并发多位加法器的制作方法
本申请要求2017年8月30日递交的美国专利申请15/690,301的优先权,其通过引用并入本文。
本发明通常涉及相联存储器(associativememory),并且尤其涉及用于并发位相加的方法。
背景技术:
在许多计算机和其他种类的处理器中,加法器不仅用在算术逻辑单元中,而且还用在其他部分中,其中它们用于计算地址、表索引、递增和递减运算符以及类似运算。
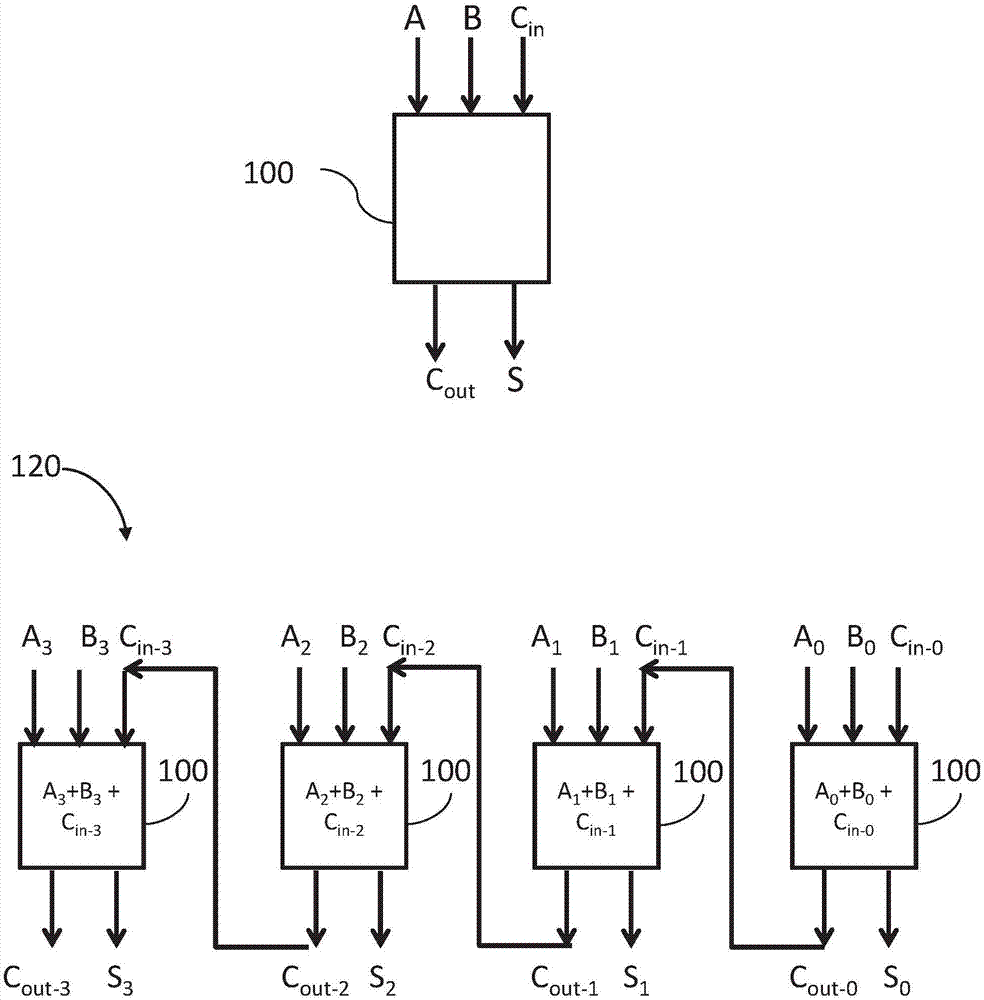
现在参考图1,示出了本领域中已知的一位全加器100和多位行波进位(ripplecarry)加法器120。一位全加器100接收三个一位值作为输入a、b和cin,并将它们相加。一位全加器100的输出是三个输入位的计算和s以及来自该加法运算的进位输出(carryout)cout。
多位行波进位加法器120可以用于将n位变量a和b相加。多位行波进位加法器120可以由n个一位全加器100构成。每个全加器100输入来自变量a的位ai和来自变量b的位bi。每个全加器还输入进位输入(carryin)cin-i,它是前一加法器的进位输出cout-i-1。
现在参考图2,示出了本领域已知的示例性四位行波进位加法器120,用于将两个4位变量a=1110和b=0101相加,并且包括四个一位全加器100:100a、100b、100c和100d。
全加器100a的输入位是a的最低有效位(lsb)(例如0),b的lsb(例如1),以及对于第一全加器而言被定义为0的进位输入。全加器100a可以执行计算(在该示例中为0+1+0)。全加器100a的输出位是值为1的结果位s和值为0的进位输出位cout。全加器100a的cout变为全加器100b的cin。可以理解,全加器100b要仅在全加器100a的计算完成之后才开始其计算,并且相同的约束适用于包括100c和100d的所有全加器,除了第一个全加器。最后一个全加器100d的最后一个cout被称为计算的溢出。
该示例的计算步骤是:在步骤1中,将两个变量的位0(lsb)相加,得到位s0和进位输出位cout-0。在步骤2中,将两个变量的位1和前一步骤的进位输出cout-0相加,得到位s1和进位输出位cout-1。在步骤3中,将两个变量的位2和前一步骤的进位cout-1相加,得到位s2和进位输出位cout-2。最后,在步骤4中,使两个变量的位3和前一步骤的进位cout-2相加,得到位s3和进位输出位cout-3。加法运算的结果是来自所有步骤的所有位s和最后的进位输出,如果其值为1则为溢出。
可以理解,计算步骤可以仅在其所有输入值,即ai、bi和cin-i,都已知时开始。ai和bi提前已知(来自输入数a和b的位)。第一cin为0(这是第一步骤,没有前一步骤,因此没有值进位到该步骤)。每个步骤中的cin值(第一个除外)仅在前一步骤的计算完成之后才知道,因为它是较前步骤的cout。
可以理解,当将大量多位值相加时,行波进位加法器可能变得非常慢。整个行波进位加法计算是串行的,其复杂度为o(n),这是一个缺点。
技术实现要素:
根据本发明的优选实施例,提供一种用于相联存储器设备的方法。所述方法包括:在所述相联存储器设备的存储器阵列的列中存储多对多位数,每对在一个列中;将存储在所述列的每个列中的位分成组。所述方法还包括:在每一列中,在预测所有所述组的进位输入值是第一值的情况下在每组内第一次并发执行行波进位,以提供所述组中每个位的第一预测进位输出值。在每一列中,在预测所有所述组的进位输入值是第二值的情况下在每组内第二次并发执行行波进位,以提供所述组中每个位的第二预测进位输出值,并且在每一列中,根据前一组的实际进位输出来选择以下中的一个:所述第一预测进位输出值和所述第二预测进位输出值,以提供最终进位输出。
