基于计量大数据聚类模型的采集终端生产厂商评价方法与流程
本发明涉及电力系统领域,特别是涉及基于计量大数据聚类模型的采集终端生产厂商评价方法。
背景技术:
自2011年国网开始大范围建设用电信息采集系统以来,用电信息采集系统越来越多得承担了营销侧的计量业务工作,采集终端定时定期地采集电能表数据项,按要求将采集信息上送系统,是用电信息采集系统的核心组成部分,其质量直接影响着用户用电信息的获取,针对其故障导致的运维也浪费了大量的人力物力。
用电信息采集系统覆盖范围的逐步扩大,采集的对象和采集频率逐年提高,各类计量数据和采集数据应用逐渐完善。以浙江的用电信息采集系统为例,用电信息采集每周数据增长量近1tb,历年累积收集的数据十分丰厚,并且在2015年建立的采集运维模块收集了大量的采集终端故障历史信息。但针对这些数据却缺少足够的数据挖掘手段,使数据金矿的价值难以体现。目前浙电采集大数据分析平台已经具备初步的数据分析能力,能够通过大数据技术分析计量装置运行数据,开展可靠性质量评估方法研究,进而提升公司计量精益化管理水平。
供电单位一般对采集终端的厂家运行质量评估停留在一些考核指标的基础上,以及针对地市单位反映的批量性故障收集上,相对比较粗犷。
技术实现要素:
本发明要解决的技术问题和提出的技术任务是对现有技术方案进行完善与改进,提供基于计量大数据聚类模型的采集终端生产厂商评价方法,以达到对采集终端质量作出科学、合理的定量评价的目的。为此,本发明采取以下技术方案。
基于计量大数据聚类模型的采集终端生产厂商评价方法,其特征在于,包括如下步骤:
1)获取每个批次和区域中采集终端的原始数据,筛选获取衡量采集终端的评估指标:评估指标包括负荷采集合格率,电量数据采集率,无故障工作时间,反映采集异常的严重异常次数、一般异常次数、轻微异常次数,维修率和在线率;
2)采用高斯混合模型聚类算法提取采集终端海量数据中的评估指标数据,获取聚类中心,形成采集终端综合评估的决策矩阵,并对其分别按效益型和成本型进行标准化处理;
3)分别计算采集终端各项典型评估指标基于层次分析法、熵权法、皮尔逊相关系数法以及变异系数法的权重,然后用指标权重的组合优化模型获得组合权重,对决策矩阵进行加权处理从而获得采集终端综合评估的评估矩阵;
4)根据评估矩阵,用夹角度量法对采集终端的质量进行综合评估,按照从高至低的顺序将各个采集终端供应商的质量进行优劣排序,获得评价结果。
作为优选技术手段:在步骤1中,采用8个衡量采集终端的评估指标,分别为:负荷采集合格率α1,电量数据采集率α2,无故障工作时间α3,反映采集异常的严重异常次数α4、一般异常次数α5、轻微异常次数α6,维修率α7和在线率α8:
式中:nsamp是采样时间段的总个数,tsamp,i是第i次采样的时间长度,
作为优选技术手段:在步骤2)高斯混合模型聚类算法中:
假设gmm由k个高斯分布混合而成,则每个高斯分布称作一个“组分”,这些“组分”线性相加即为gmm的概率密度函数:
式中:ωk表示第k个多维单高斯分布的权值,nk(x;μk;σk)表示第k个多维单高斯分布的概率密度函数,x表示数据样本列向量,μk表示第k个高斯模型的期望向量,σk表示第k个高斯模型的方差;
