一种基于红外相机的活体检测方法与流程
本发明属于视频监控技术领域,涉及一种基于红外相机的活体检测方法。
背景技术:
人脸活体检测的作用是检测图片或视频中是否存在活体人脸,防御来自照片、视频、面具或头套等对人脸识别相关应用的攻击。人脸识别已广泛应用于安防、金融等领域,而人脸活体检测则是人脸识别的应用前提。非活体种类繁多,人脸识别应用场景复杂多变,这对人脸活体检测的灵活性适应性提出了要求,在复杂场景下保证活体检测的精度是人脸活体检测的难点之一;此外人脸识别的高实时性和良好用户体验要求,决定了活体检测的耗时必须尽可能短,对人脸角度有良好的鲁棒性,尽量少的用户配合。
目前已有的技术中,《基于双目摄像机活体识别的方法及装置-cn201710160685》,用双目做活体检测,当常见光图像和红外图像都检测到人脸才进行活体检测,活体检测的耗时无法保障,当光线不佳只要有一个摄像头人脸检测性能下降,活体检测的精度必然下降。《一种基于红外摄像装置下眨眼的活体检测方法-cn201711204490》,在做活体检测时需用户眨眼进行配合,用户体验不好。《基于瞳孔灰度的活体检测方法-cn201810282799》,借助瞳孔灰度进行活体检测,当人离摄像头稍远或有眼镜遮挡,摄像头无法获取清晰的瞳孔图像,此方法的可行性大大降低,无法防御头套的攻击,此方法应用局限性比较大。
技术实现要素:
本发明针对现有技术的不足,提供了一种基于红外相机的活体检测方法。
本发明解决技术问题所采取的技术方案为:
步骤1、输入红外人脸图像和对应的人脸检测结果。
步骤2、对检测的人脸图像做对齐处理。
步骤3、取离鼻尖较近的人眼邻域图像缩放到指定大小。
步骤4、将人眼睛图片输入人眼活体检测模型model1得到活体置信度c1,判断c1是否大于活体阈值t1或小于非活体阈值t2,若是则输出活体或非活体并结束,反之则进入步骤5。
步骤5、将对齐好的人脸图片缩放到固定大小,输入人脸活体检测模型model2得到活体置信度c2,判断c2是否大于活体阈值t3或小于非活体阈值t4,若是则输出活体或非活体并结束,反之则进入步骤6。
步骤6、用活体置信度c1、c2计算活体置信度c3,若活体置信度c3大于活体阈值t5则输出活体并结束,否则输出非活体并结束。
本发明的有益效果:
(1)对人脸图像做对齐,提高活体检测器对人脸角度的鲁棒性同时提升活体检测的精度。
(2)用深度学习的方法对人眼做活体判断,能极大提升近距离活体检测的精度,同时能减小人脸角度对活体检测的影响,还能确保活体检测速度足够快。
(3)结合深度学习对人脸做活体判断,能增大检测器的有效工作距离,无需做眨眼、摇头等动作的配合,对是否戴眼镜具有很强的鲁棒性用户体验好。
(4)引入多个活体和非活体阈值,确保算法灵活多变,能有偏向的适应特定应用环境,确保算法在各种场景下都能有很高的检测精度。
附图说明
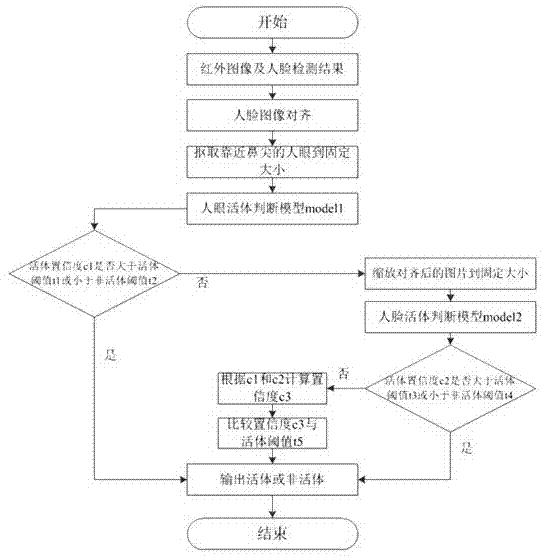
图1为人脸活体检测流程图;
图2为训练红外人眼活体检测模型的caffe网络结构;
图3为训练红外人脸活体检测模型的caffe网络结构。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他的实施例,都属于本发明保护的范围。
本发明的主要技术构思:
本发明检测出红外图像上的人脸,通过特征点定位算法得到5个特征点(左右眼、鼻子、左右嘴角),利用特征点对人脸图像做对齐操作,取离鼻尖较近的一只眼睛邻域图像输入活体检测模型model1,得到活体置信度c1,若c1大于设定的活体阈值t1或小于设定的非活体阈值t2则分别输出活体或非活体并结束,否则将对齐后的人脸图像缩放后输入活体检测模型model2,得到活体置信度c2,若c2大于设定的活体阈值t3或小于设定的非活体阈值t4则分别输出活体或非活体并结束,反之,根据c1和c2的值计算出置信度c3并和活体阈值t5比较,大于t5输出活体或小于t5输出非活体并结束。
人脸活体检测流程图见图1,具体步骤如下:
步骤1、输入红外人脸图像和对应的人脸检测结果。
步骤2、对检测的人脸图像做对齐:
2.1、用特征点定位算法得到人脸5个特征点;
2.2、根据特征点和训练的模板将检测到的人脸图片对齐到固定尺度。对齐能减少人脸角度对活体检测准确率的影响。
