用于确定图像中的子图块的类别的卷积神经网络模型的建模方法与流程
本发明涉及一种用于确定图像中的子图块的类别的卷积神经网络模型的建模方法。
背景技术:
舌诊作为中医的特色诊法,具有相对完整的理论依据,通过表象揭示了人体生理病理的客观现象,并被人们广泛接受与认可。舌诊作为中医行之有效的一种特色诊断方法,在今天的临床实践中依然发挥着重要作用。到目前为止,舌诊依然是证候诊断指向明确、容易上手且行之有效的诊断方法之一,对疾病的认识、用药的指导、疗效的评价都发挥着重要作用。随着计算机技术的发展,人们开始利用深度学习,机器视觉等方法结合中医专家丰富的临床经验推动舌诊客观化、标准化等相关研究。其中舌像的定位与分割是上述研究过程中的重要步骤之一,准确的分割有助于后续的特征分析及分类识别。定位与分割的精确性将对后续的特征分析等研究产生重大影响。
技术实现要素:
本发明针对开放式采集环境,并面对不同的图像分辨率、图像质量、光源色温、光照强弱、拍摄角度、背景环境等复杂因素,提供了一种具有快速,高效、鲁棒性强与自适应性强的舌体定位与分割方法。该方法设计了一个有效的卷积神经网路结构,能够对图像分割得到的子图块属于舌体区域或背景区域的两种类别进行预测,并进一步根据子图快的类别实现舌体在原始图像中的快速定位,以及利用水平集方法精准的对舌轮廓进行分割。
现有技术中针对开放式背景的中医舌象识别与分割的方案较少,且现有技术中的常用的图像分割方法在用于如核磁共振成像图片这种区域明显、颜色单一的简单连通区域时分割效果出色,而在背景复杂的中医舌象图像上的应用效果十分不理想,无法准确识别舌体区域并将舌头准确分割开来。
现有技术中的舌象分割方案主要可分为两大类:1.对图像进行前期的处理,对处理后的图片利用图像分割方法进行分割;2.利用神经网络等人工智能方法对舌象进行识别分割。具体实例如下。
1.cn107194937a(申请人:厦门大学,发明人:黄晓阳),采用了大量的图像处理方法进行组合判断,包括最大类间方差、色调阈值分割、rgb三色分量方差分割,并结合连通域凸包的空间位置、颜色、形状、轮廓信息,采用随机森林的预测方法。经过一系列的处理之后,采用snake分割法,对图像进行分割,得到舌头位置。
2.cni07316307a(申请人:北京工业大学,发明人:卓力)设计了一种卷积神经网络结构,利用采集到的样本数据对该网络的训练,得到网络模型,采用该模型可以对中医舌图像进行自动分割。该方法构建训练数据十分复杂,构建的神经网络计算量特别大。图像尺寸为512*512像素,并对5000张训练图片的每个像素进行人工标签,共计13亿个像素点进行标签。同时其构建的编码网络包含15个卷积层,特征图个数分别为32,64,128,256,512个,并包含5个池化层。构建解码网络办函反池化层,卷积层,batchnormalization层和计划层,以及其他复杂结构。该网络需要计算的参数数以十亿记。
与这些专利相比,本发明的主要优势在于:
1.采用神经网络方法对图像进行预处理,具有较强的自适应与鲁棒性,不受传统图像处理的限制,比如不需要对阈值进行人工挑选,同时也解决了传统的图像处理方法在设定阈值之后面对在极端或不同环境下采集的图像,方法失效的问题。
