一种自动获取故障的方法及系统与流程
本发明属于互联网监控领域,具体涉及一种自动获取故障的方法及系统。
背景技术:
在互联网时代,我们有大量的后台程序在持续地运行,及时发现这些程序的故障并自动化处理,是互联网业务持续稳定提供服务的前提,这就是“故障发现”的重要之处。然而,现在的服务越来越多,越来越复杂,要做到自动化处理故障,首先现故障,这就为广大互联网企业提出了挑战。
为了监控到服务故障,最低端的“故障发现”,是依赖于相关技术人员对业务和程序的了解,把他们的相关知识写成程序,通过监控一些特殊的指标来达到“故障发现”的目的,例如针对mysql数据库服务,有mysql的监控程序,针对oracle数据库服务,则有另一套监控程序。这种做法有一个明显的优点,那就是针对性强。因为这个程序就是为了这个事情而写的。相应地,以上做法也有明显的缺点:监控的质量,取决于写程序的人的专业程度,越高级的工程师,写出来的程序效果越好;这也就说,如果对相应的程序或服务了解不深刻,写出的监控程序可能需要不断进化才能达到期望的效果,这期间可能会有“漏报”;不可复制性,增加一个新的程序或业务,都需要有专门的人来写一个对应的监控程序来做“故障发现”,不具有通用性;相应的,维护成本也只会持续增加。
此为现有技术的不足,因此,针对现有技术中的上述缺陷,提供一种自动获取故障的方法及系统,是非常有必要的。
技术实现要素:
本发明的目的在于,针对上述故障依赖于相关技术人员对业务和程序的了解,不具有通用性,监控质量不统一,且不可复制的缺陷,提供一种自动获取故障的方法及系统,以解决上述技术问题。
为实现上述目的,本发明给出以下技术方案:
一种自动获取故障的方法,包括如下步骤:
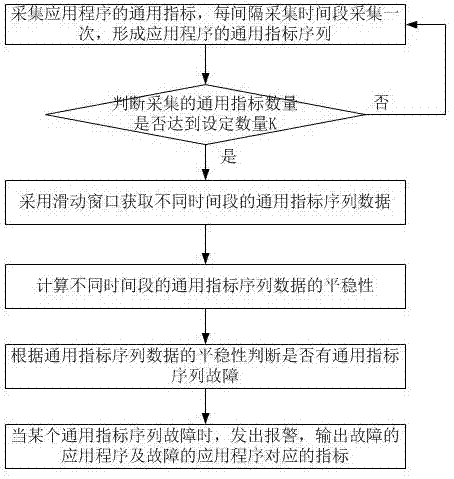
采集应用程序的通用指标,每间隔采集时间段采集一次,形成应用程序的通用指标序列;
判断采集的通用指标数量是否达到设定数量k;
若采集的通用指标数量达到设定数量k,则采用滑动窗口获取不同时间段的通用指标序列数据;
计算不同时间段的通用指标序列数据的平稳性;
根据通用指标序列数据的平稳性判断是否有通用指标序列故障。
进一步地,判断采集的通用指标数量是否达到设定数量k;
当采集的通用指标数量小于等于设定数量k时,返回采集应用程序的通用指标步骤。如果通用指标数量少于k个,说明程序启动没有多久,还在预热,相关数据不足以支持研判,暂不处理。
进一步地,根据不同时间段的通用指标序列数据的平稳性,判断是否有通用指标序列故障之后还包括如下步骤:
当某个通用指标序列故障时,发出报警,输出故障的应用应用程序及故障的应用应用程序对应的指标。通过报警发现哪个应用程序的哪个指标出了异常,就完成了故障发现的自动化。
进一步地,采用滑动窗口获取不同时间段的通用指标序列数据,具体步骤如下:
采用滑动窗口获取通用指标序列中时间段最新的m个数据,m<k,形成序列y_new;
滑动窗口沿着时间段滑动,获取y_new之前时间段的m个数据,形成序列y_old。滑动窗口保证了两次采集的数据长度相同。
进一步地,计算不同时间段的通用指标序列数据的平稳性;根据通用指标序列数据的平稳性判断是否有通用指标序列故障的具体步骤如下:
计算序列y_new和y_old的均值,分别设置为mean(y_new)和mean(y_old);
计算序列y_new和y_old的方差,分别设置为dev(y_old)和dev(y_new);
设定偏移量p;
判断序列y_new和y_old的均值,以及y_new和y_old的方差是否满足
(1-p)*mean(y_old)<mean(y_new)<(1+p)*mean(y_old),
和(1-p)*dev(y_old)<dev(y_new)<(1+p)*dev(y_old);
若是,则判定指标序列平稳,否则,判定指标序列故障。计算出均值数据的两次偏差和方差数据的两次偏差,判断平稳性。
进一步地,偏移量p取值5%。
进一步地,采集时间段采用5s。
进一步地,设定数量k采用50个。
进一步地,所述通用指标包括但不限于进程存活与否,进程的cpu使用率、进程的内存使用量、进程的磁盘io以及进程的网络io。
本发明还给出如下技术方案:
一种自动获取故障的系统,包括
采集模块,用于采集应用程序的通用指标,每间隔采集时间段采集一次,形成应用程序的通用指标序列;
指标数量判断模块,判断采集的通用指标数量是否达到设定数量k;
不同时间段的通用指标序列数据获取模块,用于当采集的通用指标数量达到设定数量k,采用滑动窗口获取不同时间段的通用指标序列数据;
通用指标序列数据的平稳性计算模块,用于计算不同时间段的通用指标序列数据的平稳性;
通用指标序列故障判断模块,用于根据通用指标序列数据的平稳性判断是否有通用指标序列故障;
报警模块,用于当某个通用指标序列故障时,发出报警,输出故障的应用应用程序及故障的应用应用程序对应的指标。
本发明的有益效果在于:
本发明实现大量“专用”监控程序的替换,用统一的方式发现故障,减少了现有程序的维护成本;不依赖于专用知识,实现发现更多隐藏的故障的发现。
此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著的进步,其实施的有益效果也是显而易见的。
附图说明
图1为本发明的方法流程图一;
图2为本发明的方法流程图二;
