=0.4950、集合c1,2的效能值π(c1,2)=0.5820、集合d1,2的效能值π(d1,2)=0.7180,从而得到误差源因素y1对误差源因素y2直接影响程度的综合模糊评估值为e1,2=(0.3340,0.4952,0.5824,0.7187);
步骤2.1.10:采用与步骤2.1.3-步骤2.1.9同样的方法,计算出11个误差源因素之间的模糊初始平均矩阵e=(ei,j)11×11:
步骤2.1.11:对模糊初始平均矩阵e=(ei,j)11×11进行去模糊化处理,转换为标准初始平均矩阵:
步骤2.1.12:将标准初始平均矩阵e′=(e′i,j)11×11规范化为直接影响矩阵:
步骤2.1.13:计算11个误差源因素之间的总关系矩阵为:
步骤2.2:采用与步骤2.1同样的方法,计算出4个误差源维度之间的总关系矩阵:
步骤2.3:基于11个误差源因素之间的总关系矩阵t=(ti,j)11×11计算未加权超级矩阵w;
步骤2.3.1:将t=(ti,j)11×11规范化处理为
步骤2.3.1.1:将t表示为:
步骤2.3.1.2:计算
步骤2.3.2:将
步骤2.4:将4个误差源维度之间的总关系矩阵k=(kg,h)4×4规范化处理为:
步骤2.5:计算加权超级矩阵:
步骤2.6:将
步骤2.7:
步骤2.8:将4个误差源维度按权重从大到小排序:y2,y1,y4,y3;将11个误差源因素按权重从大到小排序:y4,2,y2,2,y4,1,y2,3,y2,1,y1,2,y1,3,y3,1,y1,1,y1,4,y3,2;
因此,从维度上看,此次误差源诊断结果为设备维度;从因素上看,此次误差源诊断结果为混入杂质。
- 还没有人留言评论。精彩留言会获得点赞!