2.设计了一个结构简单,计算量较小的神经网络结构。巧妙的解决现有的训练集需要对每一像素进行标注背景区域还是舌体区域的问题,将图像分割成小的子图块150*150*3像素,只标注这一小图块是否包含有效的舌头区域。将一个舌体轮廓分割问题转换为是否含有舌头的二分类问题。人工标注的量急剧下降,本发明的训练数据只包含5000个子图块。其次本发明的神经网络结构简单,仅包含3个卷积层,其卷积核(即cn107316307a中的特征图)个数为10,10,1个,2个池化层,2个全连接层包含300,100个神经元,输出层。计算参数在百万级别,训练后的模型,可以应用于包括智能手机的各种智能终端,即:即便是如智能手机的智能终端,就可以实现本发明的舌像定位方法,从而摆脱了硬件计算能力的限制,使得舌象定位/轮廓确定的实现范围,获得了极大的扩展。个人用户可以用个人的智能手机、ipad、平板等便携智能终端完成舌象的定位处理,而不再需要把舌象照片上传到一个服务器之类的数据处理中心,从而使得整个分布式舌象采集/处理/分析系统在设计上更加灵活,资源的利用率也得到了显著提升。
根据本发明的一个方面,提供了一种舌像定位方法,其特征在于包括:
a)对输入的舌象图片中的舌体区域进行定位,包括:
a1)对于舌象图片,利用经过训练的卷积神经网络对分割所述舌象图片所得到的子图块进行判别,将子图块分为包含舌体的子图块与不包含舌体的子图块两种类别,即得到各子图块对应类别的预测值,
a2)对这些子图块的类别进行逻辑判断,得到一个包含完整舌体的矩形图像,即实现舌体位置的快速定位,
b)采用基于水平集的处理对舌象图片进行图像分割。
根据本发明的一个进一步的方面,上述步骤a2)包括:
把子图块输入到训练完善的卷积神经网络中,得到子图块属于舌体区域的逻辑斯蒂回归值,
设所有子图块的逻辑斯蒂回归值构成矩阵r,利用公式(6)得到舌体的中心位置的子图块。
(xcentral,ycentral)=argmax(r[xi,yi]+r[xi-1,yi]+r[xi+1,yi]+r[xi,yi-1]+r[xi,yi+1])÷5(6)
其中,(xi,yi)为分割子图块集合中第i项的列数和行数,(xcentral,ycentral)为中心位置的子图块的位置坐标,
把得到的中心位置(xcentral,ycentral)向上下左右四个方向延拓,设定停止延拓的阈值,得到延拓停止的坐标(xtop,ytop)、(xbottom,ybottom)、(xleft,yleft)、(xright,yright),
根据延拓得到的坐标(xtop,ytop)、(xbottom,ybottom)、(xleft,yleft)、(xright,yright)所在的子图块即终止子图块的位置,结合该终止子图块由神经网络输出得到的逻辑斯蒂回归概率值,确定:
舌体区域s0的上边界的坐标值:
舌体区域s0的下边界的坐标值:
舌体区域s0的左边界的坐标值:
舌体区域s0的右边界的坐标值:
把舌体部分矩形区域s0左上角坐标和右下角坐标分别为:
(left,top),(right,bottom)(11)。
由此,所有包含在左上角至右下角坐标下的子图块全部被判定为舌体部分,而其他子图块则标记为背景部分。实现了对子图块类别的分类。
经逆变换得到在原始舌像图片中的舌体区域s的左上角和右下角坐标分别为:
(r×left,r×top)
(r×right,r×bottom)(12)。
实现了舌体位置的快速定位。
根据本发明的进一步的方面,上述采用基于水平集的处理对舌象图片进行图像分割的处理包括:
设存在表面φ,它与一个零平面相交,从而得到曲线c,将曲线c通过水平集得到的舌头轮廓,
令曲线c上的坐标点(x,y)属于一个随着时间演化的曲线,令x(t)为坐标点在时刻t的这样的位置,即在任意的时刻t,每一个点x(t)都是表面φ在高度为0的曲线上的点,即:
φ(x(t),t)=0(13)
进而从以下公式(14),(15),(16),推断出任意时刻的φt:
其中
表面φ与舌体图像信息相关,是随着由舌体图像派生得到的势来更新的,
把x(t)做为所确定的舌头轮廓,并使得x(t)与真实的舌轮廓的误差随着t的变化而减小,具体包括:
利用舌象图片的hsv空间结合rgb空间的信息来给出用于计算势能大小的矩阵i,其中r,g,b,h,分别代表图像的rgb空间的三个通道以及hsv空间的h通道,x,y表示矩阵i的横纵坐标值、xc,yc表示矩阵i的中心点坐标。
i(x,y)=1.3r(x,y)-6.7g(x,y)+6.4b(x,y)-h(xc,yc)(17)
对于矩形的、包含完整舌体的所述舌象图片,给定该舌象图片在t=0时刻的一个初始表面φ,用公式(18)的矩阵形式表示φ,
把包含舌体区域范围内的坐标点表示为公式(19)的集合u,
并令集合u={(x,y)|φ(x,y)>0}(19)
把得到的集合u的外边缘轮廓作为本次循环t确定的舌头边缘坐标值x(t),
以num1为集合u中的元素个数,num2为包含完整舌体的矩形图像的总像素点个数减去num1的数量,使表面φ及集合u按如下公式(20)至(26)循环迭代直至收敛,从而使得x(t)在该循环的过程中,与真实的舌头轮廓的误差越来越小:
φ(x,y):=φ(x,y)*g(25)
u={(x,y)|φ(x,y)>0}(26)
其中:
grade1和grade2分别是矩形的所述舌象图片在集合u之内和之外的平均势能大小,
f(x,y)为一个中间变量,
g是如公式(28)的5×5大小矩阵的高斯算子,引入g用于在一定程度上消除噪点,使结果更稳定,其中每次循环都利用高斯算子g作为卷积核,对矩阵φ进行卷积操作,
其中σ为标准差,
fn是如公式(27)表示的表面φ随着矩形图像派生得到的势,用于利用该势更新φ,并利用更新后的φ来更新集合u,从而得到了误差更小的x(t),
fn=α·f(x,y)(27),
当集合u不再发生变化时,停止迭代,把此时得到的集合u的外边缘即x(t)作为舌头的边缘的坐标。
根据本发明的又一个方面,提供了用于确定图像中的子图块的类别的卷积神经网络模型的建模方法,其特征在于包括:
构建卷积神经网络的步骤,和
训练卷积神经网络模型的步骤,
其中:
所述卷积神经网络包括:
输入层,输入层为对图像进行分割得到的尺寸大小为150*150*3的子图块,
第一、第二和第三卷积层,分别含有10、10、1个卷积核,所有卷积核的大小均为5*5,
第一池化层和第二池化层,分别位于第一卷积层和第二卷积层之后,并且为核大小为2*2的平均池化层,
全连接层,全连接层包括两层,分别具有300和100个神经元,
输出层,
构建卷积神经网络的步骤包括:
使卷积层中的神经元与卷积层的小矩形感受域中的像素相连,
使三个卷积层中的下一层卷积层中的每个神经元仅与位于上一层卷积层中的小矩形感受域相连接,从而使得卷积神经网络专注于上一个层级的低级特征,然后将这些低级特征组装成下一个层级的高级特征,
使池化层中的每个神经元都连接到前一层中有限数量的神经元的输出,连接的前一层神经元在空间结构上位于一个小矩形内,该小矩形是池化层的内核,把每一个2×2大小、跨度为2的内核中的平均值输入到下一层,
使第三卷积层经过延展变换与全连接层相连,
使全连接层与输出层相连,得到图像对于每个类别的softmax交叉熵,