另外,根据本发明的优选实施例,所述第一次并发执行和所述第二次并发执行通常并行地发生。
此外,根据本发明的优选实施例,用于所述选择的第一组是一组最低有效位,并且用于所述选择的最后一组是一组最高有效位。
此外,根据本发明的优选实施例,第一组的进位输入是零或者输入。
此外,根据本发明的优选实施例,所述方法还包括:并发地将每个所述对的第一个数的每个位j、每个所述对的第二个数的每个位j和所述最终进位输出的每个位j-1相加,用作位j的进位输入,由此产生所述两个多位数的总和。
另外,根据本发明的优选实施例,所述第一执行行波进位和所述第二执行行波进位包括:并发地计算和存储在每个所述对的第一个数的每个位j与每个所述对的第二个数的每个位j之间的布尔or运算的结果;并发地计算和存储在每个所述对的第一个数的每个位j与每个所述对的第二个数的每个位j之间的布尔and运算的结果;并且并发地使用所述结果用于所述行波进位。
根据本发明的优选实施例,提供一种系统,包括:非破坏性相联存储器阵列和预测器、选择器以及求和器。所述存储器阵列包括多个部分,每个部分包括按行和列布置的单元,用于在部分j中的同一列中存储来自第一多位数的位j和来自第二多位数的位j。所述预测器通常并发地预测每个所述部分中的多个进位输出值;并且所述选择器对于所有位选择经预测的进位输出值中的一个。所述求和器通常对于所有位使用经选择的进位输出值来并发地计算所述多位数的总和。
另外,根据本发明的优选实施例,所述多位数的所述位被分成多个位组。
此外,根据本发明的优选实施例,所述预测器在所述存储器阵列的c0行中存储根据每个所述组的进位输入值是第一值的预测而产生的进位输出值;并且在所述存储器阵列的c1行中存储根据每个所述组的进位输入值是第二值的预测而产生的进位输出值。
此外,根据本发明的优选实施例,所述选择器对于每一组在所述存储器阵列的cout行中存储根据前一组的实际进位输出而从行c0和行c1中的一个所取的进位输出值。
另外,根据本发明的优选实施例,所述求和器在所述存储器阵列的总和行中存储所述两个多位数的位j和所述cout值的位j-1的总和。
附图说明
在说明书的结尾部分中特别指出并清楚地请求保护被视为本发明的主题。然而,当结合附图阅读时,通过参考以下详细描述,可以最好地理解本发明的组织和操作方法以及其目的、特征和优点,在附图中:
图1是本领域中已知的一位全加器和多位行波进位加法器的示意图;
图2是本领域已知的用于将两个4位变量相加的示例性四位行波进位加法器的示意图;
图3是根据本发明优选实施例构造和操作的多位并发加法器的示意图;
图4是根据本发明优选实施例构造和操作的相联存储器阵列的示意图;
图5是存储在根据本发明优选实施例构造和操作的相联存储器阵列的一部分中的数据的示意图;
图6是根据本发明的优选实施例在通过图3的并发加法器执行以并发地使两个8位操作数相加的加法运算期间存储在存储器阵列的各行中的内容的示意图;以及
图7是示出根据本发明优选实施例由图3的并发加法器执行的运算的流程图。
应当理解,为了说明的简单和清楚,附图中所示的元件不一定按比例绘制。例如,为了清楚起见,一些元件的尺寸可以相对于其他元件被放大。此外,在认为适当的情况下,可以在附图中重复附图标记以指示相应或类似的元件。
具体实施方式
