一种服务器硬件故障日志的采集方法与流程
本发明涉及服务器测试技术领域,更具体的说是涉及一种服务器硬件故障日志的采集方法。
背景技术:
当今,服务器系统的设计越来越复杂,一块服务器主板上元器件往往有数千之多,当主板出现硬件故障时,工程师往往需要大量的数据测量并进行详细的分析才能定位到故障位置,这将是一个非常复杂的工作。
服务器硬件故障信息主要包括:cpu故障、总线故障、内存ecc校验错、cache错误、tlb错误、内部时钟错误,bios配置错误、firmwarebug错误,上述故障信息一般保存在/dev/mcelog日志里。通常,工程师通过查看mcelog日志来进行服务器的硬件故障分析。
但是,由于mcelog日志内的故障信息是按照服务器故障的发生时间顺序进行记录的,mcelog日志内的故障信息数据庞大且无法进行分类。而工程师进行故障分析时,需要对故障进行分类排查,因此必须在分析前对故障数据进行分类,这样不仅耗时还耗费大量人力,还容易出现失误,严重影响了工程师的工作效率。
技术实现要素:
针对以上问题,本发明的目的在于提供一种服务器硬件故障日志的采集方法,能够收集服务器关键硬件的故障信息,并把每个错误分配到相应的日志里分别进行储存,实现了故障数据的分类存储,便于工程师的分类查看。
本发明为实现上述目的,通过以下技术方案实现:一种服务器硬件故障日志的采集方法,包括如下步骤:
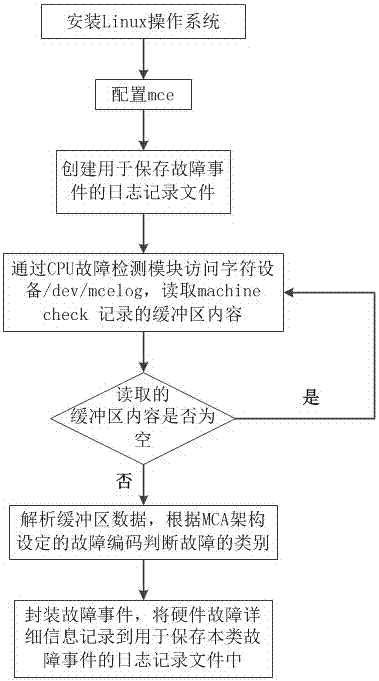
步骤1:安装linux操作系统;
步骤2:配置mce;
步骤3:创建用于保存故障事件的日志记录文件;
步骤4:通过cpu故障检测模块访问字符设备/dev/mcelog,读取machinecheck记录的缓冲区内容;
步骤5:判断读取的缓冲区内容是否为空,如果是,转到步骤4;如果否,转到步骤6;
步骤6:解析缓冲区数据,根据mca架构设定的故障编码判断故障的类别;
步骤7:封装故障事件,将硬件故障详细信息记录到用于保存本类故障事件的日志记录文件中。
进一步,所述步骤2具体为:在/boot/grub/grub.conf中加入mce=on。
进一步,所述步骤3具体包括:在用户目录下分别创建cache.log文件、tlb.log文件、bus.log文件和mem.log文件;所述cache.log文件为用于保存cache错误的日志记录文件;所述tlb.log文件为用于保存tlb错误的日志记录文件;所述bus.log文件为用于保存总线故障的日志记录文件;所述mem.log文件为用于保存内存故障的日志记录文件。
进一步,所述步骤6还包括:从缓冲区数据中得到mca架构信息的故障信息编码,通过所述故障信息编码的0到15位的值判断故障的类别。
进一步,通过所述故障信息编码的0到15位的值判断故障的类别,包括:
如果所述故障信息编码0到15位的格式为000f00000001ttll,则判定为tlb错误。
进一步,通过所述故障信息编码的0到15位的值判断故障的类别,还包括:如果所述故障信息编码0到15位的格式为000f0000000011ll或000f0001rrrrttll,则判定为cache错误。
进一步,通过所述故障信息编码的0到15位的值判断故障的类别,还包括:如果所述故障信息编码0到15位的格式为000f1pptrrrriill,则判定为总线故障。
进一步,通过所述故障信息编码的0到15位的值判断故障的类别,还包括:
如果所述故障信息编码0到15位的格式为000f00001mmmcccc,则判定为内存故障。
进一步,所述linux操作系统采用centos系列操作系统。
对比现有技术,本发明有益效果在于:本发明提出的一种服务器硬件故障日志的采集方法,自动对cache、tlb、总线、内存故障日志进行收集。其中,cpu故障包括,cache、tlb和总线。通过分析mca架构信息的故障信息编码0到15位故障码的值,检测出硬件故障类别,根据错误码将硬件故障详细信息记录到相应的cache.log文件,tlb.log文件、bus.log文件、mem.log中。本发明能够能把硬件故障信息解析出属于cpu和内存的硬件故障日志,并通过查看日志文件记录信息,随时了解服务器的硬件运行情况。工程师可以通过查询日志数据即可查得硬件错误日志,从而为采集硬件故障信息带来便利。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著的进步,其实施的有益效果也是显而易见的。
附图说明
附图1是本发明的方法流程图。
具体实施方式
下面结合附图对本发明的具体实施方式做出说明。
如图1所示的一种服务器硬件故障日志的采集方法,包括如下步骤。
步骤1:安装linux操作系统。
所述linux操作系统采用centos系列操作系统。
步骤2:配置mce。
在/boot/grub/grub.conf中加入以下内容:mce=on。默认是on。
步骤3:创建用于保存故障事件的日志记录文件。