3、取离鼻尖较近的人眼邻域图像缩放到指定大小。离鼻尖近的人眼能有效增强检测器对人脸角度的鲁棒性。
4、将缩放后的人眼邻域图像输入活体检测模型model1得到活体置信度c1,判断c1是否大于活体阈值t1或小于非活体阈值t2,若是则输出活体或非活体并结束,反之则进入步骤5。
5、将对齐好的人脸图片缩放到特定固定大小输入训练好的人脸活体检测模型model2得到活体置信度c2,判断c2是否大于活体阈值t3或小于非活体阈值t4,若是则输出活体或非活体并结束,反之则进入步骤6。
6、用c1和c2计算活体置信度c3,若c3大于活体阈值t5则输出活体并结束,否则输出非活体并结束。设人脸检测器最大人脸宽高分别为fdwmax,fdhmax,检测到人脸的宽高分别为fdw和fdh,则c3的计算方法为:
当检测的人脸较大时c3偏向于c1,反之则偏向c2,保证在不同工作距离下都能达到较好的检测精度,能高效适应更多的应用场景。
所述的步骤4中的人眼活体检测模型model1由以下方式得到:
1.1、准备活体人眼样本。用红外摄像头采集若干含有人脸的红外视频,当人脸检测器在视频中检测到人脸,用人脸特征点定位算法回归出人脸5点,根据回归出的5点和200*200标准尺度图像上的5点模板,将人脸对齐到标准尺度图像并截取人眼邻域32*32大小的图片作为人眼活体训练样本。
1.2、准备非活体人眼样本。尽可能多的收集各种场景下的人脸图片,将这些图片进行打印。用采集视频的红外摄像头对打印的图片进行拍摄,同时拍摄戴面具头套等辅助用具的人脸图片,同样对这些图片经过人脸检测、对齐扣取照片中的人眼32*32大小的区域作为人眼非活体训练样本。
1.3、用caffe训练红外人眼活体检测模型。网络结构如图2所示。网络输入图片大小为32*32,包含3个卷积层,3个pooling层和2个全连接层,每个卷积层后面都连接了batchnorm,scale和relu,各层的参数见图2。活体人眼样本和非活体人眼样本按照1:1的比率进行训练,得到活体检测模型model1。
所述的步骤5中的人脸活体检测模型model2由以下方式得到
2.1、准备红外人脸活体和非活体训练样本。将1.1中人眼活体样本阶段对齐得到的200*200尺度的图片缩放到64*64,作为红外人脸活体训练样本。将1.2中对齐好的非活体图片缩放到64*64作为红外人脸非活体训练样本。
2.2用caffe训练红外人脸活体检测模型。网络结构如图3所示,网络输入图片大小为64*64,包含4个卷积层,4个pooling层,2个全连接层和1个dropout,同样每个卷积层后面都连接了batchnorm,scale和relu,各层参数设置见图3。人脸活体和非活体样本也是按照1:1的数据比率进行训练,得到活体检测模型model2。
实施例
2.1、输入包含人脸的红外图像及其人脸检测结果。
2.2、根据标准模板检测到的人脸对齐到200*200大小。
2.3、用红外人眼进行活体检测;
2.3.1、扣取对齐后人脸图片靠近鼻尖的人眼缩放到32*32。
2.3.2、将扣取的人眼输入活体检测模型model1,得到活体置信度c1,若c1大于活体阈值t1=0.85或小于非活体阈值t2=0.2则输出活体或非活体并结束,否则执行2.4。
2.4、用红外人脸进行活体检测;
2.4.1、将对齐后的人脸图片缩放到64*64;
2.4.2、将缩放的图片输入活体检测模型model2,得到活体置信度c2,若c2大于活体阈值t3=0.8或小于非活体阈值t4=0.25则输出活体或非活体并结束,否则执行2.5。
2.5、根据c1和c2计算活体置信度c3,若c3大于活体阈值t5=0.5则输出活体并结束,反之则输出非活体并结束。
综上,本发明对人脸图像做对齐,使用深度学习的方法提取红外人眼和人脸的特征做人脸活体检测,结合活体和非活体多阈值的策略进行判断,在确保活体检测耗时毫秒级的前提下,提高了活体检测的准确率,增强了活体检测对人脸角度的鲁棒性,改善了活体检测的用户体验,增加了活体检测的应用场景。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,应当理解,本发明并不限于这里所描述的实现方案,这些实现方案描述的目的在于帮助本领域中的技术人员实践本发明。
- 还没有人留言评论。精彩留言会获得点赞!