在以下详细描述中,阐述了许多具体细节以便提供对本发明的全面理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践本发明。在其他情况下,没有详细描述众所周知的方法、过程和部件,以免模糊本发明。
本领域已知的是,一位计算的和s和进位输出cout可以由等式1和2表达:
cout=a*b+cin*(a+b)等式2
其中,符号
cout-n=an*bn+an-1*bn-1*(an+bn)+an-2*bn-2*(an-1+bn-1)*(an+bn)+………cin*(a0+b0)*(a1+b1)…..(an+bn)等式3
使用该技术,可以将变量的位分成组(例如半字节),并且可以无需等待完成每个位计算来计算组的进位,在此被称为cout-group,即,来自组中的最后一位的进位。使用cla,可以改善多位加法器的性能(与行波进位相比);然而,cla可能仅使用专门的硬件实现,其被明确设计为使用组的所有输入位来计算组的预期进位输出,即,变量a的所有位、变量b的所有位和组的cin(这里被称为cin-group)。
申请人已经认识到,通过使用关于下文描述的进位输入的值的预测执行计算,可以通过替代专用硬件的多用途相联存储器来提供类似的进位传送功能,其与行波进位加法器相比改善了多位加法器的计算效率。
在2012年8月7日授权的美国专利no.8,238,173(发明名称为“usinstoragecellstoperformcomputation”);2015年5月14日公开的美国专利公开no.us2015/0131383(发明名称为“non-volatilein-memorycompuingdevice”);2016年8月16日授权的美国专利号9,418,719(发明名称为“in-memorycomputationaldevice”);以及2017年1月31日授权的美国专利号9,558,812(发明名称为“srammulti-celloperations”)中描述了多用途相联存储器,所有上述文献被转让给本发明的共同受让人,并且通过引用并入本文。
申请人已经进一步认识到,可以使用位线处理器来使计算并行化,每位一个位线处理器,如2017年7月16日提交的美国专利申请15/650,935(发明名称为“in-memorycomputationaldevicewithbitlineprocessors”),该专利申请于2017年11月2日公布并且公开号为us2017/0316829,其被转让给本发明的共同受让人,并且通过引用并于此文。
现在参考图3,示意性地示出了根据本发明优选实施例构造和操作的多位并发加法器300。多位并发加法器300包括并发加法器310和相联存储器阵列320。相联存储器阵列320可以将每对操作数a和b存储在一列中,并且还可以将计算的中间和最终结果存储在同一列中。并发加法器310包括预测器314、选择器316和求和器318,下面将更详细地描述。
现在参考图4,示意性地示出了相联存储器阵列320。相联存储器阵列320包括多个部分330,每个部分330包括行和列。每个部分330可以存储操作数a和b的不同位。操作数的位0可以存储在部分0中,位1可以存储在部分1中,依此类推,直到位15可以存储在部分15中。可以看出,两个操作数a和b的每个位j可以存储在相同部分j的相同列k的不同行中。特别地,操作数a的位a0存储在部分0的行a、列c-k中,并且操作数b的位b0存储在相同部分的相同列c-k中的不同行(行b)中。操作数a和b的其他位类似地存储在相联存储器阵列320的附加部分330中。
