一种基于对抗生成网络的电力系统虚假数据攻击识别方法与流程
本发明属于电力系统运行安全维护技术领域,具体涉及一种基于对抗生成网络的电力系统虚假数据攻击识别方法。
背景技术:
长期以来,传统电网最重视的往往是电能质量是否达标可靠、电力设备是否安全经济,而造成了对电力系统网络安全的忽视。然而如今,在需求侧改革的推进下,现代电力市场的组成已较传统电网丰富得多,大量的通讯设备被随之引入,我国的电网也由传统电网逐步转型升级成为了一张遍布全国的信息物理耦合网。电力系统的网络安全问题在此背景下变得愈发严峻。虚假数据注入攻击(falsedatainjectionattack,fdia)是诸多电力系统网络安全问题中最典型,最受关注的一种问题。
fdia在电力系统中主要是通过篡改系统中的遥测信息来破坏状态估计的准确性与可靠性的目的。目前,fdia的检测方法是对送入能量管理系统的遥测信息进行异常检测,以确定要测信息中是否存在异常数据。在传统工作中,异常数据的检测是通过不良数据检测系统来实现的。然而国外的最新研究已经指出,传统不良数据检测并不能检测出含fdia篡改的遥测数据,含fdia篡改的遥测数据需要一个单独的模块对其进行检测。
目前电力系统fdia的检测在世界范围内仍属于疑难问题,尽管国内外已经存在针对该问题的研究论文数十篇,但工业界至今尚无针对fdia的成熟并得到广泛应用的解决办法。历代fdia检测的研究者在文献中的工作可以主要分为两类:1)利用概率模型等数学方法来检测fdia2)利用包含人工智能的方法来检测fdia。第一类方法之所以不能得到较好的应用是因为它们通常需要基于较强的假设条件,如:系统中的状态变量遵循特定分布,fdia是通过操纵仪表测量来影响电力系统状态估计的等等。过强的假设往往使得这些方法在真实的工作中寸步难行。第二类方法存在的不足是它们依赖于规模巨大的fdia异常训练样本,现实中的异常样本规模常常达不到这些方法的训练条件。这两类不足使得已有文献中的方法极少具备现实意义。
技术实现要素:
本发明所要解决的技术问题是电力系统含fdia量测数据难以被检测的问题,提供一种基于对抗生成网络的电力系统虚假数据攻击识别方法,对以往传统方法中过强的假设条件进行了简化,模型训练不依赖于大规模的fdia异常数据样本,满足工业上对含fdia量测数据检测的实用化要求。
本发明所要解决的技术问题,通过以下技术方案予以实现:
一种基于对抗生成网络的电力系统虚假数据攻击识别方法,包括以下步骤:
步骤一、建立线性状态估计模型,基于电力系统中遥测设备在全网各处采集到的遥测量进行状态估计得到估计状态量;以估计状态量根据线性状态估计模型进行反推,得到估计状态量对应的估计量测量;将估计量测量与真实量测量做差,得到残差量测量;残差量测量、估计量与真实量测量均留作fdia的被检测数据;
步骤二、通过对残差量测量进行基于给定阈值大小的二范数阈值检测滤除数据中由物理网运行故障、设备测量误差、通信系统噪音产生的不良数据,使系统中仅保留真实数据以及fdia篡改后的虚假数据;
步骤三、建立对抗生成网络模型,并用电力系统历史中的健康数据对对抗生成网络模型进行训练,得到成熟的电力系统参数判别模型与生成模型;将步骤一中保留的残差量测量、估计量与真实量测量均送入判别模型中进行判别,得到判别结果;若判别结果为不存在虚假数据则检测结束,否则进入步骤四;
步骤四、将被判断为存在异常的数据与生成模型的生成数据做差,得到定位残差;对定位残差数据进行基于给定阈值大小的二范数阈值检测以确定问题数据位置并滤除问题数据。
所述步骤1具体为:
建立线性状态估计模型为:
z=hx+e
其中,z为遥测量,h为代表拓扑的雅可比矩阵,e为状态估计的过程中难免产生误差和扰动;
状态量与量测量的关系为:
qk=0
pk-m=bk-m(θk-θm)
qk-m=0
