一种基于无监督特征点检测的商品对齐方法与流程
本发明涉及人工智能的技术领域,更具体地,涉及一种基于无监督特征点检测的商品对齐方法。
背景技术:
目前没有商品没有一个统一的对齐方法,大部分相关任务都是没有做对齐的,现有的对齐方法也都是有监督先标出特征点,但是人工标注的特征点对于不同的商品是不鲁棒的,而且人工标注的成本是很高的。因此如果能无监督自适应找到能对抗旋转的商品结构特征点,用在商品领域是很有意义的。
现有技术是:1、现有的商品特征点检测都是用带标注的数据预先训练好特征点检测模型,再对商品图片的特征点进行预测,对齐。2、大部分商品识别任务是没有对商品做对齐的。
现有技术的缺点是:1、训练需要大量带标注的图片数据,物体结构的人工标注或设计对于大多数对象类别来说这个成本是很大的。2、目前的商品识别任务由于标注成本高,商品结构复杂,是没有做对齐的,对于识别准确率有一定的影响。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于无监督特征点检测的商品对齐方法,在实际场景中我们是需要识别有旋转角度的商品的,但是由于标注这样的数据成本很高,就没有做对齐,目前都是通过增加训练集的数据,增加训练数据的多样性来保证识别正确率,然而有倾斜角度的商品识别准确率是远不如正向商品的识别准确率的。通过稳定的特征点对齐商品再进行识别就很有意义。能提高商品识别的准确率。
本发明的技术方案是:一种基于无监督特征点检测的商品对齐方法,其中,包括以下步骤:
s1.特征点检测训练数据准备;
s2.检测框模型训练;
s3.特征点检测;
s4.根据特征点坐标进行仿射变换对齐。
现有的一些商品有监督特征点检测特征点方法需要人工标注特征点的信息,成本很高,本方法可以用无监督的形式对商品的特征点进行建模;现有的一些商品识别系统对于商品是没有做对齐的,通过本方法做了对齐之后能提升识别准确率。
本发明保护一套基于图像检测的商品对齐技术,用无监督检测特征点的方法,对其他角度的商品数据做对齐,便于进行后续商品识别等操作。之前是用有监督人工标注特征点对齐或者没有做对齐技术。
与现有技术相比,有益效果是:本发明经过特征点检测对齐之后用在商品后续的识别网络上,相较于没做对齐直接识别准确率会明显更高,因为网络对于正向的物体比倾斜的物体更容易识别;对于现有的有监督特征点对齐,这个方法能节省标注成本。
附图说明
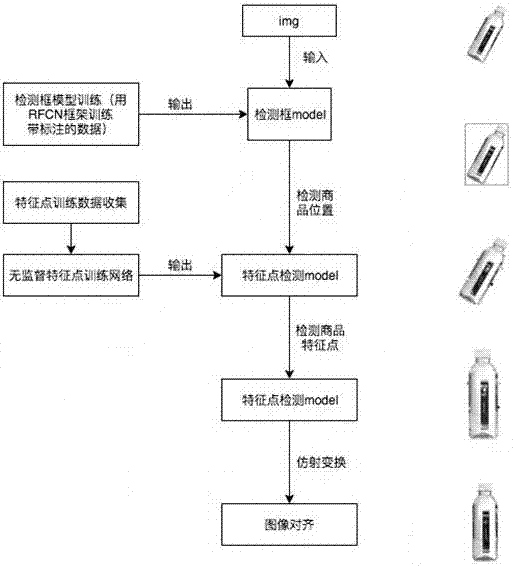
图1是本发明整体流程示意图。
图2是本发明r-fcn网络结构示意图。
图3是本发明特征点检测网络结构示意图。
图4是本发明模板关键点示意图。
图5是本发明仿射变换示意图。
图6是本发明对齐示意图。
图7是本发明特征点检测效果示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
如图1所示,一种基于无监督特征点检测的商品对齐方法,其中,包括以下步骤:
s1.特征点检测训练数据准备;
s2.检测框模型训练;
s3.特征点检测;
s4.根据特征点坐标进行仿射变换对齐。
所述的步骤s1中,
网络爬虫获取目标商品原始数据;在京东淘宝商品评论用户晒照里爬取图片;
数据清洗,对爬取的图片进行数据清洗,挑选数据质量高的图片;
数据增广,对获得的数据通过网络生成各个方向的图片数据,目的是为了让后面的检测网络学习到各个方向上商品的物理结构。
如图2所示,步骤s2中,
选用r-fcn检测框架来训练检测模型:检测模型训练数据是带标注的3000张商品数据,设置ancor参数,检测框大小参数an_scale=[2,4,8,16,32],检测框长宽比例an_ratio=[0.5,1,2],输入图像大小600x800,学习率0.001,使用nvidia1080t显卡训练,训练最大迭代次数30000次。
如图3所示,特征点获取的方法主要采用了一篇论文里的方法,论文发表在2018cvpr,它主要是用在对齐之后的人脸图像上。这是主体的网络架构,采用的是hourglass网络,左上角是进行特征点检测,为得到有效的特征点,提出了几个约束。
所述的步骤s3中,包括
s31.特征点编码:特征点检测器,每一个特征点都有其对应的特征点检测器;hourglass
获得原始检测分数图得到r:
s32.softmax归一化成概率:因为这个原始分数是无界的,用softmax归一化成概率,得到检测置信度图d,dk就是d的第k个channel,是weightmap,dk(u,v)是第k个channel中坐标为(u,v)的值;
s33.加权平均坐标作为第k个特征点的位置(xk,yk),这个公式可以实现梯度反传:可以实现从下游神经网络通过特征点坐标向后传播梯度;因为dk在实际中很少出现完全集中在单个像素中,或者完全均匀分布这种情况;
为了让得到的特征点有效,提出了几个软约束:
(1)第一个浓度约束:简而言之就是使landmark尽可能地突出出来。计算两个坐标轴上坐标的方差,设计如图示loss是为了使方差尽可能小。det.u是沿着x轴的方差,det.v是沿着y轴的方差。这个损失就是各向同性高斯分布(每个分量的方差相同)的熵的指数。更低的熵值意味着peak处更多的分布,也就是使landmark尽可能地突出出来。
(2)第二个分离约束:由于刚开始训练时候的输入的是randomdistribution,故可能导致加权的landmark的平均坐标聚集在中心周围,可能会导致separation效果不好,因此而落入localoptima,故设计了该loss。将不同channel间的坐标做差值,使得不同landmark尽可能不重叠,理想情况下,自动编码器训练目标可以自动检测得到k个特征点在不同局部区域分布,从而可以重建整个图像。
(3)第三个等变约束,就是某一个landmard在另一个image中变换坐标时应该仍能够很好地定位,应的视觉语义仍然存在于变换后的图像中。g(,)是一个坐标转换,将(xk,yk)映射到g(xk‘,yk’)最理想的就是二者相等。作者用随机参数的薄板样条函数(tps)来模拟g。我们使用随机平移,旋转和缩放来确定tps
如图4-7所示,所述的步骤s4中,将正向监测到的特征点作为模板的特征点坐标,利用其他角度检测到的特征点和模板的特征点,计算仿射矩阵h;然后利用h,直接计算得到对齐后的图像。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!