(图3的)并发加法器310可以利用每个部分330的附加行来存储中间值、预测和最终结果,如图5所示,并且现在对其进行参考。如上所述,并发加法器310可以在部分x中在行a中存储来自操作数a的位x并且在行b中存储来自操作数b的位x。此外,并发加法器310可以在行aorb中存储对在行a和b上存储的位执行的布尔or的结果。在行aandb中,并发加法器310可以存储对存储在行a和b上的位执行布尔and的结果。存储在行aorb和aandb中的值可以稍后用于计算进位输出。
在c0、c1和cout中,并发加法器310可以存储与进位输出相关的值。预测器314可以使用行c0来存储使用(到该组的)进位输入的值为0的预测来计算的cout的值。预测器314可以使用行c1来存储使用(到该组的)进位输入的值为1的预测来计算的cout的值。选择器316可以选择求和器318用于计算总和的实际值,并且可以在完成前一组的进位输出的计算时在已知进位输入的实际值之后将其存储在行cout中。在行sum中,求和器318可以存储来自操作数b的位x、来自操作数a的位x和来自先前计算的进位输出(用作进位输入)的总和。
如前所述,与特定总和计算相关的所有数据都可以存储在每个部分的单个列中,并且每列可以存储不同的变量以并发执行多个加法运算,使得关于特定的一对变量的计算可以在col0中执行,而对两个其它变量的完全不相关的计算可以在不同的列(例如col1)中执行。
根据本发明的优选实施例,(图3的)并发加法器310可以涉及具有n位的每个变量,作为每个具有几组m位的变量。例如,16位变量x15x14x13x12x11x10x9x8x7x6x5x4x3x2x1x0可以分为4组4位,x15x14x13x12,x11x10x9x8,x7x6x5x4和x3x2x1x0。使用该方案,并发加法器310可以将每个变量a和b分成大小为m的组,并且可以在组的级别中执行计算。可以理解,操作数的位数和组的大小不限于特定大小,并且在当前应用中描述的相同步骤和逻辑可以应用于具有被分成更大或更小的组大小的更多或更少位的操作数。
现在参考图6,示意性地示出了由并发加法器310执行以在表600中并发地将两个8位操作数a和b相加的步骤的示例。可以理解,表600的结构仅意在便于理解由多位并发加法器300(图3)执行的过程,并且不适用于相联存储器阵列320的硬件结构。例如,行610可以包含在步骤#1中写入的数a的所有位,每一位存储在被标记为相同的标签a的不同部分中的不同行中,这可以从图4和图5中得到理解。在表600的示例中,a=01110110并且b=11101011。表600示出了存储在相联存储器阵列320的不同部分的不同行中的数据。表600在列620中提供步骤编号,在列630中提供行,在列640中提供由并发加法器310对不同部分330执行的动作。包含在每个部分7-0中的值分别由列657-650提供。
并发加法器310可以将变量a的每个位存储在专用部分330中。变量a的lsb存储在部分0的行a中,下一位存储在部分1的行a中,依此类推,直到变量a的msb存储在部分7的行a中。变量b类似地存储在部分1至7的行b中。变量a和b可以分成两组,每组4位:包括部分0、1、2和3的半字节0以及包括部分4、5、6和7的半字节1。在步骤#1中,并发加法器310可以将变量a写入行a。前四位0110可以存储在半字节0中,而其他位0111可以存储在半字节1中。类似地,在步骤#2中,并发加法器310可以将变量b的第一组位(其为1011)写入半字节0,并将变量b的第二组(1110)写入半字节1。