其中,pk为节点k注入有功功率,qk为节点k注入无功功率,pk-m为k节点到m节点之间线路的有功功率,qk-m为k节点到m节点之间线路的无功功率,bk-m为导纳阵中(k,m)的虚部,bk-m为k节点到m节点之间线路的电纳,θk与θm分别为节点k和节点m的极坐标电压相角;
建立噪音最小二乘的目标函数来进行状态估计,目标函数表达式为:
minj(x)=[z-hx]tr-1[z-hx]
其中,r为权值矩阵;
根据梯度下降原理求得估计状态量:
得到估计状态量后根据线性关系对量测量进行反推得到估计量测量,其反推计算遵循式为:
通过式
步骤二所述通过对残差量测量进行基于给定阈值大小的二范数阈值检测滤除数据中由物理网运行故障、设备测量误差、通信系统噪音产生的不良数据,其检测遵循式为:
其中,τ1为常量阈值。
所述步骤三具体为:
所述对抗生成网络模型包含判别模型与生成模型,它们的目标函数为:
其中,上面的式子为生成模型在优化时的目标函数,下面的式子为判别模型在优化时的目标函数;对抗生产网络的核心在于引入判别模型与生成模型之间的竞争来使得两个模型都能在训练中获得长足的发展和优化,其竞争表现为判别模型希望做出正确的判断,而生成模型希望愚弄判别模型,两个模型围绕“能否准确判断”这一问题展开交替博弈;判别模型的输出结果d代表判别模型对输入数据真实性的信任程度,生成模型输出结果g为生成模型生产的模拟真实数据;生成模型的优化训练是通过愚弄判别模型来实现的,因此g的目标函数希望d的判断尽可能错误,即d(g(z))尽可能大;而判别模型的优化训练是通过提升其自身判断能别来实现的,因此d的目标函数希望d的判断尽可能正确,即d(g(z))尽可能小,同时在面对真实数据时d(x)尽可能大;e是二进制矩阵,具体数值根据送入数据来源决定,以保证不同来源数据的优化过程互不影响。
所述生成模型与判别模型均采用含交叉熵原理的反向传播神经网络,均包含三层神经元,两个线性加sigmoid激活函数的映射,各层神经元的数目依待检电网节点数目而定,第一层都是输入层,最后一层是输出层,中间一层则是隐藏层,正向传播的计算遵循公式为:
其中,an为第n层神经元的输出结果,ωn为第n层神经元向n+1层映射中的权重,bn为第n层神经元向n+1层映射中的偏置,r为神经网络的输入,s为神经网络的输出,σ代表sigmoid激活函数,其计算方法遵循式为:
其中,e为自然指数;
用神经网络的正向映射结果与给定优化目标基于交叉熵原理求输出层误差,其计算遵循式为:
再通过对输出层误差求偏导得到更新梯度,利用梯度下降原理反向更新全网络的权重与偏置,其计算方法遵循式为:
其中,y为预设的优化目标,c为输出层误差,ρi为梯度学习率;
通过反向传播训练即可得到成熟的判别模型和生成模型,将步骤一中保留的残差量测量、估计量与真实量测量送入成熟的判别模型即可得到fdia存在与否的判别结果,若判别结果为不存在fdia篡改则判别结束,若存在篡改则进入第四步。
步骤四所述对定位残差数据进行基于给定阈值大小的二范数阈值检测以确定问题数据位置并滤除问题数据,其检测遵循式为:
其中,ztotal为待检测数据的残差量测量、估计量与真实量测量的总和,
与现有技术相比,本发明具有以下有益效果:
(1)本发明解决了传统不良数据检测无法检测含fdia数据的问题。
(2)本发明并不基于非常强的情景假设,能适用多种类的fdia引发的问题,具有较好的工业实用性。
(3)本发明在对模型的训练上不依赖于大规模的异常数据训练样本,而是基于正常样本数据,克服了当下样本短缺,难以维持模型训练的问题。
附图说明
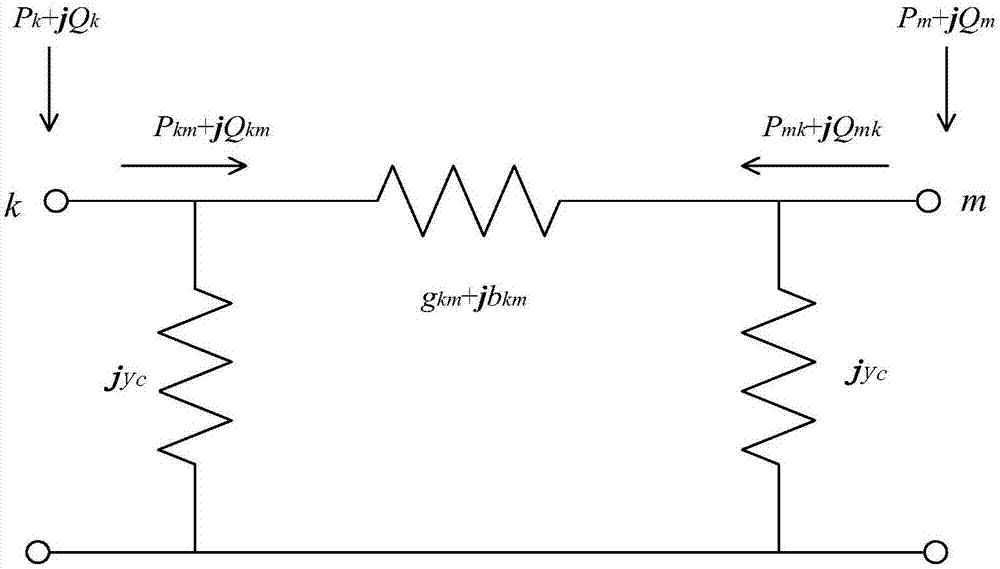
图1是π型等效线路模型图;
图2是对抗生成网络模型图;
图3是神经网络反向传播过程图;
图4是118节点系统训练表现图;
图5是118节点系统异常点定位结果图。
具体实施方式
为了能更清晰地理解本发明的上述目的、特征和优点,下面结合模型的具体实现形式对本发明技术方案进行进一步的详细描述。
一种基于对抗生成网络的电力系统虚假数据攻击识别方法,包括以下步骤:
步骤一、建立线性状态估计模型,将电力系统的状态量作为不确定集,与电力系统中的遥测量、雅可比矩阵和噪声建模;通过最小化噪声可求解估计状态量并反推估计状态量对应的估计量测量;将估计量测量与真实量测量做差,得到残差量测量;残差量测量、估计量与真实量测量均留作fdia的被检测数据。具体如下:
根据图1所示的π型等效线路模型图可见:电力系统中遥测量z=[pk,qk,pk-m,qk-m,vk]t与估计量x=[θk,vk]t存在非线性关系。基于假设:1)节点的标幺值电压均与1非常接近;2)电阻、纳均被是为0,即电路的损耗为0,相位差接近0,非线性联系可以被简化抽象为线性关系式,如式(1)所示。
z=hx+e(1)
在其中:h为代表拓扑的雅可比矩阵,e为状态估计的过程中难免产生误差和扰动。
在非线性状态估计模型中状态量与量测量一般存在如(2)中关系:
在经过上述假设简化后得到式(3)中的形式:
其中:pk为节点k注入有功功率,qk为节点k注入无功功率,pk-m为k节点到m节点之间线路的有功功率,qk-m为k节点到m节点之间线路的无功功率,gk-m为导纳阵中(k,m)的实部,bk-m为导纳阵中(k,m)的虚部,gk-m为k节点到m节点之间线路的电导,bk-m为k节点到m节点之间线路的电纳,y为对地电纳,vk与vm分别为节点k和节点m的电压幅值,θk与θm分别为节点k和节点m的极坐标电压相角。
为了使得状态估计尽量准确,应该尽量降低噪音,建立噪音最小二乘的目标函数来进行状态估计,目标函数如(4)所示。
minj(x)=[z-hx]tr-1[z-hx](4)
其中:r为权值矩阵。
根据梯度下降原理可求得估计状态量(5):
得到估计状态量后可根据线性关系对量测量进行反推得到估计量测量,其反推计算遵循式(6)。
由此可通过式(7)获取残差量测量。本发明将在本步骤中所采集到与产生的残差量测量、估计量与真实量测量均留作fdia的被检测数据。
在其中:δz为残差量测量。
步骤二、通过对残差量测量进行基于给定阈值大小的二范数阈值检测滤除数据中由物理网运行故障、设备测量误差、通信系统噪音产生的不良数据,使系统中仅保留真实数据以及fdia篡改后的虚假数据。具体如下:
一般而言,由于物理网运行故障、设备测量误差、通信系统噪音使电力系统遥测量测数据总是会存在受污染的不良数据,为了减少虚假数据判别的工作量和难度,本发明首先利用不良数据检测来滤除量测数据中的不良数据,仅留下正常数据和虚假数据供下一步的虚假数据判别器检测。
采用残差二范数阈值检测来滤除不良数据,其检测遵循式(8)。
在其中:τ1为常量阈值。当(12)式成立则表明被检测数据中有不良数据存在,需要滤除量测量中最大误差量并重新进行检测直至检测通过。
本发明的这一步骤能够极大地提高后续检测的效率,减少虚假数据识别的工作量和难度,从而提高虚假数据判别的准确率。
步骤三、建立对抗生成网络模型,该对抗生成网络模型包括判别模型和生成模型,判别模型和生成模型为对称的一组三层神经网络;用电力系统历史中的健康数据对对抗生成网络模型进行训练,得到成熟的判别模型与生成模型;将步骤一中保留的残差量测量、估计量与真实量测量均送入成熟的判别模型中进行判别,得到判别结果;若判别结果为不存在虚假数据则检测结束,否则进入步骤四。具体如下:
如图2所示,搭建模型包含一个生成模型和一个判别模型。生成模型用于生成与真实数据接近的虚假数据,判别模型用于判断送入的数据的来源是生成模型还是真实样本。当判别模型判别正确时,说明生成模型能力不足,因而优化生成模型,反之则优化判别模型。通过生成模型和判别模型的对抗和竞争,两种模型都能得到进步。最后,由于训练数据是历代的健康数据,成熟的判别模型能够判别出送入的数据是否完全健康,有没有存在fdia篡改。而生成模型则可以生产与健康样本非常类似的数据。
该模型能通过建立如式(9)的目标函数来实现。其中上面的式子为生成器g在优化时的目标函数,下面的式子为判别器d在优化时的目标函数。