对通过第一至第三卷积层得到的特征,经由全连接层的前向传播,得到子图块归属于每一类别的预测值的大小,并利用softmax回归确定出子图块属于每一类别的概率值,
训练卷积神经网络模型的步骤包括:
用交叉熵作为损失函数,如公式(1)所示,
其中loss是交叉熵的值,n为输入的样本子图块的数目,p为期望输出概率,即样本子图块归属于每一类的真实值,q为卷积神经网络通过前向传播计算得到的实际输出,即子图块归属于每一类的预测值。
利用损失函数确定所述预测值与预先给定的样本子图块归属于每一类的真实值之间的交叉熵,
按照公式(2),利用反向传播算法和随机梯度下降对卷积神经网络的参数进行训练与更新,
其中w表示卷积神经网络中的参数值,α为学习率,
使得采用卷积神经网络的样本子图块的类别的预测值与真实值之间的误差不断下降,经过多次的循环,得到训练完善的卷积神经网络。
根据本发明的一个进一步的方面,上述图像为舌头图片。
附图说明
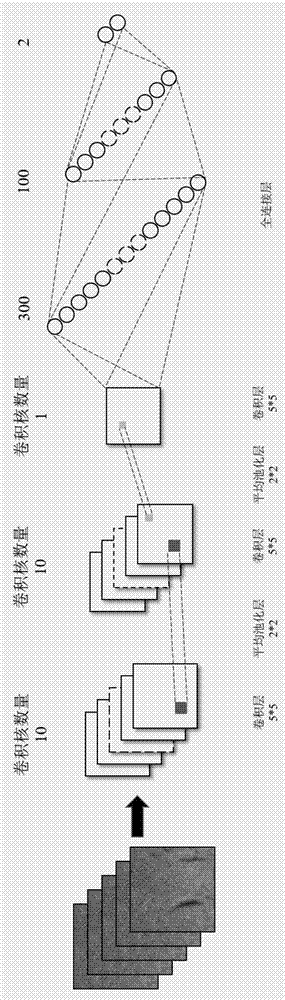
图1用于图像分类的卷积神经网络结构图;
图2(a)-图2(d)显示了根据本发明的一个实施例的过程示意图;其中图2(a)为采集得到的原图像,图2(b)为原图像经过缩放和分割得到的子图集合,图2(c)利用卷积神经网络对子图块的分类结果,并经过延拓得到的覆盖区域,图2(d)显示了经由逻辑判断得到的包含完整舌体的矩形区域。
图3是用于说明根据本发明的一个实施例的用于对子图块进行分类的卷积神经网络建模的流程图。
图4是根据本发明的一个实施例的子图块分类与舌像定位的流程图。
具体实施方式
本发明人在研究中发现,尽管舌像分割方面的研究取得了一定的进展,但是现有的方法往往是针对单一环境即封闭式的采集环境下进行分割的,普适性差、容易受图像质量、光源色温、光照强弱、拍摄角度、背景环境等影响,对于开放式采集环境下的舌像分割效果十分不理想,而且还存在着所需计算量太大的问题。为了克服现有方法鲁棒性不强、无法广泛使用等缺点,本发明人提出了一种针对开放式采集环境的新的舌像分割方法,该方法具有好的鲁棒性与自适应性,受外部采集环境、图像质量等方面的影响小,而且所需要的计算量相对于现有技术方案得到了显著降低。
卷积神经网络(cnn)是参考了大脑视觉皮层工作原理的一种神经网络结构,自20世纪80年代以来它们一直用于图像识别。近年来,由于计算能力,可用训练数据的数量以及深度网络训练的技巧的提升,使得cnn能够为图像搜索服务,自动驾驶汽车,自动视频分类系统等提供支持,并在这些复杂的视觉任务中有着惊人的表现。cnn对图像缩放、平移和旋转具有不变性,在图像识别和分类等领域已被证明非常有效,因此,借助cnn有助于对不同采集环境下的舌像进行快速定位。水平集(levelset)方法是1988年由osher等人首次提出,借鉴一些流体中的重要思想,有效地解决了闭合曲线随时间发生形变中几何拓扑变化的问题,并且避免了跟踪闭合曲线演化过程,将曲线演化转换成一个纯粹的偏微分方程(pde)求解的问题,使得计算稳定,可用于任意维数空间。用水平集来解决图像分割问题,就是将其与活动轮廓模型相结合,用水平集方法来求解这些模型得到的pde,属于边缘检测的分割方法。
根据本发明的一个实施例,首先为了实现快速自动定位,将图像进行缩放,减少图像的冗余信息,并对处理过的图像进行分割操作;采用了一种卷积神经网络对分割得到的子图块集合进行分类,通过对分类结果进行逻辑判断,实现舌体的快速定位;进而,利用水平集方法,对定位得到的舌像矩形区域进行轮廓分割。根据本发明的一个实施例的舌体定位与分割方法包括:
首先构建卷积神经网络结构,并训练该网络,得到训练完善的卷积神经网络。
输入开放环境下的原始图片,并进行放缩变换与分割操作,
。对上一步骤中分割的子图块集合利用训练得到的卷积神经网络进行分类,
对上述步骤得到的分类结果进行自动筛选,获得包含完整舌体的矩形区域子图块,实现了快速定位的功能,
对得到的包含舌体的矩形区域子图,利用水平集处理对舌体轮廓进行分割,
完成边缘分割功能并得到完整舌体。
与现有的中医舌像处理分割方法相比,本发明的优点和/或有益效果包括:
1.实现舌像的快速定位。经过图像预处理,减少数据量,使得计算量大幅缩减。通过卷积神经网络得到包含完整舌体的矩形区域子图。
2.实现舌轮廓的自动分割,避免了繁琐的人工选取过程。在定位分割的准度,速度与便捷性等方面具有明显的优势。
3.较强的适应能力、与较广的应用范围。应对不同的开放采集环境,光照强度、图像质量,本发明提出的方法都具有较高的准确率。
步骤s101:构建cnn模型的数据集。
使用不同手机的前置、后置摄像头以及专业的舌像采集设备等不同的图像采集设备在不同的环境下对不同人的舌像进行采集与分割处理,构成训练卷积神经网络所需要的数据集,共包含51000张像素大小为150*150的子图块集合。这些子图块集合包含了舌体区域与背景区域。
步骤s102:人工标注语义标签
对s101得到的子图块,人工加上了标注语义的标签,即对子图块属于舌体区域或背景区域进行注释。其中,如果子图块超过一半以上为舌体区域,则把该子图块标为舌体区域,反之则标为背景区域。如果原图片在拍摄时,镜头与舌体之间的拍摄距离过大,从而导致舌像面积窄小,这将影响进一步的特征分析与舌像应用。因此如果一张完整图像的所有子图块全部被标注为背景区域的话,即舌像在任意子图块中面积不超过1/2,则这张图像被判定为无效的。
步骤s103:构建并训练卷积神经网络模型。
本发明针对子图块的分类设计了一种深度卷积神经网络,并利用步骤s101创建的数据集与s102的标签对网络进行训练,最终得到可以用于对舌体和背景区域分类的网络模型。
首先对网络结构中的重要层级进行介绍。cnn结构中最重要的组成部分是卷积层,卷积层中的神经元不与输入图像中的每一个像素相连,而是与其感受域中的像素相连。进而,下一层卷积层中的每个神经元仅与位于上一层中的小矩形内的神经元即感受域相连接。这种架构允许神经网络专注于第一个隐藏层的低级特征,然后将它们组装成下一个隐藏层的高级特征。这种分层结构在现实世界的图像中很常见,这是cnn在图像识别方面效果良好的原因之一。
就像在卷积层一样,池化层中的每个神经元都连接到前一层中有限数量的神经元的输出,位于一个小的矩形感受域内。然而,汇集神经元没有权重;它所做的只是使用聚合函数来聚合输入。在本发明中,我们使用2×2大小的内核,跨度为2。将每个内核中的平均值输入到下一层。
本模型的整体结构设计如下:网络结构包含输入层,卷积层,池化层,以及全链接层和输出层。其中,输入层为分割得到的尺寸大小为150*150*3的彩色图像。网络共包含3个卷积层,分别含有10,10,1个卷积核,所有卷积核的大小均为5*5。池化层位于卷积1层和卷积2层之后,共两层池化层。并采用核大小为2*2的平均池化层。卷积3层经过延展变换与全连接层相连。全连接层共两层,神经元的数量分别为300和100个。全连接层与输出层相连,最终得到图像对于每个类别的softmax交叉熵。其中,本发明采用的激活函数为relu函数。图1表示了本发明设计的整体网络结构。