然后,并发加法器310可以在步骤#3中计算布尔or的结果,并且在步骤#4中计算每个部分中的操作数a和b的位之间的布尔and,如在等式4和5中定义的。
aorb=ai+bi等式4
aandb=ai*bi等式5
并发加法器310可以将等式4和5的结果分别存储在行aorb和aandb中。可以理解,并发加法器310可以并发执行所有部分上的每个步骤的计算,即,在存储操作数a和b的位的所有部分上以单个步骤计算等式4。此外,可以在相联存储器阵列320的所有列上并发执行等式4。
在计算并且在行aorb和aandb中存储值之后,并发加法器310可以使用等式6的标准行波进位公式来并行地计算所有组内的进位输出。
cout=a*b+cin*(a+b)=aandb+(cin*aorb)等式6
对于大小为m的组,组内的行波进位可以采取m个步骤。
由于除了第一组之外的所有组的进位都不是预先知道的,所以可以在每组内计算两次行波进位。预测器314可以在组的输入进位为0(cgroup-in=0)的预测下执行第一计算,并且在组的输入进位为1(cgroup-in=1)的预测下执行第二计算。预测器314可以将计算出的进位输出存储在每个部分中的专用行中。预测器314可以将假设cgroup-in=0计算出的进位值存储在行c0中,并且将假设cgroup-in=1计算出的进位值存储在行c1中。
等式6的标准行波进位可以在步骤5中在假设cgroup-in=0的每组的第一部分上、在步骤6中在每组的第二部分上、在步骤7中在每组的第三部分上以及在步骤8中在每组的第四部分上执行。
等式6的标准行波进位可以在步骤6中在假设cgroup-in=1的每组的第一部分上、在步骤7中在每组的第二部分上、在步骤8中在每组的第三部分上以及在步骤9中在每组的第四部分上执行。
因而,两个行波进位运算可以在仅m+1个步骤中执行,这是因为,由于位可以存储在不同的部分中并且计算可以在任意数量的部分上并发进行,因此并发加法器310可以在使用cgroup-in=0计算组的第一位的进位输出之后立即开始假设cgroup-in=1的计算。
在组内完成标准行波进位并且行c0和c1存储针对组的所有位的值之后,并发加法器310可以执行组之间的行波进位。
如果没有来自先前计算的进位输入,则第一组的cgroup-in可以是零,并且如果当前计算是在多步骤过程中的步骤,则第一组的cgroup-in可以是先前计算的进位输出,例如使用4轮16位数的并发相加来使64位数相加。在步骤9中,选择器316可以根据第一组的cin的实际值将第一半字节的正确行的值写入行cout。由于只有在计算出前一组的最后一位的进位输出时才知道cgroup-in的实际值,所以在已知前一组的cgroup-out之后,选择器312可以选择该组的进位位的相关值,即,从行c0或行c1中选择。在该示例中,第一组的cgroup-out(存储在部分3的行c0中的值)是1,并且选择器316可以选择第二组的行c1作为半字节1的进位位的实际值。然后,在步骤10中,选择器316可以将半字节1的部分(部分4、5、6和7)的行c1的值写入相关部分的行cout。
在本发明的优选实施例中,选择器316可以使用等式7选择每组的cout的值。
cout=(c1*cprev-group-out)+(c0*(not(cprev-group-out))等式7
在标准行波进位加法器的m个步骤之后提供第一组的cgroup-out(对于如图6的示例中的半字节,4个步骤)。在标准行波进位加法器的m+1个步骤之后提供下一组的cgroup-out,因为它是针对cgroup-in=0和cgroup-in=1计算的,它们可以在使用cgroup-in=0计算组的第一位之后开始。
