一种中文人名识别方法与流程
本发明涉及一种中文人名识别方法,属于信息技术领域。
背景技术:
命名实体识别是信息抽取的一项子任务,其目的是从海量的文本数据中抽取出指定的实体。在自然语言处理应用领域中,命名实体识别是信息检索、机器翻译、情感分析等多项自然语言处理应用的基础任务,而中文人名识别是命名实体识别的一个子问题,因此,对它的研究具有重要意义和价值。
一般地,中文语义复杂,中国人名的用字又具有很大的任意性,所以传统的命名实体识别技术不能有效地识别出新词;同时,由于中国人名数量众多、没有形态上的特征、规律各异、包含生僻字等特点,所以传统的基于规则的中文人名识别技术由于可移植性差,会使得对人名的识别会变得不够准确,以上所述都会给中文人名识别造成困难。
技术实现要素:
本发明要解决的技术问题是针对现有技术的局限和不足,提供一种中文人名识别方法,引入贝叶斯决策,解决了传统的基于规则的中文人名识别技术规则的可移植性差,对中文人名的识别存在歧义,从而使得中文人名识别结果准确率低的现象,以提高中文人名识别的准确性。
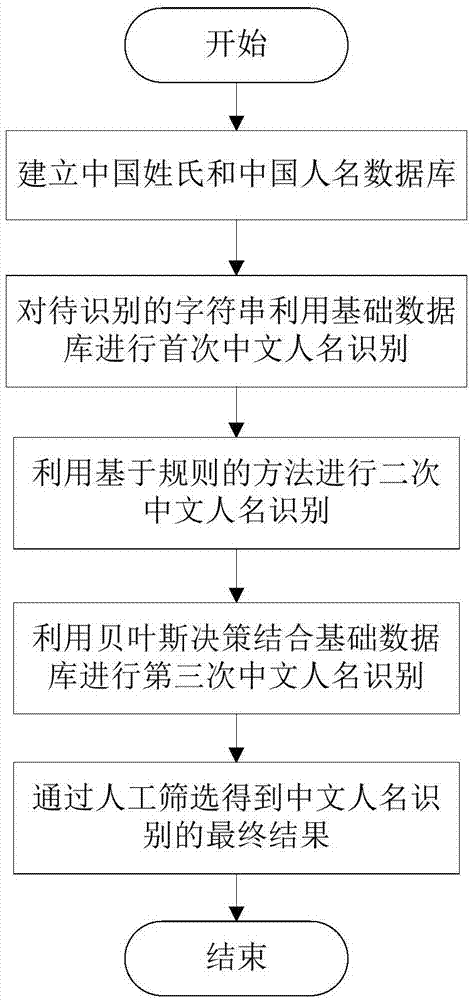
本发明的技术方案是:一种中文人名识别方法,引入贝叶斯决策对传统的基于规则的中文人名识别技术进行改进,首先建立中国姓氏和中国人名数据库作为基础数据库;接着对待识别的字符串利用基础数据库进行首次中文人名识别;然后利用基于规则的方法进行二次中文人名识别;接着利用贝叶斯决策结合基础数据库进行第三次中文人名识别;最后通过人工筛选得到中文人名识别的最终结果。
具体步骤为:
①建立中国姓氏和中国人名数据库。
②对待识别的字符串利用基础数据库进行首次中文人名识别。
③利用基于规则的方法进行二次中文人名识别。
④利用贝叶斯决策结合基础数据库进行第三次中文人名识别。
⑤通过人工筛选得到中文人名识别的最终结果。
进一步地,步骤①所述的中国姓氏和中国人名数据库用作中文人名识别的基础数据库,可通过《百家姓》和维基百科得到。
进一步地,步骤②所述的首次中文人名识别的具体实现为:将待识别的字符串匹配所述中国人名数据库,判断待识别的字符串是否包含中国人名数据库中的人名,若包含,则提取出人名,再进行步骤③所述的基于规则的二次中文人名识别;若不包含,则直接进行二次中文人名识别。
进一步地,步骤③所述的基于规则的二次中文人名识别的具体实现为:匹配所述中国姓氏数据库,判断待识别的字符串中是否含有中国姓氏数据库中的姓氏,若不含有,则该字符串不含有人名,若含有,则提取出该姓氏以及其前后两个字作为疑似含有人名的字段等待下一步处理。
进一步地,所述的疑似含有人名的字段的下一步处理的具体实现为:首先匹配所述中国姓氏数据库,判断姓氏前两个字是否含有中国姓氏数据库中的姓氏,若含有,则该姓氏不作为姓氏处理,将前一个姓氏作为姓氏处理,若不含有,则将该姓氏后两个字匹配所述中国人名数据库,判断其中是否含有中国人名数据库中的名字,若含有,则提取出名字,结合姓氏组成人名,若不含有,则进行步骤④所述的第三次中文人名识别。
进一步地,步骤④所述的利用贝叶斯决策进行第三次中文人名识别的具体实现为:利用贝叶斯公式计算疑似含有人名的字段中姓氏后两个字的后验概率p(b|a),若p(b|a)大于或等于门限值λ,则将该两个字作为名,否则该两个字不作为名。
进一步地,所述的疑似含有人名的字段中姓氏后两个字的后验概率p(b|a)的计算公式为:
其中,a为第一个字,b为第二个字,p(a)和p(b)为先验概率,即a和b在基础数据库出现的概率,p(a|b)为类条件概率密度,即在b出现的条件下a出现的概率。
