一种基于YOLOv3深度学习网络的图像智能标注方法与流程
本发明涉及图像智能标注和检索技术领域,具体涉及一种基于yolov3深度学习网络的图像智能标注方法。
背景技术:
近年来,人工智能和大数据成为了国内外各大领域关注的焦点。面对越来越多的图像数据,如何高效率的管理和组织这些图像数据,成为了图像检索领域研究的热点问题。而通过给图像添加与其内容相关的文本信息,即图像标注成为目前最主要的解决方法,鉴于人工标注存在着标注工作量大、主观性强等问题,智能图像标注在人工智能的浪潮下吸引了广大研究者们的青睐。
目前基于计算机视觉技术对图像自动标注已经取得了较好的效果,包括通过人工设计目标特征的方法和自动学习目标特征的深度学习方法。例如,中国专利(cn107644235a)公开了一种基于半监督学习的图像自动标注方法,通过提取图像数据的sift特征和hog特征训练的lda_svm分类器,结合通过颜色和纹理特征构建的神经网络分类器对图像数据进行自动标注。中国专利(cn104572940a)公开了一种基于深度学习与典型相关分析的图像自动标注方法,通过深度玻尔兹曼机模型提取图像数据的高层特征,并通过典型相关性分析等方法筛选出图像数据最佳的标注词汇。上述方法提出了一种通过图像数据的浅层特征和玻尔兹曼模型的高层特征自动标注图像的方法,但是浅层的图像特征训练的分类器仅对部分目标标注有效,而对其它目标无法得到较高的标注精度,而玻尔兹曼模型的训练需要利用大量的训练样本得到浅层的视觉特征,由于不同视觉目标的特征描述不同,往往需要具有针对性的选择较好的视觉特征描述,导致该方法的可移植性差。
技术实现要素:
针对现有图像数据智能标注方法的不足,本发明提出一种基于yolov3深度学习网络的图像智能标注方法,通过基于yolov3的深度卷积神经网络对图像数据独特的表征能力,先对一小部分人工标注的样本进行训练得到yolov3模型,再通过其权重模型自动标注一部分未标注的图片数据加入到yolov3的训练集中继续训练yolov3网络,经过数次重复上述训练和自动标注图片数据的过程,最终完成绝大部分图片数据的智能标注,同时也获得了对应整个图片数据集的yolov3强化模型,整个过程不需要利用人工设计图像目标的特征表示方法,yolov3模型将会不断的从训练数据集中学习所要标注目标的特征表达方法,不仅很大程度上降低了人工标注图像数据的复杂工作量,也具有更好的可移植性,有利于分析更多不同类型的图像目标。
本发明所采用的具体技术方案如下:
一种基于yolov3深度学习网络的图像智能标注方法,利用少量人工标注的图像训练基于yolov3的深度学习网络,并将yolov3模型的网络权重用于标注大量非人工标注的图像数据,通过数次的图像数据标注和训练过程,完成图像识别项目数据集的智能标注,同时得到与此图像识别项目对应的强化模型。
进一步,所述少量人工标注的图像训练基于yolov3的深度学习网络的具体过程为:
建立图像识别项目所要标注的图片数据集,从中随机筛选出每类相同数目的图片组成一组,将整个数据集不重复的切分成m组,并选择其中一组数据进行人工标注,将该组图片数据用于训练yolov3深度学习网络,得到yolov3模型。
进一步,所述数次的图像数据标注和训练过程包括m-1次的标注和m次的训练过程,具体为:
①利用训练好的yolov3模型自动标注下一组图片;
②人工修正①的标注结果,并将修正后的图片集加入到yolov3网络的训练集中训练,重复①的训练过程,训练完成后重复②;
③判断所有组的图片数据集是否都已经完成标注,没有完成则重复①、②,否则将所有组的图片数据加到yolov3网络的训练集中训练得到整个数据集的更新模型。