生成模型与判别模型均采用含交叉熵原理的反向传播神经网络。根据图3所示,生成模型和判别模型均包含三层神经元,两个线性加sigmoid激活函数的映射。各层神经元的数目依待检电网节点数目而定。它们的第一层都是输入层,最后一层是输出层,中间一层则是隐藏层。它们正向传播的计算遵循公式(10)。
在其中:an为第n层神经元的输出结果,ωn为第n层神经元向n+1层映射中的权重,bn为第n层神经元向n+1层映射中的偏置,r为神经网络的输入,s为神经网络的输出,σ代表sigmoid激活函数,其计算方法遵循式(11)。
在其中:e为自然指数。
根据图3,用神经网络的正向映射结果与给定优化目标基于交叉熵原理求输出层误差,其计算遵循式(12)。再通过对输出层误差求偏导得到更新梯度,利用梯度下降原理反向更新全网络的权重与偏置,其计算方法遵循式(13)。通过反向传播训练即可得到成熟的判别模型和生成模型。
在其中:y为预设的优化目标,c为输出层误差,ρi为梯度学习率。
将步骤一的待检测数据的残差量测量、估计量与真实量测量送入训练成熟的判别模型即可得到fdia存在与否的判别结果。若判别结果为不存在fdia篡改则判别结束,若存在篡改则进入第四步。
步骤四、将被判断为存在异常的数据与生成模型的生成数据做差,得到定位残差。对定位残差数据进行基于给定阈值大小的二范数阈值检测以确定问题数据位置并滤除问题数据。其检测遵循式(14)。
在其中:ztotal为待检测数据的残差量测量、估计量与真实量测量的总和,
当(14)式成立则要滤除量测量中最大误差量并记录滤除位置,重新进行检测直至检测通过。
实例分析
分别从以下四个部分进行说明:健康样本获取、对抗生成网络的训练情况、判别模型的判别精确度情况、异常点定位的精确度情况。
一、健康样本获取
算例的样本源于具有极高国际认可度的ieee118节点系统的量测数据。执行以下操作可获得单组118节点系统的状态估计健康样本:通过断开118节点系统量测数据中的部分线路来模拟正常运行情况下的该电力系统拓扑结构变化,按照步骤一可得到当前拓扑下的118节点系统的状态估计健康样本。对118节点系统数据重复上述操作118次可获得118组训练样本集。
二、对抗生成网络的训练情况
在训练过程中主要通过观察生成数据与真实数据之间的差距来评估训练情况的好坏。如上所述,生成模型和判别模型是在对抗中共同成长的,生成数据与真实数据之间的差距反映了生成模型的训练情况,也同时反映了判别模型的训练情况。在118组训练样本中随机抽取一组作为一代训练的样本输入模型中,反复迭代四万代。118节点系统训练中的表现呈现于图4。由于代数过多,每隔100代抽取生成数据与真实数据进行比对,算出当代的平均误差和误差方差。图中虚线与实线两条线分别代表历代生成模型的平均误差与误差方差走势。可以看出,训练过程平稳,效果良好。平均一路下降至接近零点,最终平均误差降至不到0.01,而误差方差达十的负四次方数量级。归一化的数据主要分布在[0.3,0.7]之间,0.01不足0.3的5%,可见118节点系统训练成功。
三、判别模型的判别精确度情况
表1为118节点系统判别模型的混淆矩阵。将93组健康样本与25组基于fdia原理篡改的异常样本随机排列,作为判别模型的检测样本集。检测结果通过混淆矩阵被可视化。93组健康样本判别准确率为100%,25组异常样本判别准确率为96%,综合准确率达99.15%。判别模型准确较高。
表1
四、异常点定位的精确度情况
利用训练好的模型对有fdia入侵的118个数据量(线性量测量p)进行异常点定位。在有25个点遭受fdia攻击(25/118)的情况下,异常点定位结果图如图5所示。检测判断图中“1”代表存在异常,“0”代表无异常。圆圈代表测试样本的真实情况,星状点代表定位结果,圈与点重合则定位正确。如结果见,定位准确率高于90%。
- 还没有人留言评论。精彩留言会获得点赞!