一种基于机器学习动态检测垃圾邮件的方法与流程
本发明涉及垃圾邮件识别技术,尤其涉及一种基于机器学习动态检测垃圾邮件的方法。
背景技术:
随着大数据时代的发展,用户数据泄漏的事件越来越多,通信邮箱大规模泄漏事件层出不穷。不法利益团体往往会利用获取到的邮箱,批量发送商业广告等类型的垃圾邮件,严重影响了电子邮箱的工作效率,占用了邮箱的存储空间,直接影响到邮箱的用户体验。
现有的垃圾邮件的检测方法,主要通过使用传统统计模型,人工提取垃圾邮件的文本特征做分类。但是,发送垃圾邮件技术也随之而不断升级。基于人工提取文本特征这类检测垃圾邮件的方法,已经无法高效拦截新型垃圾邮件。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于机器学习动态检测垃圾邮件的方法,即aas(autoencoderanti-spamsystem),通过采用lda主题模型,autoencoder自编码器,以及自定义的线性模型,能够更好的识别垃圾邮件,从而保证邮箱正常高效的运转,保证用户不被垃圾邮件骚扰。
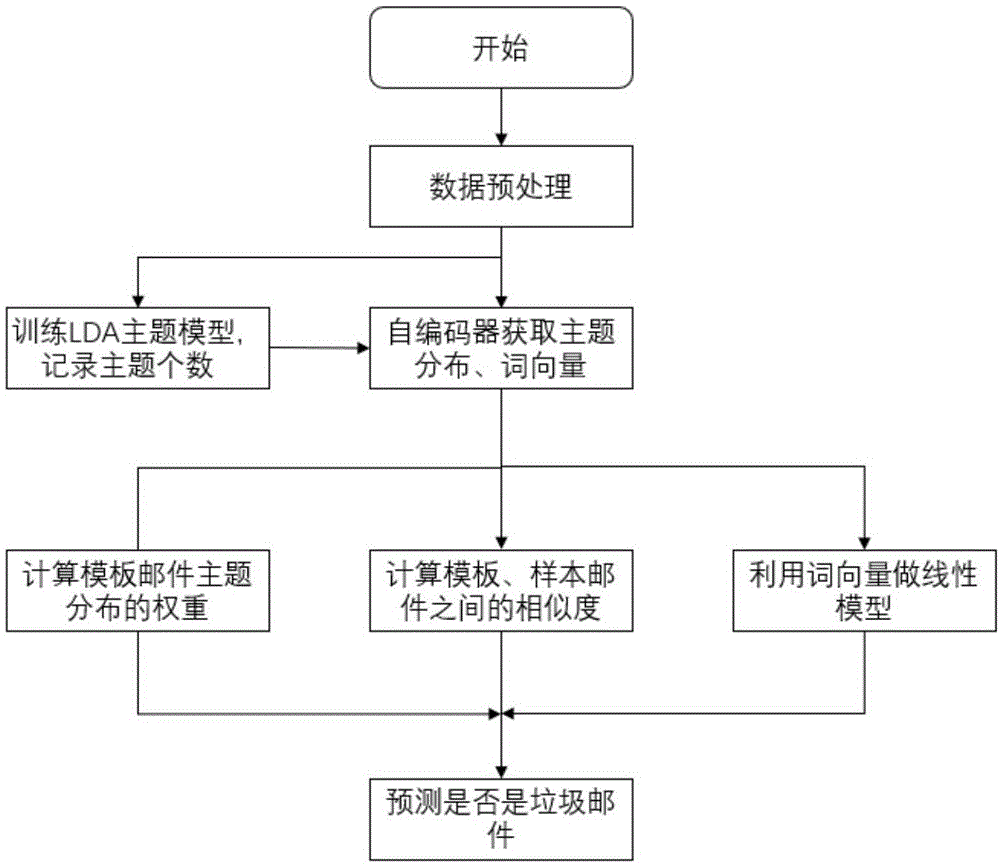
本发明的核心是:通过采用隐含狄利克雷分布(latentdirichletallocation,一下简称lda)lda主题模型,autoencoder自编码器,以及自定义的线性模型,动态检测垃圾邮件,更好的识别垃圾邮件。其中,lda)模型是一种无监督的机器学习方法。涉及:gamma函数、beta分布、dirichlet分布、共轭先验、以及gibbs采样。具体通过对海量文档的学习,推测出具体文档的主题分布。autoencoder自编码器是一种无监督的神经网络模型,可以将信息进行有效压缩。本发明使用autoencoder自编码器进行词向量生成。aas中的线性部分包括了投票、预测两个阶段。在投票阶段,通过softmax函数对主题分布进行权重的选择;预测阶段,是通过样本邮件与模板邮件(包括有多个代表性的垃圾邮件和正常邮件)进行匹配,通过sigmoid函数预测结果是否是垃圾邮件。
本发明提供的技术方案如下:
一种基于机器学习动态识别垃圾邮件的方法,通过采用lda主题模型、autoencoder自编码器和创建自定义的线性模型,动态检测垃圾邮件,达到高效识别垃圾邮件的目的;包括如下步骤:
a.对模板和样本邮件进行预处理过程,执行如下操作:
a1.将中文模板及样本邮件用jieba软件进行分词,英文模板及样本邮件使用spacy软件进行分词;
a2.去除中文与英文的停用词,使用python的re模块剔除文本中的标点;
a3.使用sklearn软件将分好词的句子转化为one_hot编码向量。
b.使用开源gibbslda++,对文本进行训练
b1.设置狄利克雷分布的参数,设置主题个数;
b2.设置迭代次数;
b3.保存训练的结果,观测设置多少主题时候,文本主题聚类效果比较好,将该文本的主题数作为autoencoder主题层的个数。
c.使用自编码器(autoencoder)模型对步骤a3中得到的one_hot编码向量进行压缩,转化为词向量(embedding);
c1.使用tensorflow深度学习框架,进行模型的建立,分别设置输入层、中间层、主题层、输出层的个数;具体训练过程表示为:
p(zl|v)=softmax(-f(v,zl))(式1)
其中,v是经过a3步骤生成的one_hot编码;p(zl|v)为v在主题集合z中第l个主题下所得概率值;z:主题的集合;l:第l个主题;zl:表示在主题集合z中的第l个主题;
dl:在主题l下,计算机随机初始化的一个标量d;vk:在大小为k的词表中,生成的one_hot编码向量;
p(hj|v,zl):降维后生成的词向量的第j个下标的概率值;hj:隐藏层h下
第j个坐标;σ:sigmoid函数(具体实施中给出具体的公式)。
c2.使用平方损失函数为模型的损失函数,使用adamoptimizer优化方法来优化模型;