进一步,所述少量人工标注的图像指的是m组图片数据集中的任意一组图像数据,大量非人工标注的图像数据指的是除人工标注外的其余m-1组图像数据。
进一步,所述强化模型指的是:所有组图片数据加到yolov3网络的训练集中训练得到整个数据集的更新模型。
进一步,所述图像识别项目所要标注的图片数据集仅包括训练yolov3网络的图片数据,不包括测试集和验证集。
进一步,所述图片数据集包括相机采集的图片、网上下载的公共图片和经过图像处理技术扩充的图片。
进一步,所述人工修正方法包括增加、删减和调整识别目标包围框的位置和类别。
本发明的有益效果是:
1、降低人工标注图像数据的复杂工作量和主观能动性,人工标注图像数据需要利用标注工具标注出图像中目标的位置和类别,对于多目标有遮挡干扰的图片而言,人工标注是极其困难的,标注的结果也往往因人而异,本发明利用yolov3深度学习网络只需要很少人工标注的图像数据。
2、提高了图像智能标注的可移植性,本发明利用yolov3深度学习网络完成端到端的图像数据训练学习,具有更好的可移植性,而无需关心标注的图像目标是什么类型并对其提出何种具体的特征描述方法。
3、图像标注和图像目标检测识别同步进行,不仅能对图片数据完成智能标注,也在智能标注的过程中不断提升了yolov3模型检测和识别目标的性能。
附图说明
图1为本发明基于yolov3深度学习网络的图像智能标注方法工作的流程示意图;
图2为本发明利用基于yolov3网络训练2组图片数据更新的模型进行图像智能标注的应用实施例实物图,图2(a)为利用基于yolov3网络训练2组图片数据更新的模型进行图像智能标注的应用实施例一的实物图,图2(b)为利用基于yolov3网络训练2组图片数据更新的模型进行图像智能标注的应用实施例二的实物图;
图3为本发明利用基于yolov3网络训练6组图片数据更新的模型进行图像智能标注的应用实施例实物图,图3(a)为利用基于yolov3网络训练6组图片数据更新的模型进行图像智能标注的应用实施例一的实物图,图3(b)为利用基于yolov3网络训练6组图片数据更新的模型进行图像智能标注的应用实施例二的实物图。
具体实施方式
下面结合附图和具体实施方式对本发明作详细的说明。
在下面的描述中,阐述了许多具体细节以便使所属技术领域的技术人员更全面地了解本发明。但是,对于所属技术领域内的技术人员明显的是,本发明的实现可不具有这些具体细节中的一些。此外,应当理解的是,本发明并不限于所介绍的特定实施例。相反,可以考虑用下面的特征和要素的任意组合来实施本发明,而无论它们是否涉及不同的实施例。因此,下面的方面、特征、实施例和优点仅作说明之用而不应被看作是权利要求的要素或限定,除非在权利要求中明确提出。
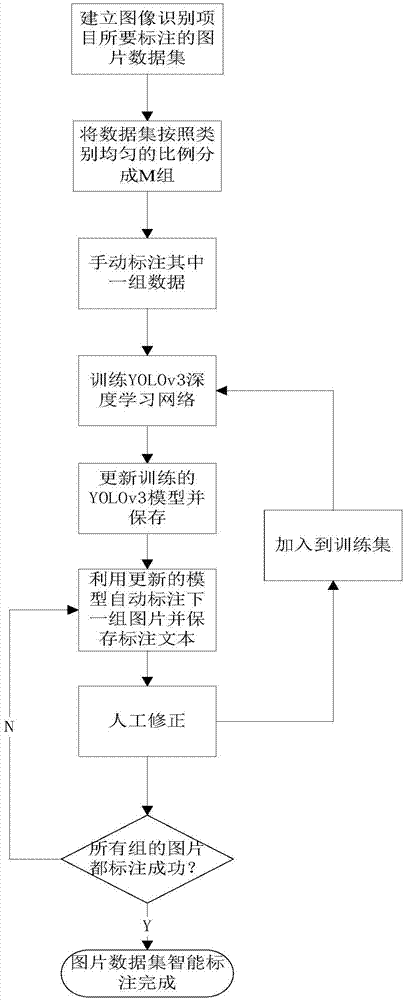
如图1所示,一种基于yolov3深度学习网络的图像智能标注方法,包括步骤:
步骤一,建立图像识别项目所要标注的图片数据集,从中随机筛选出每类相同数目的图片组成一组,将整个数据集不重复的切分成m组,并选择其中一组数据进行人工标注;
基于yolov3深度学习网络需要建立所需识别图片目标的数据集,此处指的是训练集,用于该模型的训练,不包括评价模型性能的测试集和验证集;图片数据集包括相机采集的图片、网上下载的公共图片和经过图像处理技术扩充的图片,从中随机筛选出每类相同数目的图片组成一组,并将整个数据集不重复的切分成m组,对于单目标图片,即每张图片仅包含一个目标,应该保证每类目标包含相同数目的不重复图片;对于多目标图片,同理只要每类目标包含的图片数目相同即可,对每张图片内的目标数目没有具体要求。对其中一组数据进行人工标注,本实施例共采得8类目标的图像数据集,其中每类20000张,总共160000张图片,并将其分成20组,对其中一组8000张图片人工标注,工作量仅为5%。