采集终端数据的gmm聚类算法流程为:
205)令l=0,随机选择初始化的ω(l),μ(l),σ(l),求取第i个样本点xi属于第k类高斯模型的初始化后验概率:
206)将第201)步得到的结果代入最大似然公式计算第l+1次迭代的gmm聚类参数:
式中:n为待聚类的数据点个数;
207)若
208)采用贝叶斯概率公式计算第i个样本点xi属于第k类高斯模型的概率:
根据贝叶斯概率最大准则,将第i个样本点xi划分到使其概率p(μk,σk|xi)取得最大的那类高斯模型中。
作为优选技术手段:在步骤2),决策矩阵为:
式中:dij表示第i个采集终端供应商第j个指标的值,p为采集终端供应商个数,q为衡量供应商的采集终端的评价指标个数,其中q等于8;
效益型指标标准化处理方法为:
成本型指标标准化处理方法为:
式中:
作为优选技术手段:在步骤3)中,分别采用层次分析法、熵权法、相关系数法和变异系数法计算采集终端指标权重,接着用指标的组合优化模型计算组合权重,其中:
层次分析法为:设q个指标为u={u1,u2,…,uq},每次取两个指标ui和uj,按1~9的比例用aij表示指标ui与uj对采集终端的影响程度之比,数值越大表示ui相对于uj越重要;这样即可获得一个采集终端评估问题的判断矩阵a=(aij)q×q,该判断矩阵具有如下性质:aij>0,aji=1/aij,(i=1,2,…,q;j=1,2,…,q);计算指标权重前首先对判断矩阵a进行一致性检验,如果一致性检验未通过,则说明aij取值前后矛盾,需要重新赋值;如果通过,则说明aij取值前后一致,判断矩阵a可用于求取指标权重;求取指标权重可以用列和求逆法,即:
将bj归一化,即可求得归一化后的指标权重为
式中:
采集终端指标的熵权为:
式中:κ表示常数κ=1/lnp,
计算皮尔逊相关系数权重包括:假设d′x=(d′1x,d′2x,...,d′px)t和dy′=(d′1y,d′2y,...,d′py)t表示标准化决策矩阵d′的两个列向量,则第x个指标和第y个指标之间的皮尔逊相关系数定义为
式中:
式中:
计算变异系数法权重包括:指标uj的变异系数定义为:
式中:
式中:
指标权重的组合优化模型为:
式中:
作为优选技术手段:在步骤4)用夹角度量法对采集终端的质量进行综合评估时,包括步骤:
405)形成p个待评估的供应商对应的q个质量指标的评估矩阵
r=(rij)p×q
式中:
406)计算采集终端评估中的理想点和负理想点,其分别为
式中:
407)分别计算每个供应商下的采集终端指标与理想点、负理想点的夹角距离,即
式中:ri=(ri1,ri2,...,riq)表示评估矩阵r的第i个行向量;
408)计算每个供应商下的采集终端指标与理想点的夹角逼近程度,即
可以看出:第i个供应商生产的采集终端越好,γi愈接近于1;反之,质量越差,γi越接近于0;因此,可以根据γi取值的大小得到采集终端的评估结果。
有益效果:本技术方案及时利用其用采多年存储的大数据,建立可靠的质量评估指标体系,对采集终端质量作出科学、合理的定量评价,以提供物资招标的信息支持。
附图说明
图1为本发明流程图;
具体实施方式
