一种基于聚类离散点检测的反窃电方法与流程
本发明涉及电力大数据应用领域,特别是一种基于聚类离散点检测的反窃电方法。
背景技术:
近些年,随着经济的增长和用电量的增多,窃电问题越来越突出,这种行为严重损害了国家、电网公司及其他正常用电用户的利益,并扰乱了发电、供电及用电的正常秩序,对社会带来了极大的负面影响。同时,高科技窃电行为逐渐增多,如利用无线遥控装置窃电、利用编程器对电表调节电量、倒表码等方式进行窃电,这些方式都增加了反窃电的难度。但是,随着信息通信技术、计算机技术、大数据技术等先进技术的发展,将这些先进的技术和理念融合进反窃电管理、终端用电管理中成了反窃电研究的一个重要方向。
目前,传统的反窃电监测手段是通过gprs远传的计量电表数据人工进行数据时段对比与分析,可发现电压方式及错相序方式窃电,部分有经验的现场人员也可通过分析负荷及现场人工排查发现电流方式窃电行为。这些方法即时性差,要建立在采集数据完全正确和大量人工经验的基础上,对分流、遥控器等高科技窃电方式难以有效预防,只能事后处理,无法事前预防等突出问题。
技术实现要素:
有鉴于此,本发明的目的是提出一种基于聚类离散点检测的反窃电方法,能够对用户用电数据进行聚类分析,并得到可疑窃电用户,并能对管理员推送预警。
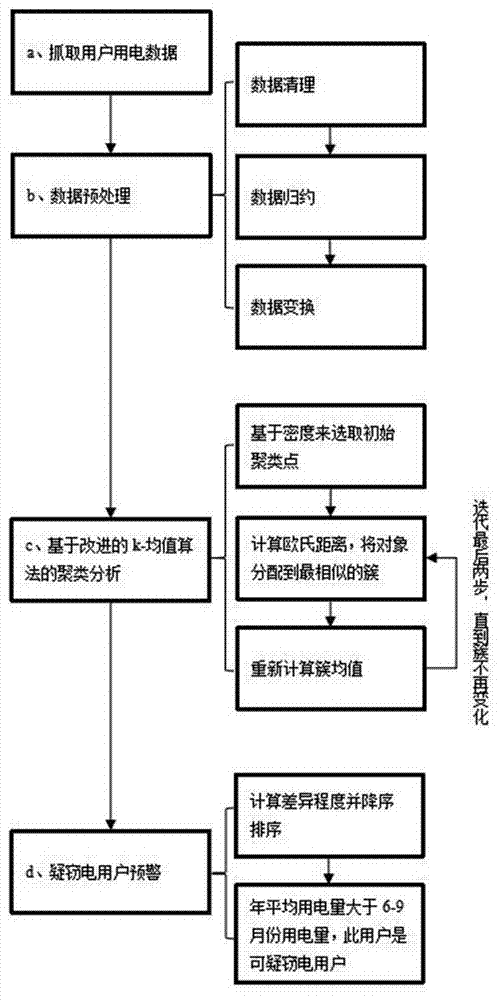
本发明采用以下方案实现:一种基于聚类离散点检测的反窃电方法,包括以下步骤:
步骤s1:进行原始数据获取,获取电力系统里用户用电数据,用以得到基于密度的k-均值算法所需的检测数据集;
步骤s2:进行数据预处理,对用户用电数据进行数据清理、数据归约和数据变换;
步骤s3:进行基于密度的k-均值算法的聚类分析,首先,采用基于密度选取初始聚类点的k-均值算法对用户用电数据进行学习和挖掘,计算出各数据对象所在区域的数据密度,选取其中k个大密度的簇,将数据集中的数据对象分别分配到离其最近的k个大密度簇中,这k个密度区域的中心就是初始聚类中心,然后应用经典的k-均值算法得到聚类结果;
步骤s4:根据所述步骤s3产生的聚类结果,按差异程度降序排序,找出差异程度高的数值,即离散点,并将其作为疑窃电用户点,自动在系统中推送警告信息,实现对疑窃电用户预警作用。
进一步地,步骤s2具体包括如下步骤:
步骤s21:对用户用电数据进行数据清理:用户用电数据中电表资产号、示数类型、用电地址、接线方式不相关的属性剔除掉,只留下用户编号和用电量;
步骤s22:进行数据归约,构造一个子属性年平均用电量;
步骤s23:进行数据变换:对所述数据变换进行定义,mina和maxa分别是属性a的最小值和最大值,通过最小-最大规范化公式:
将a的值vi映射到区间[new_mina,new_maxa]中的vi',其中可取new_mina=0.000,new_maxa=1.000,其中,new_mina表示a可取值的最小范围,new_maxa表示a可取值的最大范围,此规范化能够保持原数据之间的联系。
进一步地,步骤s3具体包括如下步骤:
步骤s31:基于密度来选取初始聚类点,计算步骤s2处理过后的数据集d中每个对象x的点密度dens(x)和均值点密度adens(x),点密度dens(x)是以x为球心,r为半径的球形域中包含的对象个数,即dens(x)={x|dist(x,o)≤r,x∈d},其中r=c×l,c是常数,o表示簇中的的对象,l表示数据集d中每两个对象之间的均值,一般取数据集d总个数n的1%-2%,