一旦所有组的所有部分中的进位的所有值都已知,求和器318就可以在步骤11中使用等式8并发计算所有部分中的所有位的总和。
其中cin是前一部分的cout。
现在参考图7,其是描述并发加法器310可以执行的用于使操作数a和b相加的步骤的流程图700。在步骤710中,并发加法器310可以将操作数a和b存储在存储器阵列320的部分330中。在步骤720中,并发加法器310可以并发地计算所有部分330中的操作数a和b的位之间的布尔or。在步骤730中,并发加法器310可以并发地计算所有部分330中的操作数a和b的位之间的布尔and。在步骤740、742和744中,预测器314可以并行地执行所有组内的行波进位,假设cgroup-in=0,并且在步骤750、752和754中,预测器314可以并行地执行所有组内的行波进位,假设cgroup-in=1。在步骤760中,选择器316可以使用cgroup-in=0来计算第一组的进位输出。在步骤770和780中,选择器316可以计算下一组的进位输出,直到计算出最后一组的进位输出,并且可以为该组的实际cout选择正确的进位行。当计算最后组的cout时,求和器318可以在步骤790中计算总和。
本领域技术人员可以理解,所示的步骤并非意在是限制性的,并且可以用更多或更少的步骤或者以不同的步骤次序或其任何组合来实施该流程。
可以理解,为了将划分为四个半字节的两个16位操作数相加,并发加法器310可以执行以下过程:
a.计算a+b(针对所有位并行地)
b.计算a*b(针对所有位并行地)
c.计算cin(针对所有组并行地)(总共8个步骤)
a.半字节内行波进位(总共5个步骤)
i.半字节0:半字节行波进位cin=0(4个步骤)
ii.半字节1-3:半字节行波进位cin=0和cin=1(5个步骤)
b.半字节之间的行波进位(3个步骤)
d.计算总和:
可以理解,并发加法器310可以执行用于计算16位变量之和的与在8位数的示例中相同的步骤,具有针对第三组和第四组的“组间行波进位”的2个附加步骤。还可以理解,并发加法器310可以在两个阶段中使用并发加法器。在第一阶段,计算变量的最低有效位的进位输出,并且最后一位的进位输出或计算的溢出是在计算变量的最高有效位时使用的输入进位输入值。
可以进一步理解,总的进位行波计算时间可以包括:a)在单个组内执行标准行波进位需要的步骤,等于组中的位数量m(在该示例中半字节中的4个步骤),b)假设cin的另一个值,计算组内的第二标准行波进位,这可能需要一个额外的步骤,因为组中第一位的计算可以在完成该位的先前计算之后立即开始,以及c)在组之间组的数量减1个行波,因为每组的cout需要波动到下一组。例如,当将分成四个半字节(每个半字节的大小为4)的两个16位数相加时,行波进位的计算复杂度是4+1+3=8,而针对相同计算使用标准行波进位的计算复杂度会是16。
可以理解,多位并发加法器300可以并发地对存储在存储器阵列320的多个列中的多对操作数执行多个加法运算,每对操作数存储在不同的列中。可以在单个列上执行全加运算。存储器阵列320可以包括p列,并且多位并发加法器300可以并发地对所有列进行操作,由此在此时执行p个多位加法运算。
虽然本文已经说明和描述了本发明的特定特征,但是本领域普通技术人员现在将想到许多修改、替换、改变和等同物。因此,应该理解,所附权利要求意在覆盖落入本发明的真正精神内的所有这些修改和变化。
- 还没有人留言评论。精彩留言会获得点赞!