为了更好地理解本发明的目的、技术方案以及技术效果,以下结合附图对本发明进行进一步的讲解说明。
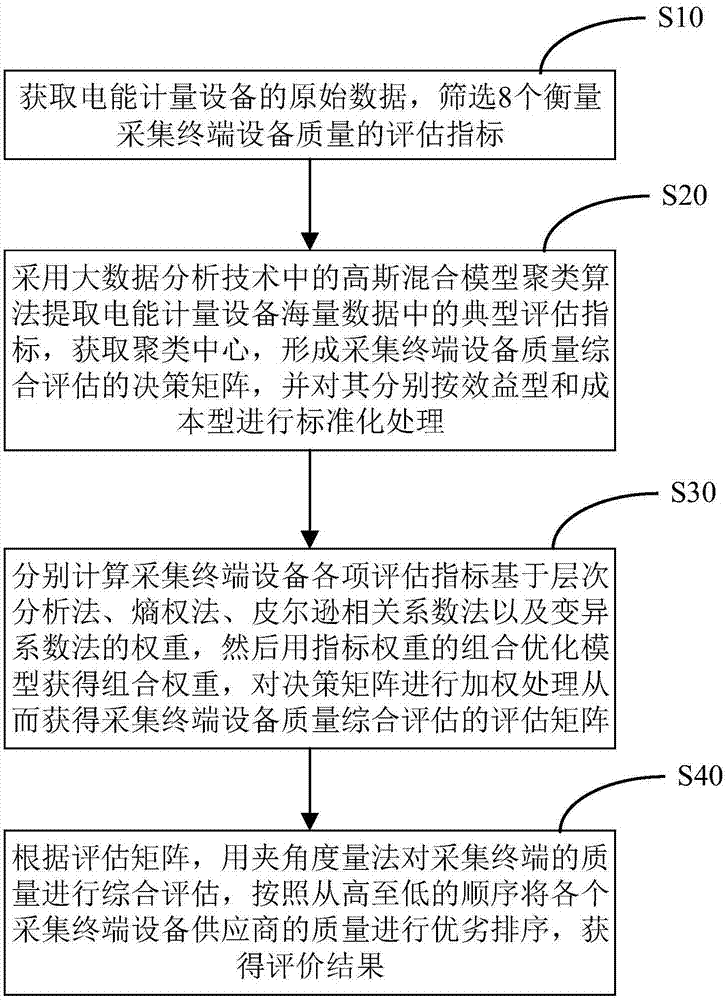
参考图1,图1所示为本实施例的基于计量大数据聚类模型的采集终端生产厂商评价方法流程图,包括如下步骤:
s10,获取采集终端的原始数据,筛选8个衡量采集终端的评估指标:负荷采集合格率,电量数据采集率,无故障工作时间,反映采集异常的严重异常次数、一般异常次数、轻微异常次数,维修率和在线率;
在本实施例中:
采集终端分为供应商、型号、批次和单个设备四个层次,而计量自动化系统中一般以单个设备为单元存储数据。目前,在计量自动化系统中已采集的采集终端数据包含有负荷采集合格率α1,电量数据采集率α2,无故障工作时间α3,反映采集异常的严重异常次数α4、一般异常次数α5、轻微异常次数α6,维修率α7和在线率α8,其含义分别可以为:
式中:nsamp是采样时间段的总个数,tsamp,i是第i次采样的时间长度,
s20,采用大数据分析技术中的高斯混合模型聚类算法提取采集终端海量数据中的典型指标数据,获取聚类中心,形成采集终端综合评估的决策矩阵,并对其分别按效益型和成本型进行标准化处理;
在本实施例中:
每个供应商生产的采集终端数量众多、型号复杂,因此从系统中导出的采集终端数据无法直接应用于对每个供应商的质量评估。为此,可以用大数据分析技术中的数据聚类方法,挖掘各个供应商采集终端的典型特征,从而实现对其质量的综合评估。
高斯混合模型(gaussianmixturemodel,gmm)用高斯分布概率密度函数来描述数据,它可以将一个大数据集分解为若干个符合高斯分布的模型。因此,高斯混合模型可用于数据聚类,提取数据集中的典型特征。假设gmm由k个高斯分布混合而成,则每个高斯分布称作一个“组分”,这些“组分”线性相加即为gmm的概率密度函数:
式中:ωk表示第k个多维单高斯分布的权值,nk(x;μk;σk)表示第k个多维单高斯分布的概率密度函数,x表示数据样本列向量,μk表示第k个高斯模型的期望向量,σk表示第k个高斯模型的方差。
采集终端的质量受到多个独立因素的影响,且这些因素都不是决定性的。根据中心极限定理,可认为同一批次的采集终端的指标数据符合高斯分布。对于某一采集终端供应商下的k个批次的设备,可认为其质量的指标数据是k个高斯分布模型的叠加。因此,高斯混合模型聚类算法适用于挖掘采集终端的指标数据。在进行gmm聚类之前,首先需要估计各个高斯分布模型的参数,这里采用期望最大化算法进行估计。因此,采集终端数据的gmm聚类算法流程可以为:
201)令l=0,随机选择初始化的ω(l),μ(l),σ(l),求取第i个样本点xi属于第k类高斯模型的初始化后验概率:
202)将第201)步得到的结果代入最大似然公式计算第l+1次迭代的gmm聚类参数:
式中:n为待聚类的数据点个数。
203)若
204)采用贝叶斯概率公式计算第i个样本点xi属于第k类高斯模型的概率:
根据贝叶斯概率最大准则,将第i个样本点xi划分到使其概率p(μk,σk|xi)取得最大的那类高斯模型中。