步骤s32:对于数据集d中的每个对象,计算每个对象与k个大密度簇中各个簇中心的欧氏距离,将每个对象分配到最相似的簇中;
步骤s33:重新计算k个大密度簇的均值;
步骤s34:重复步骤s32和步骤s33,继续迭代,直到分配稳定或所有的ci的变化小于给定阈值,即本轮形成的簇与前一轮形成的簇相同。
进一步地,步骤s31具体包括以下步骤:
步骤s311:计算步骤s2处理过后的数据集d中每个对象x的点密度dens(x)和均值点密度adens(x),将dens(xi)>adens(xi)的对象xi即核心对象存入集合s中,并记录其簇中所包含的其它所有对象;
步骤s312:合并所有具有公共核心对象的簇;
步骤s313:选取其中k个大密度的簇,簇之间满足ci∩cj=φ,其中,ci表示第i个簇,cj第j个簇,计算各个簇的簇密度cdens(ci),簇密度cdens(ci)是数据集d被划分出的大密度簇中所包含的对象个数m占总个数n的比值,即
进一步地,在步骤s313中所述中心点的选取计算方法为:选取离球心距离最近的对象作为初始聚类中心点,即
进一步地,在述步骤s4中,具体包括如下步骤:
步骤s41:计算聚类结果的差异程度diff(x,x'i),
步骤s42:对离散点做进一步下钻操作,把各自用电量平均值与6-9月份每个月用电量相比较,如果全年用电量平均值大于6-9月份每个月的用电量,说明此用户有非常大概率窃电。
较佳的,为了减轻人工审核负担、提高工作效率,并最终挽回企业和国家的损失,本发明从计算机角度看待用户用电数据,在用户用电数据中挖掘出可疑窃电用户,通过采用基于密度的k-均值算法来挖掘出可疑窃电用户,该方法能够对用户用电数据进行聚类分析,并得到可疑窃电用户,并能对管理员推送预警,使之能够精确地筛选出有嫌疑的窃电用户,缩小了排查范围,节省了企业在反窃电方面的投入。
与现有技术相比,本发明有以下有益效果:
1.本发明能够减轻人工审核负担、提高工作效率,并最终挽回企业和国家的损失。
2.本发明使用了大数据技术,能较好地应用电力企业的海量数据并契合国家大数据战略。
3.本发明能够对管理员推送预警,使之能够精确地筛选出有嫌疑的窃电用户,缩小了排查范围,节省了企业在反窃电方面的投入。
附图说明
图1为本发明实施例的流程图。
图2为本发明实施例的基于密度的k-均值算法示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1和图2所示,本实施例提供了一种基于聚类离散点检测的反窃电方法,具体包括以下步骤:
步骤s1:进行原始数据获取,获取电力系统里用户用电数据,用以得到基于密度的k-均值算法所需的检测数据集;
步骤s2:进行数据预处理,对用户用电数据进行数据清理、数据归约和数据变换;
步骤s3:进行基于密度的k-均值算法的聚类分析,首先,采用基于密度选取初始聚类点的k-均值算法对用户用电数据进行学习和挖掘,计算出各数据对象所在区域的数据密度,选取其中k个大密度的簇,将数据集中的数据对象分别分配到离其最近的k个大密度簇中,这k个密度区域的中心就是初始聚类中心,然后应用经典的k-均值算法得到聚类结果;
步骤s4:根据所述步骤s3产生的聚类结果,按差异程度降序排序,找出差异程度高的数值,即离散点,并将其作为疑窃电用户点,自动在系统中推送警告信息,实现对疑窃电用户预警作用。
在本实施例中,步骤s2具体包括如下步骤:
步骤s21:对用户用电数据进行数据清理:用户用电数据中电表资产号、示数类型、用电地址、接线方式不相关的属性剔除掉,只留下用户编号和用电量;
步骤s22:进行数据归约,构造一个子属性年平均用电量;
步骤s23:进行数据变换:对所述数据变换进行定义,mina和maxa分别是属性a的最小值最大值,通过最小-最大规范化公式:
将a的值vi映射到区间[new_mina,new_maxa]中的v'i,其中可取new_mina=0.000,new_maxa=1.000,其中,new_mina表示a可取值的最小范围,new_maxa表示a可取值的最大范围,此规范化能够保持原数据之间的联系。
在本实施例中,步骤s3具体包括如下步骤:
步骤s31:基于密度来选取初始聚类点,计算步骤s2处理过后的数据集d中每个对象x的点密度dens(x)和均值点密度adens(x),点密度dens(x)是以x为球心,r为半径的球形域中包含的对象个数,即dens(x)={x|dist(x,o)≤r,x∈d},其中r=c×l,c是常数,l表示数据集d中每两个对象之间距离的均值,一般取数据集d总个数n的1%-2%,o表示簇中的的对象,l是数据集d中每两个对象之间距离的均值,
步骤s32:对于数据集d中的每个对象,计算每个对象与k个大密度簇中各个簇中心的欧氏距离,将每个对象分配到最相似的簇中;
步骤s33:重新计算k个大密度簇的均值;
步骤s34:重复步骤s32和步骤s33,继续迭代,直到分配稳定或所有的ci的变化小于给定阈值,即本轮形成的簇与前一轮形成的簇相同。
在本实施例中,步骤s31具体包括以下步骤:
步骤s311:计算步骤s2处理过后的数据集d中每个对象x的点密度dens(x)和均值点密度adens(x),将dens(xi)>adens(xi)的对象xi即核心对象存入集合s中,并记录其簇中所包含的其它所有对象;
步骤s312:合并所有具有公共核心对象的簇;
步骤s313:选取其中k个大密度的簇,簇之间满足ci∩cj=φ,其中,ci表示第i个簇,cj表示第j个簇,计算各个簇的簇密度cdens(ci),簇密度cdens(ci)是数据集d被划分出的大密度簇中所包含的对象个数m占总个数n的比值,即
在本实施例中,在步骤s313中所述中心点的选取计算方法为:选取离球心距离最近的对象作为初始聚类中心点,即
在本实施例中,在步骤s4中,具体包括如下步骤:
步骤s41:计算聚类结果的差异程度diff(x,x'i),
步骤s42:对离散点做进一步下钻操作,把各自用电量平均值与6-9月份每个月用电量相比较,如果全年用电量平均值大于6-9月份每个月的用电量,说明此用户有非常大概率窃电。
较佳的,为了减轻人工审核负担、提高工作效率,并最终挽回企业和国家的损失,本实施例从计算机角度看待用户用电数据,在用户用电数据中挖掘出可疑窃电用户,通过采用基于密度的k-均值算法来挖掘出可疑窃电用户,该方法能够对用户用电数据进行聚类分析,并得到可疑窃电用户,并能对管理员推送预警,使之能够精确地筛选出有嫌疑的窃电用户。
特别的,实施例对通过对抓取用户用电数据并对其进行数据预处理,并采用改进的k-均值算法作为核心聚类算法,并对此算法的一些步骤进行相应的优化,使之能够更有效率地、更精确地处理用户数据,缩小了窃电排查范围,节省了公司在窃电方面的投入。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!