进一步地,所述的类条件概率密度p(a|b)通过训练样本用最大似然法得到。
进一步地,所述的门限值λ通过测试实验确定。
进一步地,步骤⑤所述的人工筛选的具体实现为:在得到候选的人名后,通过人工进行最后的判定,若人名中存在消极或者不符合取名习惯的字眼,则过滤掉不作为人名,否则作为最终的人名识别结果。
本发明的有益效果是:通过引入贝叶斯决策,解决了传统的基于规则的中文人名识别技术规则的可移植性差,对中文人名的识别存在歧义,从而使得中文人名识别结果准确率低的现象,以提高中文人名识别的准确性。
附图说明
图1是本发明流程示意图;
图2是本发明步骤②~③流程示意图;
图3是本发明步骤④~⑤流程示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种中文人名识别方法,首先建立中国姓氏和中国人名数据库作为基础数据库;接着对待识别的字符串利用基础数据库进行首次中文人名识别;然后利用基于规则的方法进行二次中文人名识别;接着利用贝叶斯决策结合基础数据库进行第三次中文人名识别;最后通过人工筛选得到中文人名识别的最终结果。
具体步骤为:
①建立中国姓氏和中国人名数据库。
②对待识别的字符串利用基础数据库进行首次中文人名识别。
③利用基于规则的方法进行二次中文人名识别。
④利用贝叶斯决策结合基础数据库进行第三次中文人名识别。
⑤通过人工筛选得到中文人名识别的最终结果。
进一步地,步骤①所述的中国姓氏和中国人名数据库用作中文人名识别的基础数据库,可通过《百家姓》和维基百科得到。
进一步地,步骤②所述的首次中文人名识别的具体实现为:将待识别的字符串匹配所述中国人名数据库,判断待识别的字符串是否包含中国人名数据库中的人名,若包含,则提取出人名,再进行步骤③所述的基于规则的二次中文人名识别;若不包含,则直接进行二次中文人名识别。
进一步地,步骤③所述的基于规则的二次中文人名识别的具体实现为:匹配所述中国姓氏数据库,判断待识别的字符串中是否含有中国姓氏数据库中的姓氏,若不含有,则该字符串不含有人名,若含有,则提取出该姓氏以及其前后两个字作为疑似含有人名的字段等待下一步处理。
进一步地,所述的疑似含有人名的字段的下一步处理的具体实现为:首先匹配所述中国姓氏数据库,判断姓氏前两个字是否含有中国姓氏数据库中的姓氏,若含有,则该姓氏不作为姓氏处理,将前一个姓氏作为姓氏处理,若不含有,则将该姓氏后两个字匹配所述中国人名数据库,判断其中是否含有中国人名数据库中的名字,若含有,则提取出名字,结合姓氏组成人名,若不含有,则进行步骤④所述的第三次中文人名识别。
进一步地,步骤④所述的利用贝叶斯决策进行第三次中文人名识别的具体实现为:利用贝叶斯公式计算疑似含有人名的字段中姓氏后两个字的后验概率p(b|a),若p(b|a)大于或等于门限值λ,则将该两个字作为名,否则该两个字不作为名。
进一步地,所述的疑似含有人名的字段中姓氏后两个字的后验概率p(b|a)的计算公式为:
其中,a为第一个字,b为第二个字,p(a)和p(b)为先验概率,即a和b在基础数据库出现的概率,p(a|b)为类条件概率密度,即在b出现的条件下a出现的概率。
进一步地,所述的类条件概率密度p(a|b)通过训练样本用最大似然法得到。
进一步地,所述的门限值λ通过测试实验确定。
进一步地,步骤⑤所述的人工筛选的具体实现为:在得到候选的人名后,通过人工进行最后的判定,若人名中存在消极或者不符合取名习惯的字眼,则过滤掉不作为人名,否则作为最终的人名识别结果。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!