当所有的样本点均按照上述步骤划分到各自所属的高斯模型后,gmm聚类完成并获得了相应的聚类中心。gmm聚类算法舍弃了采集终端评估原始指标数据中冗余和不重要的信息,但保留了原始指标数据的重要数据和典型特征。因此,gmm聚类算法大大压缩了数据的规模、减少了综合评估的计算量,却几乎不影响采集终端综合评估的准确性。
设d为采集终端评估问题的决策矩阵,d中的元素dij表示第i个采集终端供应商第j个指标的值。因为不同指标间的量纲不同,所以不能直接对各个指标的重要程度进行比较,需要进行归一化处理。此外,采集终端指标还分为效益型和成本型两类,效益型指标数值越大代表质量越好,成本型指标数值越大代表质量越差。因此,在确定指标权重前首先要对d进行归一化处理以得到归一化后的决策矩阵d′,其归一化处理公式可以为:
式中:
s30,分别计算采集终端各项指标基于层次分析法、熵权法、皮尔逊相关系数法以及变异系数法的权重,然后用指标权重的组合优化模型获得组合权重,对决策矩阵进行加权处理从而获得采集终端综合评估的评估矩阵;
在本实施例中:
ahp法通过指标间两两比较重要程度,间接获得每个指标的权重,该方法属于一种主观赋权法。设q个指标为u={u1,u2,…,uq}。每次取两个指标ui和uj,按1~9的比例用aij表示指标ui与uj对采集终端的影响程度之比,数值越大表示ui相对于uj越重要。这样即可获得一个采集终端评估问题的判断矩阵a=(aij)q×q,该判断矩阵具有如下性质:aij>0,aji=1/aij,(i=1,2,…,q;j=1,2,…,q)。计算指标权重前首先对判断矩阵a进行一致性检验,如果一致性检验未通过,则说明aij取值前后矛盾,需要重新赋值;如果通过,则说明aij取值前后一致,判断矩阵a可用于求取指标权重。即可以为:
将bj归一化,即可求得归一化后的指标权重为
式中:
在信息学中,熵用来表征系统的无序程度和数据的离差程度。指标的信息熵越大则其在综合评估中提供的信息就越少,相应的权重也应该越小;反之,其信息熵越小,则权重应当越大。因此,采集终端指标uj的熵hj可以定义为
式中:κ表示常数κ=1/lnp,
式中:
在统计学中相关系数用于衡量两个变量之间的关联性,包括皮尔逊相关系数、斯皮尔曼相关系数和肯德尔相关系数等,其中皮尔逊相关系数更适用于符合正态分布的数据,因此本发明使用皮尔逊相关系数来计算指标间内在的相关程度。相关程度越大说明指标间信息的重复性越大,相应指标的权重应越小;反之,相关程度越小,权重应越大。假设dx′=(d′1x,d′2x,...,d′px)t和dy′=(d′1y,d′2y,...,d′py)t表示标准化决策矩阵d′的两个列向量,则第x个指标和第y个指标之间的皮尔逊相关系数可以定义为:
式中:
式中:
变异系数法是一种根据指标数据间的对比强度来确定指标权重的客观赋权法。某个指标的变异程度越大,说明其相对于其它指标的对比强度越大,则在综合评估中对评估对象的重要性越高,从而其权重也应越大;反之,变异程度越小,权重应越小。指标uj的变异系数可以定义为:
式中:
式中:
虽然上述4种主、客观方法简单易行,但均存在一定的不足。主观赋权法仅依照专家的经验,很容易导致主观偏好过强;客观赋权法仅凭借实际数据,但实际数据可能会出现一定误差,从而可能导致评估结果不符合实际。为了充分考虑依据专家经验的主观打分,同时依据数据本身的特征对权重进行修正,本发明基于权重隶属度最大,构建了采集终端指标权重的组合优化模型,即可以为
式中:
s40,根据评估矩阵,用夹角度量法对采集终端的质量进行综合评估,按照从高至低的顺序将各个采集终端供应商的质量进行优劣排序,获得评价结果。
在本实施例中:
确定各个采集终端指标的组合权重后,采集终端的综合质量评估可以转化为一个多属性决策问题。夹角度量法采用变量之间的夹角作为距离的测度,依据被评估对象与理想化目标的逼近程度进行排序。因此,基于夹角度量法的采集终端综合质量评估的流程可以为:
401)形成p个待评估的供应商对应的q个质量指标的评估矩阵
r=(rij)p×q
式中:
402)计算采集终端评估中的理想点和负理想点,其分别为
式中:
403)分别计算每个供应商下的采集终端指标与理想点、负理想点的夹角距离,即
式中:ri=(ri1,ri2,...,riq)表示评估矩阵r的第i个行向量。
404)计算每个供应商下的采集终端指标与理想点的夹角逼近程度,即
可以看出:第i个供应商生产的采集终端越好,γi愈接近于1;反之,质量越差,γi越接近于0。因此,可以根据γi取值的大小得到采集终端的评估结果。
为了进一步理解本发明,以下采用国网浙江省电力公司宁波供电公司管辖的某地区的采集终端数据进行算例仿真,该原始数据集共有11565条数据,经过数据清洗之后可用数据为11312条,共有17个待评估的采集终端供应商,每个供应商下有若干设备批次,所有的设备批次总数为58个。
将17个供应商及其58个批次的数据按顺序重新进行编号,以第1、3、12个供应商为例分析gmm聚类算法的效果。第1个供应商下有2个批次,共142台采集终端;第3个供应商下有4个批次,共496台采集终端,第12个供应商下有6个批次,共1514台采集终端。每台采集终端都有8个指标。
对每个供应商下的采集终端都进行gmm聚类分析,可以获得表征各个供应商的采集终端的典型采集终端,然后将这些典型采集终端相应的指标取平均值即可得到如表1所示的决策矩阵d′。
表1标准化后的采集终端决策矩阵
表2分别给出了基于ahp、基于熵权法、相关系数法、变异系数法和组合优化模型的指标权重。从表2可以看出:客观权重对主观权重起到了一定的修正作用,按照专家经验,采集终端的严重异常指标α4应占有较大的权重,但另外三种客观赋权法都对α4给出了较小的权重,这是因为原始数据中各个供应商的α4数值差异不大。因此,和其它指标相比,该指标难以辨别各个供应商的采集终端优劣,故应当赋予较小的权重。
表2不同方法计算得到的指标权重
然后,基于得到的指标组合权重,形成采集终端的评估矩阵r,进而采用夹角度量法对采集终端的质量进行综合评估,最后得到如表3所示的采集终端综合评估的结果。
表3采集终端综合评估结果
从表3可以看出:采集终端最好的前9家采集终端供应商分别为:10、9、6、5、7、13、4、11和16,其中第10个供应商在采集终端综合评估中的评估值最高,第8个供应商的评估值最低。
- 还没有人留言评论。精彩留言会获得点赞!