步骤二,将步骤一标注的其中一组图片数据用于训练yolov3深度学习网络,得到yolov3模型;
将步骤一标注好的一组数据加到yolov3深度学习网络(redmonj,farhadia.yolov3:anincrementalimprovement[j].2018.)中训练,本实施例中以darknet框架对第一组8000张图片数据,利用yolov3在coco数据集上的预训练模型权重初始化yolov3网络,采用小批量随机梯度下降算法,并设置初始化学习率为0.001,训练30000次。
步骤三,利用步骤二训练好的yolov3模型自动标注下一组图片;
步骤二训练完成后,得到训练好的yolov3模型权重数据,并将这些对应yolov3网络的权重数据保存在一个文件中,这样便可以利用保存的yolov3网络的权重数据再一次初始化yolov3网络进行测试,同时自动标注下一组图片,并保存相应的标注文本。本实施例中将yolov3模型权重数据保存在以weights为后缀名的文件中,同时将图片自动标注的文本以txt为后缀名的文件保存。
步骤四,人工修正步骤三的标注结果,并将修正后的图片集加入到yolov3深度学习网络的训练集中训练,重复步骤二的训练过程,训练完成后重复步骤三;
人工修正方法包括增加、删减和调整识别目标包围框的位置和类别,并将修正后的该组数据加入到yolov3深度学习网络的训练集中,重复步骤二的训练过程,训练完成后重复步骤三;本实施例中的图像数据标注和训练过程包括19次的智能标注和20次的训练过程。
步骤五,判断是否所有组的图片数据集都已经完成标注,没有则重复步骤三、四,否则表示图片数据集智能标注完成,并将所有组的图片数据加到yolov3深度学习网络的训练集中训练得到整个数据集的更新模型。
判断是否所有的图片数据都已经完成标注,若没有完成,则重复步骤三、四,否则表示图片数据集智能标注完成,并通过步骤三、四的死循环获得与整个图像数据集对应的yolov3深度学习网络的更新模型,更新模型是指每次训练yolov3网络,都会得到一个更新的yolov3网络的权重数据,与整个图像数据集对应的yolov3深度学习网络的更新模型又称为强化模型。本实施例中的19次的智能标注完成后,最后一次训练是将第20组图片数据加入到yolov3训练集中进行第20次训练,得到与整个图像数据集对应的更新模型结束。
以下通过一个应用实例来进一步说明本发明训练yolov3深度学习网络智能标注图像的应用场景。
实例:标注包含各种类型车辆及行人的图像数据
基于yolov3深度学习网络,结合本发明提出的图像智能标注方法,图2(a)、(b)为yolov3深度学习网络训练2组图片数据更新的模型进行图像智能标注的应用实施例实物图,图中数字对应着类别序号,如数字2对应目标类别“car”,数字7对应目标类别“truck”;图3(a)、(b)为yolov3深度学习网络训练6组图片数据更新的模型进行图像智能标注的应用实施例实物图,同理图中数字对应着类别序号,如数字2对应目标类别“car”,数字7对应目标类别“truck”。对比图2和图3可发现,随着训练数据的增加,更新的yolov3模型自动标注图片数据的准确性也在提高。
虽然本发明以较佳实施例披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内所作的各种更动与修改,均应纳入本发明的保护范围内,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!