对通过三层卷积层得到的特征经由全连接层的前向传播得到图像归属于每一类预测值的大小,并利用计算值经过softmax回归给出属于每一类的概率值。我们利用交叉熵作为损失函数,如公式1所示,采用反向传播训练网络结构参数。
其中loss是交叉熵的值,n为输入样本数量,p为期望输出概率(属于为1或不属于为0),q为卷积神经网络通过前向传播计算得到的实际输出。
利用损失函数计算预测值与给定真实值之间的交叉熵,该交叉熵的大小反应的误差的大小。利用反向传播算法和随机梯度下降对卷积神经网络的参数进行训练与更新(公式2)。使得卷积神经网络的预测值与真实值之间的误差不断下降,最终得到训练完善的卷积神经网络。
其中w表示卷积神经网络中的参数值,α为学习率。
最终我们构建的卷积神经网络在测试集2000张图像(正负样本各1000张)上的分类准确率高达94.9%。
根据本发明的一个方面,提供了一种“用于确定图像中的子图的类别的卷积神经网络模型的建模方法”,包括(如图3所示):
构建卷积神经网络的步骤,和
训练卷积神经网络模型的步骤,
其中
所述卷积神经网络包括:
输入层,输入层为分割得到的尺寸大小为150*150*3的彩色图像,
第一、第二和第三卷积层,分别含有10、10、1个卷积核,所有卷积核的大小均为5*5,
第一池化层和第二池化层,分别位于第一卷积层和第二卷积层之后,并且为核大小为2*2的平均池化层,
全连接层,全连接层包括两层,分别具有300和100个神经元,
输出层,
构建卷积神经网络的步骤包括:
使卷积层中的神经元不与输入图像中的每一个像素相连,而是与卷积层的感受域中的像素相连,
使三个卷积层中的下一层卷积层中的每个神经元仅与位于上一层卷积层中的小矩形内的神经元即感受域相连接,这种架构允许神经网络专注于第一个隐藏层的低级特征,然后将它们组装成下一个隐藏层的高级特征,
使池化层中的每个神经元都连接到前一层中有限数量的神经元的输出,位于一个小矩形感受域内,把每一个2×2大小、跨度为2的内核中的平均值输入到下一层,
使第三卷积层经过延展变换与全连接层相连,
使全连接层与输出层相连,终得到图像对于每个类别的softmax交叉熵,其中,本发明采用的激活函数为relu函数,
对通过第一至第三卷积层得到的特征,经由全连接层的前向传播,得到子图块归属于每一类预测值的大小,并利用softmax回归给出子图块属于每一类别的概率值,
训练卷积神经网络模型的步骤包括:
用交叉熵作为损失函数,如公式(1)所示,
其中loss是交叉熵的值,n为输入样本数量,p为期望输出概率,q为卷积神经网络通过前向传播计算得到的实际输出,
利用损失函数计算预测值与给定真实值之间的交叉熵,
按照公式2,利用反向传播算法和随机梯度下降对卷积神经网络的参数进行训练与更新,
其中w表示卷积神经网络中的参数值,α为学习率,
使得采用卷积神经网络的子图类别的预测值与真实值之间的误差不断下降,经过多次的循环,最终得到训练完善的卷积神经网络。对此,一般是设定循环的次数,次数足够的话,就可以停止了。
最终我们构建的卷积神经网络在测试集2000张图像(正负样本各1000张)上的分类准确率高达94.9%。
图4是根据本发明的一个实施例的子图块分类与舌像定位的流程图,该方法包括:
步骤s201:图像预处理