c3.使用交叉验证的方法,选择一个最好的模型(即autoencoder方法训练出来的模型),通过这个模型,将one_hot编码向量作为输入,得到降维后的词向量;
d.创建线性模型,使用线性模型进行邮件的预测:
线性模型包括投票、预测两个阶段;在投票阶段,通过softmax函数对主题分布进行权重的选择;预测阶段,是通过样本邮件与模板邮件进行匹配,通过sigmoid函数预测结果;具体执行如下操作:
d1.使用自编码器返回的主题分布做softmax函数操作,作为投票模型;
自编码器返回的主题分布作为式3输入的一部分:
其中:
σ:sigmoid函数;
sl(q,r)=cos(zq,zr):其中zq,zr分别表示为样本邮件q以及模板邮件r在主题集合z上的概率分布,sl(q,r)表示样本邮件q与模板邮件r在主题集合z中的第l个主题下的余弦相似性。
d2.计算每一个样本邮件与已标记的模板邮件的余弦相似度,作为特征sl(q,r);
已标记的模板邮件:将模板邮件中垃圾邮件类别记为0,正常邮件类型记为1(用y值表示0或1,也就是步骤d4中的y值);
d3.使用(步骤c3)生成的样本词向量和模板词向量做点积乘法,所得的结果经过sigmoid函数,产生出一组维度值为模板邮件(词向量所表示模板邮件)个数的0-1之间的概率值。
d4.将(步骤d1)中投票模型所得概率值与(步骤d3)中sigmoid函数所得结果的概率值做加权平均,得到预测值y^(0-1之间的小数);模板邮件的真实值记为y(垃圾邮件记为0,正常邮件记为1);
d5.最后使用交叉熵公式作为模型的损失函数(关于y和y^的函数),adamoptimizer优化方法优化模型,通过200-500轮的训练,保存模型。
d6.利用(步骤d5)保存的模型,以及模板邮件。每当一个新的邮件进入已经训练好的aas系统时,可以得到数值0或1(0代表不是垃圾邮件,1代表是垃圾邮件)。
与现有技术相比,本发明的有益效果是:
本发明提供一种基于机器学习动态检测垃圾邮件的方法,通过采用lda主题模型,autoencoder自编码器,以及自定义的线性模型,动态检测垃圾邮件,高效识别垃圾邮件。
本发明的技术优势包括:
首先,本发明利用了深度学习方法,从而提高了筛选垃圾邮件的准确率;
其次,本发明中,线性模型计算复杂度不高,使得系统筛选邮件的速度加快;
最后,本发明技术方案是一个可扩展的方法/系统,如果出现新型的垃圾邮件表达形式,只需要将新型垃圾邮件添加到模板邮件集合中,重新按步骤训练一个新的模型即可。
附图说明
图1本发明方法的流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明的具体实施方式如下:
a.在对样本和模板邮件(包括多个垃圾和正常邮件)进行预处理时,执行如下操作:
a1.在github上寻找jieba分词软件,并安装;
a2.使用jieba.cut方法中的精简模式,分解文本中需要分词的字符串,并利用python中的re模块将文本中的标点去掉;
a3.将中文的停用词的词表导入数据预处理的代码中,并剔除字符串分词后存在的停用词,生成字符串s;
a4.安装sklearn工具包,使用sklearn.feature_extraction.text文件中countvectorizer类处理字符串s,生成字符串对应的独热编码(onehot),作为(步骤c)的输入数据。
b.使用gibbslda++对文本进行训练时,执行如下操作:
b1.下载并编译开源的gibbslda++源代码;
b2.训练语料准备,文件格式是bat,文件的内容:第一行是样本邮件总数,第二行到最后一行是所有分词和去停用词的样本邮件文本;
b3.设置超参数alpha(alpha决定文本-主题分布的超参数,默认为50/主题数),beta(beta决定主题-单词分布的超参数,默认为0.1);
b4.设置主题个数(默认:100),设置迭代运行次数(默认:1000);
b5.设置每个主题(topic)下希望保留的关键字个数(每个主题下关键字个数的默认值:20),设置生成文件的存储路径;步骤b4,b5的参数,是根据现存模板样本的数据分布和经验估计得来的,需要尝试多次,才能通过训练得到一个好的模型;
