一种人脸图像替换方法和装置与流程
本发明涉及图像处理领域,特别涉及一种人脸图像替换方法和装置。
背景技术:
由于人物肖像是真实照片的主要组成部分,也是人们最感兴趣的图像类型之一,肖像编辑具有重要的研究与应用价值。
但是,现有技术中,通常需要使用修图软件来完成人物肖像的编辑和修正,费事费力,效率较低。
技术实现要素:
本发明要解决的技术问题是提供一种可自动完成修改或编辑人物肖像(人脸)的方法。
为了解决上述技术问题,本发明的技术方案包括:
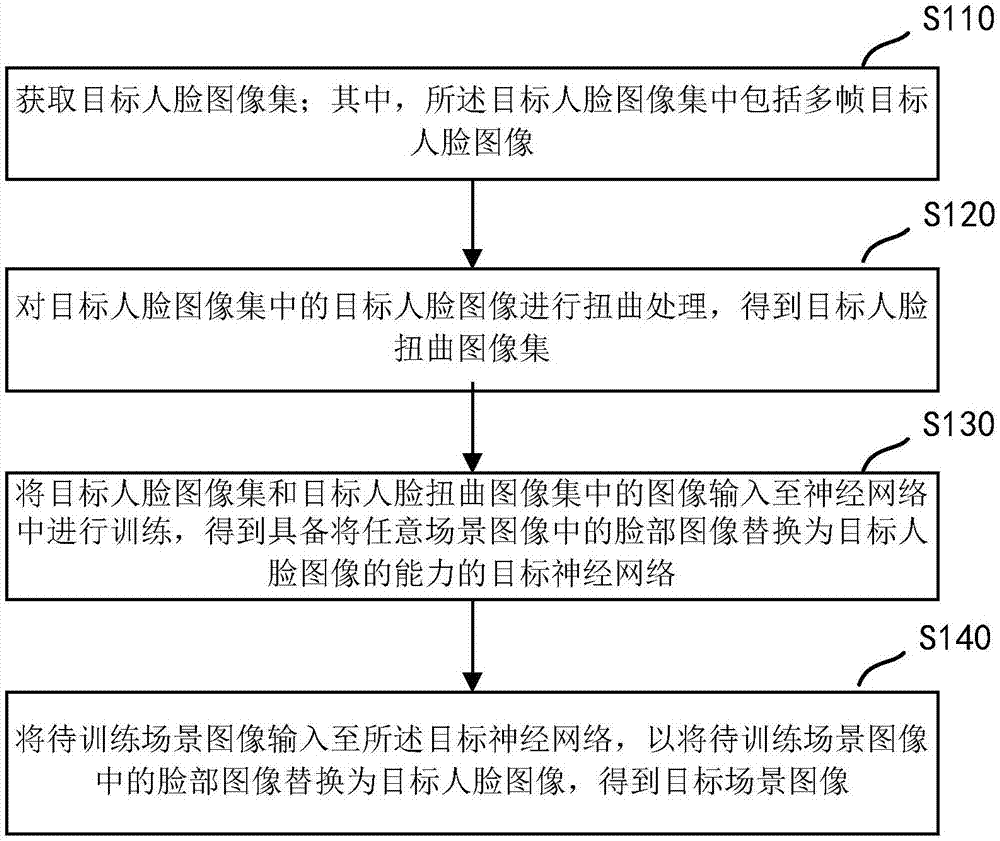
一种人脸图像替换方法,具体包括:获取目标人脸图像集;其中,所述目标人脸图像集中包括多帧目标人脸图像;
对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;其中,目标人脸扭曲图像集中包括多帧目标人脸扭曲图像;
将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;
将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。
在上述实施例的基础上,所述获取目标人脸图像集,包括:
从目标视频中提取多帧目标场景图;
针对任意所述多帧目标场景图,识别目标场景图中的人脸区域,切割目标场景图中的人脸区域部分,得到目标人脸图像集。
在上述实施例的基础上,所述目标神经网络至少包括4个卷积层和至少1个池化层。
基于相同的思路,本实施例还提供了一种人脸图像替换装置,具体包括:
获取模块,用于获取目标人脸图像集;其中,所述目标人脸图像集中包括多帧目标人脸图像;
处理模块,用于对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;其中,目标人脸扭曲图像集中包括多帧目标人脸扭曲图像;
训练模块,用于将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;
替换模块,用于将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。
在上述实施例的基础上,提取单元,用于从目标视频中提取多帧目标场景图;
切割单元,用于针对任意所述多帧目标场景图,识别目标场景图中的人脸区域,切割目标场景图中的人脸区域部分,得到目标人脸图像集。
在上述实施例的基础上,所述目标神经网络至少包括4个卷积层和至少1个池化层。
采用上述技术方案,通过获取目标人脸图像集;对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。通过深度学习的方法将待训练场景图像中的脸部图像替换为目标人脸图像,不仅不需要人为完成,而且处理效率提高,减少了人力物力的消耗。
附图说明
图1为本发明实施例一提供的一种人脸图像替换方法的流程图;
图2为本发明实施例三提供的一种人脸图像替换装置结构示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
实施例一
图1为本发明实施例一提供的一种人脸图像替换方法的流程图,该方法可以由一种人脸图像替换装置来执行,该装置可以通过软件和/或硬件的方式实现,并集成在是智能设备中。
本实施例通过的方法具体包括如下步骤:
s110、获取目标人脸图像集;其中,所述目标人脸图像集中包括多帧目标人脸图像。
其中,所述目标人脸图像集中包括多帧目标人脸图像,且多帧目标人脸图像中为同一人物的人脸图像。
具体的,目标人脸图像集中的多帧目标人脸图像可以是对目标人脸从不同角度拍摄得到,可以是在不同灯光、场景中拍摄到的,也可以是从原始图片中将人脸区域截取出来的部分。
s120、对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;其中,目标人脸扭曲图像集中包括多帧目标人脸扭曲图像。