由于图像拍摄的器材与采集环境的不同,导致图像的像素大小、分辨率等特征有所区别。首先对输入的图像进行预处理,针对不同分辨率的图片,缩放成具像素数量基本一致的图片。这样便于后续的子图分割与分类,舌体边缘检测等流程的标准化与规范化。由于对舌像位置与图像的分辨率大小不存在绝对关系,舌像位置坐标与分辨率之间的关系是成比例的。故我们可以通过放缩变换利用低分辨率图像进行定位,进而得到的边缘坐标利用逆变换还原得到真实图像下舌体边缘的坐标位置,同时减少数据量和运算量,使得计算速度得到明显提升。
在根据本发明的一个具体实施例中,以一般手机前置摄像头拍摄的相片为参考,采用1080000个像素为基本标准,将大于该标准质量(如后置摄像头,专业相机拍摄)的图片缩放至相同规模。并记录缩放比例,从而可以将后续计算的坐标位置通过逆变换进行还原。
对利用采集设备得到的原始舌像图片进行缩放,设原始舌像图片长、宽像素大小分别为l0和w0,使缩放后的图片长宽l1,w1为:
其中缩放比r为:
其中,缩放比r为小于等于1的情况即不进行缩放操作的情况
步骤s202:子图块分类与舌体区域定位
经由步骤s103,得到用于子图分类的卷积神经网络,并对步骤s201中输入图片分割得到的子图进行分类。以一张标准的手机前置拍摄图像为例,
在拍摄距离合适,拍摄图片有效的情况下,一张像素大小为1200*900的中医舌象图片(图2a)经过缩放、分割将得到48张150*150大小的子图块(图2b)。
把子图块输入到训练完善的卷积神经网络中,得到子图块属于舌体区域的逻辑斯蒂回归值,
设所有子图块的逻辑斯蒂回归值构成矩阵r,利用公式(6)得到舌体的中心位置的子图块。
(xcentral,ycentral)=argmax(r[xi,yi]+r[xi-1,yi]+r[xi+1,yi]+r[xi,yi-1]+r[xi,yi+1])÷5(6)
其中,(xi,yi)为分割子图块集合中第i项的列数和行数,(xcentral,ycentral)为中心位置的子图块的位置坐标,
把得到的中心位置(xcentral,ycentral)向上下左右四个方向延拓,设定停止延拓的阈值,得到延拓停止的坐标(xtop,ytop)、(xbottom,ybottom)、(xleft,yleft)、(xright,yright),
根据延拓得到的坐标(xtop,ytop)、(xbottom,ybottom)、(xleft,yleft)、(xright,yright)所在的子图块即终止子图块的位置(图2(c)),结合该终止子图块由神经网络输出得到的逻辑斯蒂回归概率值,确定:
舌体区域s0的上边界的坐标值:
舌体区域s0的下边界的坐标值:
舌体区域s0的左边界的坐标值:
舌体区域s0的右边界的坐标值:
把舌体部分矩形区域s0左上角坐标和右下角坐标分别为:
(left,top),(right,bottom)(11)。
由此,所有包含在左上角至右下角坐标下的子图块全部被判定为舌体部分,而其他子图块则标记为背景部分。
经逆变换得到在原始舌像图片中的舌体区域s的左上角和右下角坐标分别为:
(r×left,r×top)
(r×right,r×bottom)(12)。
利用训练完善的卷积神经网络对分割得到的子图块进行判别,将子图块分为包含舌体与不包含舌体不同的两种类别,即得到对应的子图标签。确定了子图块的类别,并最终得到一个合适的包含完整舌体的矩形框(图2d),实现了舌体位置的快速定位。
根据本发明的一个进一步的实施例,为满足进一步的舌像分析工作的需求,在进行了舌体位置的上述快速定位之后,采用基于水平集的处理对包含舌体的图像进行图像分割。水平集的核心思想为:假设存在表面φ,它与一个零平面相交,从而得到曲线c,那么曲线c就是我们通过水平集得到的轮廓。