b6.利用上述参数,使用gibbslda++对文本进行训练;当训练迭代的轮数结束后,生成文件model_final.towords中记录了每一个主题下所聚合的关键词(关键词个数为:步骤b5的参数值,即每个主题下关键字个数)分布情况。最后,人工评测gibbslda++模型所得结果是否达标,达标的标准根据具体需求而定,在本专利中gibbslda++模型达标定义的标准为主题分布下关键词聚类结果符合样本分布的70%。如若符合,将步骤b4设置的主题数(标量),作为步骤c2中主题层的维度(标量),否则,重复步骤b,直至训练的结果满足模板邮件主题的数据分布。
c.使用自编码器将独热(one_hot)编码转换为压缩后的词向量。执行如下操作:
c1.安装tensorflow深度学习框架;
c2.设置输入层,隐藏层,主题层,输出层四层神经元的个数,其中:输入层=输出层=one_hot维度数(v:输入层向量的字符表示,k:|v|,输入层的维度,k:第k维输入向量的标量值),主题层=gibbslda主题个数(z:主题层字符表示,l:第l维的主题的标量值),隐藏层设为50-200之间(hj,h:隐藏层字符表示,j:|h|,隐藏层的维度,j:第j维中间向量的标量值),w:随机初始化k*z*l的三维张量,式2所得的结果为autoencoder生成的词向量,作为(步骤d)的输入部分;
具体的公式:
p(zl|v)=softmax(-f(v,zl))(式1)
其中,
p(zl|v):v(经过a3步骤生成的one_hot编码)在主题集合z中第个l主题下所得概率值;vk等价v(下同)
z:主题的集合;
l:第l个主题;
zl:表示在主题集合z中的第l个主题;
softmax函数:f(x)=ex/∑ex
dl:在主题l下,计算机随机初始化的一个标量d;
vk:在大小为k的词表中,生成的one_hot编码向量;
其中,
σ(x)=1/[1+exp(-x)],即sigmoid函数;
hj:隐藏层h下第j个坐标
c3.使用平方差损失函数为模型的损失函数(loss函数),使用adamoptimizer优化方法来优化模型;
c4.使用交叉验证的方法选择最优的模型,用该最优的模型生成邮件的词向量(embedding)。
d.创建线性模型,使用线性模型做预测,具体的实行方法如下。
d1.将样本邮件通过式1,得到样本邮件的主题分布。作为式3第一部分的输入,即:
∑l∈lp(zl|q);
其中,q为样本邮件;r为模板邮件;r为模板邮件集合;z为主题集合;l为集合
中的某一主题;l等价于z,也表示主题集合。
m矩阵:随机初始化h*h大小的矩阵
其中:
σ:sigmoid函数,见式2;
sl(q,r)=cos(zq,zr):其中zq,zr分别表示为样本邮件q以及模板邮件r在主题集合z上的概率分布,sl(q,r)表示样本邮件q与模板邮件r在主题集合z中的第l个主题下的余弦相似性。
d2.使用sklearn工具包计算模板邮件的主题分布与样本邮件的主题分布之间的余弦相似性,并进行归一化,具体公式见sl(q,r);
d3.通过(步骤c)得到样本模板词向量
d4.将d1-d3所得结果通过式3进行乘积运算;
d5.使用交叉熵损失函数作为模型的loss函数,使用adamoptimizer优化方法优化模型;
其中,交叉熵函数为:h(y|y^)=-∑ylogy^;adamoptimizer优化方法可使用tensorflow软件提供的类adamoptimizer实现,即tf.train.adamoptimizer。
d6.最后使用交叉熵公式作为模型的损失函数(关于y和y^的函数),adamoptimizer优化方法优化模型,通过200-500轮的训练,保存训练好的模型参数,和现存的模板邮件。
每当一个新的邮件进入aas系统时,通过式1-式3的计算,可以得到新输入邮件的分数,即数值0或1;0代表不是垃圾邮件,1代表是垃圾邮件。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!