一种基于离线和在线聚类的车型数据库清洗方法与流程
本发明涉及一种基于离线和在线聚类的车型数据库清洗方法。
背景技术:
随着机动车保有量急剧增加,违法犯罪车辆逐年上升趋势,例如:肇事逃逸,车辆假牌,车辆套牌,机动车超速等犯罪现象每每都在上演。而技术的发展,智能车型识别方法正成为一种成熟有效的手段,可广泛应用在卡口车辆检测、套牌车检测、车辆检索等方面。
在很多应用中,都需要建立一个在线的车型库。基于深度学习的车型识别技术能够达到98%以上的准确率,但在长期运行中,不断入库的错误样本仍会导致其累积到一个难以维持系统性能及稳定性的程度。在此基础上,需要提出一种基于离线和在线聚类的车型数据库清洗方法,对车型库进行定期清洗以保持系统性能及稳定性。
现有的各种数据库清洗方法多为通用数据清洗或针对某一特定领域的数据清洗,缺少针对车型数据库的清洗方法。如《一种数据清洗方法201710704678.1》、《一种简化的大数据清洗方式201711182073.7》等。
技术实现要素:
本发明针对现有技术的不足,提供了一种基于离线和在线聚类的车型数据库清洗方法。该方法针对在线更新的车型库存在一定量错误入库数据的情况,采用离线和在线聚类,对车型库进行定期清洗以保持系统性能及稳定性。
本发明解决技术问题所采取的技术方案为:
一.标注各类车型样本得到离线车型库,利用深度学习进行训练,取训练反向第二个的全连接层输出作为车型特征。
二.分别提取各个类内所有车型特征进行离线聚类,得到n个类中心及相应阈值。
三.定期提取在线车型库各个类内所有车型特征进行聚类,初始聚类中心为离线聚类得到的n个类中心,添加一个随机初始化中心的类后进行有约束的聚类,得到n+1类。
四.根据离线聚类得到的阈值,依次判定并清洗属于前n类的车型数据,清洗最后一类车型数据。
本发明的有益效果:本发明可以对智能车型识别应用中所建立的在线车型数据库进行定期快速清洗,可以在保持在线车型库内各类整体性质不变的情况下,有效删除错误入库的样本,从而维持系统长期运行的性能及稳定性。
附图说明
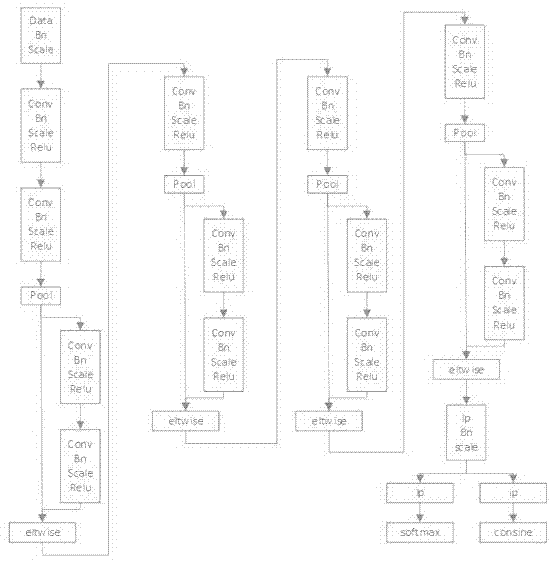
图1为离线深度学习训练网络结构。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他的实施例,都属于本发明保护的范围。
本发明的离线部分包括车型特征训练和车型特征离线聚类,在线部分包括车型特征提取、车型特征在线聚类。
一.标注各类车型样本得到离线车型库,利用深度学习进行训练,取训练反向第二个的全连接层输出作为车型特征。
二.分别提取各个类内所有车型特征进行聚类,得到n个类中心及相应阈值。
三.定期提取在线车型库各个类内所有车型特征进行聚类,初始聚类中心为离线聚类得到的n个类中心,添加一个随机初始化中心的类后进行有约束的聚类,得到n+1类。
四.根据离线聚类得到的阈值,依次判定并清洗属于前n类的车型数据,清洗最后一类车型数据。
实施例:
一.标注各类车型样本得到离线车型库,利用深度学习进行训练(见图1),取训练反向第二个的全连接层输出的512维特征作为车型特征。
二.分别提取各个类内所有车型特征进行离线聚类,特征距离采用余弦相似度。循环调用k-means聚类得到1至5类结果,根据类内类间差异选择第n类结果,统计类内所有特征与类中心距离的标准差,得到阈值。
三.定期提取在线车型库各个类内所有车型特征进行在线聚类。类似地,同样采用k-means聚类,初始聚类中心为离线聚类得到的n个类中心,添加一个随机初始化中心的类,约束前n类中心偏移度小于30度进行聚类,得到n+1类。
四.根据离线聚类得到的阈值,依次判定(得到的距离与阈值比较)并清洗属于前n类的车型数据,清洗最后一类车型数据。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,应当理解,本发明并不限于这里所描述的实现方案,这些实现方案描述的目的在于帮助本领域中的技术人员实践本发明。
技术特征:
技术总结
本发明公开了一种基于离线和在线聚类的车型数据库清洗方法。本发明首先标注各类车型样本得到离线车型库,利用深度学习进行训练,取训练反向第二个的全连接层输出作为车型特征。其次分别提取各个类内所有车型特征进行离线聚类,得到n个类中心及相应阈值。然后定期提取在线车型库各个类内所有车型特征进行聚类,初始聚类中心为离线聚类得到的n个类中心,添加一个随机初始化中心的类后进行有约束的聚类,得到n+1类。最后根据离线聚类得到的阈值,依次判定并清洗属于前n类的车型数据,清洗最后一类车型数据。本发明可以在保持在线车型库内各类整体性质不变的情况下,有效删除错误入库的样本,从而维持系统长期运行的性能及稳定性。
技术研发人员:尚凌辉;张兆生;王弘玥;余天明
受保护的技术使用者:浙江捷尚视觉科技股份有限公司
技术研发日:2018.08.17
技术公布日:2019.01.11
- 还没有人留言评论。精彩留言会获得点赞!