令曲线c上的坐标点(x,y)属于一个随着时间演化的曲线,x(t)为坐标点在t时刻的位置。在任意时刻t,对于每一个点x(t)都是表面φ在高度为0的曲线上的点,即:
φ(x(t),t)=0(13)
进而我们根据公式(14),(15),(16),可以推断任意时刻的φt
对于具体的实施例而言,在舌体图像分割中,表面φ与舌体图像信息相关,是随着由舌体图像派生得到的势来更新的。x(t)为方法计算得到的舌头轮廓,并随着t的变化,x(t)与真实的舌轮廓误差减小。具体的计算方法如下:
首先利用舌体图像的hsv空间结合rgb空间的信息来给出用于计算势能大小的矩阵i,其中r,g,b,h,分别代表图像的rgb空间的三个通道以及hsv空间的h通道。x,y表示矩阵横纵坐标值、xc,yc表示矩阵中心点坐标。
i(x,y)=1.3r(x,y)-6.7g(x,y)+6.4b(x,y)-h(xc,yc)(17)
根据步骤s202得到的包含完整舌体的矩形图像,给定该图像在t=0时刻的初始表面φ,用矩阵形式表示(公式18),以及用来记录的包含舌体区域范围坐标点的集合u(公式19),计算得到的集合u的外边缘轮廓就是本次循环t时刻计算出来的舌边缘坐标值x(t),其中:
并令集合u={(x,y)|φ(x,y)>0}(19)
其中num1为集合u中的元素个数,num2为包含完整舌体的矩形图像的总像素点个数减去num1的数量。
表面φ以及集合u在运算过程中是循环迭代直至收敛的计算过程,使得x(t)在循环的过程中,与真实的舌轮廓的误差越来越小。循环迭代如下公式:
φ(x,y):=φ(x,y)*g(25)
u={(x,y)|φ(x,y)>0}(26)
上述公式中,grade1,2分别记录图像在集合u内,外的平均势能大小。f(x,y)为用于计算推导的一个中间变量,g(公式28)为5×5大小矩阵的高斯算子,引入g可以在一定程度上消除图像的噪点,使计算结果更稳定,每次循环都利用高斯算子作为卷积核,对矩阵φ进行卷积操作。fn(公式27)表示舌体图像表面φ随着图像派生得到的势,利用该值更新φ,并利用更新后的φ来更新集合u,即得到了误差更小的x(t)。
fn=α·f(x,y)(27)
当集合u不再发生变化时,停止迭代,此时得到的集合u的外边缘即最终时刻t对应的x(t)作为舌体的边缘坐标。
经过上述公式进行计算,最终对得到的包含舌体的矩形区域子图,利用水平集处理对舌体轮廓进行分割,完成边缘分割功能并得到完整舌体。
本发明提出了一种快速,新颖的舌像分割方法。首先对输入图片进行缩放并分割得到像素较小的子图集合,进而利用卷积神经网络对这些子图进行分类操作,有效地降低了计算量并减少了计算时间,实现了舌体位置的快速定位。进一步结合图像hsv通道与rgb通道的统计信息并采取水平集的方法,对上一步定位到的包含舌体的矩形区域进行精确的舌像分割操作。本发明的方法适用于包括开放式环境与封闭式环境的各种不同采集环境,具有适应能力强,应用范围广等特点。其中我们构建的卷积神经网络在测试集2000张图像(正负样本各1000张)上的分类准确率高达94.9%。同一般的舌像定位分割方法相比,本方法计算量更小,准确率提升明显,并避免了复杂的人工选取舌像轮廓的繁琐过程,实现了自动定位与分割功能。在定位分割的准确度,速度等方面具有明显的优势。
- 还没有人留言评论。精彩留言会获得点赞!