具体为:在用户目录下分别创建cache.log文件、tlb.log文件、bus.log文件和mem.log文件。其中,cache.log文件为用于保存cache错误的日志记录文件;tlb.log文件为用于保存tlb错误的日志记录文件;bus.log文件为用于保存总线故障的日志记录文件;mem.log文件为用于保存内存故障的日志记录文件。
步骤4:通过cpu故障检测模块访问字符设备/dev/mcelog,读取machinecheck记录的缓冲区内容。
步骤5:判断读取的缓冲区内容是否为空,如果是,转到步骤4;如果否,转到步骤6。
步骤6:解析缓冲区数据,根据mca架构设定的故障编码判断故障的类别。
从缓冲区数据中得到mca架构信息的故障信息编码,通过故障信息编码的0到15位的值判断故障的类别。如果故障信息编码0到15位的格式为000f00000001ttll,则判定为tlb错误。如果故障信息编码0到15位的格式为000f0000000011ll或000f0001rrrrttll,则判定为cache错误。如果故障信息编码0到15位的格式为000f1pptrrrriill,则判定为总线故障。如果故障信息编码0到15位的格式为000f00001mmmcccc,则判定为内存故障。
步骤7:封装故障事件,将硬件故障详细信息记录到用于保存本类故障事件的日志记录文件中。即根据硬件故障信息的类别,将故障详细信息记录到相应的cache.log文件,tlb.log文件、bus.log文件、mem.log中。
本发明主要针对cache、tlb、bus、内存故障日志的收集。从缓冲区数据中,可以得到mca架构信息的故障信息编码,一般共计64位编码,由于可以从0到15位标记通用的cpu和内存日志,所以查询cache、tlb、bus、内存故障,只需要关注0到15位故障码的值。
下面对以上故障码进行分类,各种mca架构设定的故障编码参照如下:
tlb:000f00000001ttll
cache:000f0000000011ll和000f0001rrrrttll
bus:000f1pptrrrriill
mem:000f00001mmmcccc
tlb:000f00000001ttll,所代表的含义为:只要错误码是000f00000001ttll格式,都可以看做是tlb故障信息。
以下类同:
cache:000f0000000011ll和000f0001rrrrttll,只要错误码是000f0000000011ll和000f0001rrrrttll格式,都可以看做是cache故障信息。
bus:000f1pptrrrriill只要错误码是000f1pptrrrriill格式,都可以看做是bus故障信息。
mem:000f00001mmmcccc只要错误码是000f00001mmmcccc格式,都可以看做是内存故障信息。
关于错误码里可取值的说明如下:
f有0和1两个数据:
0代表“normal”标签
1代表”corrected”标签
tt有00和01和10三个数据分别代表三种事务类型:
00代表instruction事务类型
01代表data事务类型
10代表generic事务类型
ll有00、01、10、11四种,代表在内存层次结构中的位置:
00代表在level0上
01代表在level1上
10代表在level2上
11代表在generic上
rrrr,代表九种请求类别:
0000代表genericerror请求类别
0001代表genericread请求类别
0010代表genericwrite请求类别
0011代表dataread请求类别
0100代表datawrite请求类别
0101代表instructionfetch请求类别
0110代表prefetch请求类别
0111代表eviction请求类别
1000代表snoop请求类别
bus错误中的pp(participation)有00、01、10、11四种事务类型:
00代表localprocessor*originatedrequest
01代表localprocessor*respondedtorequest
10代表localprocessor*observederrorasthirdparty
11代表generic上
t(time-out)有0和1两种事物类型:
1代表requesttimedout,超时
0代表requestdidnottimeout,不超时
内存错误中的mmm有六类事务类型:
000代表genericundefinedrequest
001代表memoryreaderror
010代表memorywriteerror
011代表address/commanderror
100代表memoryscrubbingerror
101-111代表reserved
cccc有两类:
0000-1110代表channelnumber
1111代表channelnotspecified
待根据mca码检测出硬件故障类别后,即可详细根据错误码记录硬件故障详细信息到相应的cache.log文件,tlb.log文件、bus.log文件、mem.log中。
结合附图和具体实施例,对本发明作进一步说明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!