其中,扭曲处理为平面图形变化的一种,其用于将目标人脸图像进行图像变换,已得到更多的训练样本。
本实施例中,扭曲处理过程可以通过空间坐标变换、变换坐标的赋值和插值运算等步骤完成。
s130、将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络。
其中,所述目标神经网络至少包括4个cov层和至少1个upscale层,其中conv是中规中矩的卷积加relu激活函数,upscale中有个函数叫pixelshuffler,pixelshuffler函数可以将过滤器的大小减小到原有的25%,让高和宽各变为原来的2倍。
s140、将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。
采用上述技术方案,通过获取目标人脸图像集;对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。通过深度学习的方法将待训练场景图像中的脸部图像替换为目标人脸图像,不仅不需要人为完成,而且处理效率提高,减少了人力物力的消耗。
实施例二
在实施例一的基础上,本实施例中所述的人脸图像集可以从同一视频中提取得到的,具体的,所述人脸图像替换方法包括:
s210、从目标视频中提取多帧目标场景图。
其中,目标场景图可以是目标视频中任意一帧图像,目标场景图中可以包括图片的背景、目标人物的整体形态。本实施例中,可以通过ffmpeg、googleimage等软件提供的图片提取接口完成对多帧目标场景图的提取。
s220、针对任意所述多帧目标场景图,识别目标场景图中的人脸区域,切割目标场景图中的人脸区域部分,得到目标人脸图像集。
其中,目标人脸图像即从目标场景图中的人脸区域切割下来的图像。本实施例中可以通过边缘检测算法来识别目标场景图中的人脸区域,以从人脸区域中切割所述目标人脸图像,最终形成人脸图像集。
对应的,所述目标人脸图像的数量与目标场景图的数量相同。
为了保证训练得到的目标神经网络的性能,所述目标场景图的图片清晰度可以尽可能的提高。
s230、对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;其中,目标人脸扭曲图像集中包括多帧目标人脸扭曲图像;
s240、将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;
s250、将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。
其中,所述目标神经网络至少包括4个卷积层和至少1个池化层。
实施例三
图2为本发明实施例三提供的一种人脸图像替换装置的结构示意图,具体包括:获取模块310、处理模块320、训练模块330和替换模块340。
获取模块310,用于获取目标人脸图像集;其中,所述目标人脸图像集中包括多帧目标人脸图像;
处理模块320,用于对目标人脸图像集中的目标人脸图像进行扭曲处理,得到目标人脸扭曲图像集;其中,目标人脸扭曲图像集中包括多帧目标人脸扭曲图像;
训练模块330,用于将目标人脸图像集和目标人脸扭曲图像集中的图像输入至神经网络中进行训练,得到具备将任意场景图像中的脸部图像替换为目标人脸图像的能力的目标神经网络;
替换模块340,用于将待训练场景图像输入至所述目标神经网络,以将待训练场景图像中的脸部图像替换为目标人脸图像,得到目标场景图像。
在上述实施例的基础上,所述获取模块包括:
提取单元,用于从目标视频中提取多帧目标场景图;
切割单元,用于针对任意所述多帧目标场景图,识别目标场景图中的人脸区域,切割目标场景图中的人脸区域部分,得到目标人脸图像集。
在上述实施例的基础上,所述目标神经网络至少包括4个卷积层和至少1个池化层。
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!