图3为本发明的系统示意图;
其中,1-采集模块;2-指标数量判断模块;3-不同时间段的通用指标序列数据获取模块;4-通用指标序列数据的平稳性计算模块;5-通用指标序列故障判断模块;6-报警模块。
具体实施方式:
为使得本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本发明具体实施例中的附图,对本发明中的技术方案进行清楚、完整地描述。
实施例1:
如图1所示,本发明提供一种自动获取故障的方法,包括如下步骤:
采集应用程序的通用指标,每间隔采集时间段采集一次,形成应用程序的通用指标序列;采集时间段采用5s;通用指标包括但不限于进程存活与否,进程的cpu使用率、进程的内存使用量、进程的磁盘io以及进程的网络io;
判断采集的通用指标数量是否达到设定数量k;设定数量k采用50个;
若采集的通用指标数量达到设定数量k,则采用滑动窗口获取不同时间段的通用指标序列数据;
计算不同时间段的通用指标序列数据的平稳性;
根据通用指标序列数据的平稳性判断是否有通用指标序列故障;
当某个通用指标序列故障时,发出报警,输出故障的应用程序及故障的应用程序对应的指标。
实施例2:
如图2所示,一种自动获取故障的方法,包括如下步骤:
采集应用程序的通用指标,每间隔采集时间段采集一次,形成应用程序的通用指标序列;采集时间段采用5s;通用指标包括但不限于进程存活与否,进程的cpu使用率、进程的内存使用量、进程的磁盘io以及进程的网络io;
判断采集的通用指标数量是否达到设定数量k;设定数量k采用50个;
若采集的通用指标数量达到设定数量k,则采用滑动窗口获取通用指标序列中时间段最新的m个数据,m<k,形成序列y_new;
滑动窗口沿着时间段滑动,获取y_new之前时间段的m个数据,形成序列y_old;
计算序列y_new和y_old的均值,分别设置为mean(y_new)和mean(y_old);
计算序列y_new和y_old的方差,分别设置为dev(y_old)和dev(y_new);
设定偏移量p;
判断序列y_new和y_old的均值,以及y_new和y_old的方差是否满足
(1-p)*mean(y_old)<mean(y_new)<(1+p)*mean(y_old),
和(1-p)*dev(y_old)<dev(y_new)<(1+p)*dev(y_old);
若是,则判定指标序列平稳;
否则,判定指标序列故障,发出报警,输出故障的应用程序及故障的应用程序对应的指标。
应用上述示例2的一种自动获取故障的方法,首先采集针对应用程序的一些通用的无差别的指标,每隔一定的时间(比如5秒)拿到一个相应的数据,包含但不限于:进程存活与否、进程的cpu使用率、进程的内存使用量、进程的磁盘io、进程的网络io,可以得到n个指标对应的指标序列x1,x2,…xn;
对于每个指标序列xi,如果指标数量少于k个(比如50个),说明应用程序启动没有多久,还在预热,相关数据不足以支持研判,暂不处理;
如果指标数据多于k个,则使用滑动窗口法,先取出最新的m个数据(m<k)组成的序列y_new,再取出稍早些的m个数据组成的序列y_old;
对于y_new和y_old,分别计算它们的均值mean(y_old)和mean(y_new),最计算它们的方差dev(y_old)和dev(y_new)
对于我们认定的一个正常偏移量p(一般取p=5%),如果(1-p)*mean(y_old)<mean(y_new)<(1+p)*mean(y_old)而且
(1-p)*dev(y_old)<dev(y_new)<(1+p)*dev(y_old)
那么判定xi当前处理一种“平稳”状态。否则,就判定xi指标序列“故障”;
对于任何一个指标序列xi,如果被判定为“故障”,则直接报警,说明哪个服务的哪个指标出了异常。至此,就完成了获取故障的自动化。
采用实施例2的一种自动获取故障的方法,针对mysql的监控采集了cpu使用率,内存使用率,网络io,硬盘io这4个指标来实施监控,某天收到了网络io使用率的故障报警,报警发生,虽然当时的故障并不是出在网络io上,但是网络io的数据异常准确地反馈出了应用程序的故障,达到了自动发现故障的目的。
实施例3:
如图3所示,一种自动获取故障的系统,包括
采集模块1,用于采集应用程序的通用指标,每间隔采集时间段采集一次,形成应用程序的通用指标序列;
指标数量判断模块2,判断采集的通用指标数量是否达到设定数量k;
不同时间段的通用指标序列数据获取模块3,用于当采集的通用指标数量达到设定数量k,采用滑动窗口获取不同时间段的通用指标序列数据;
通用指标序列数据的平稳性计算模块4,用于计算不同时间段的通用指标序列数据的平稳性;
通用指标序列故障判断模块5,用于根据通用指标序列数据的平稳性判断是否有通用指标序列故障;
报警模块6,用于当某个通用指标序列故障时,发出报警,输出故障的应用应用程序及故障的应用应用程序对应的指标。
本发明的实施例是说明性的,而非限定性的,上述实施例只是帮助理解本发明,因此本发明不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他的具体实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!