一种高考志愿优化方法、装置、终端和存储介质与流程
本发明涉及数据处理分析领域,具体涉及一种高考志愿优化方法、装置、终端和存储介质。
背景技术
由于近几年来,高考政策变化较大、志愿填报规则设置变动频繁、每年试题难度不统一等因素,各年份高考批次线差异较大。如果以近几年的高考总分为依据来推荐院校,所推荐院校会与当年实际录取情况出现较大差异,容易给考生造成一定误解,甚至给出错误的选择,严重影响考生志愿填报的准确性。
技术实现要素:
本发明解决的技术问题为优化高考志愿填报,提供一种高考志愿优化方法、装置、终端和存储介质。
为了解决上述技术问题,本发明提供的技术方案为:
一种高考志愿优化方法,包括:获取用户当前的省排名和分数;调用该省历年高考信息,获取往年在该省排名及大于该省排名分数段录取新生的高校的集合;根据获取的高校的集合,输出推荐的志愿。
获取用户的省排名和分数信息后,同该省的历年高考录取信息对比,参照历年的录取信息,获取考生用户的排名可被录取的院校。
参照历史信息推荐院校,准确率较高。
优选地,在获取用户的省排名和分数信息前,将当年考生划分为k个梯度,划分标准为将l个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k≤l;推荐的志愿为在该梯度内录取往届考生的高校中一部分或全部。在一个梯度内分析考生可填报的志愿,可以减轻系统的处理负荷,并提高准确率。
优选地,在调用该省历年高考信息后,将往年考生划分为k`个梯度,划分标准为将l`个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k`≤l`;所述的k`=k,所述的l`=l。将历届的考生同当前的考生同样的分类,方便进行相同梯度内的对比与分析。
优选地,建立人工鱼群寻优模型,所述的模型中的各种参数为:种群规模n为当年的考生人数;人工鱼可视域visual为步长的1~10倍;步长step根据用户的省排名进行变化,省排位的值越大,步长越长;拥挤因子为0.1~100;尝试次数try_number为1~1000;向量x(x1,x2,……xn),xi为欲寻优的变量。人工鱼群算法用于在获取的高校的集合内优选出录取概率高的高校,其中步长同考生的排名有关,根据一定的变化规律设置步长,以提高优选结果的准确性;人工鱼的可视域同步长有一定的关联,表明优选算法可以根据用户的省排名进行较为准确的优选。
优选地,所述的人工鱼群模型中各种参数为:种群规模n为划分的梯度内的学生人数;人工鱼可视域visual为步长的2倍;所述的步长step同省排位的关系为
优选地,获取高校的集合后,进行模拟投档,计算用户被集合内的每个高校录取的概率因子,所述的概率因子为历年的学校平均投档排位值同该考生排名的差值与平均投档排位值的比值。模拟投档即计算用户被录取的概率,利用平均的排位值以及考生的排位值进行计算,概率更为准确。
优选地,在优选出的高校的集合中进行分类,所述的分类的方法为:将高校分为冲刺类、稳妥类和保底类高校,所述的冲刺类高校不大于20所,所述的保底类高校不大于30所;获取阈值概率系数,所述的阈值概率系数为用户输入,或者所述的阈值概率系数为该类别高校平均的录取概率因子±差值阈值系数,所述的差值阈值系数为相应类别最后的高校录取的概率因子同该类别中所有高校的录取概率因子的平均数的差值;所述的冲刺类高校的阈值概率系数的较小值大于稳妥类高校的阈值概率系数的较大值,所述的稳妥类高校的阈值概率系数的较小值大于保底类高校的阈值概率系数的较大值。帮助用户对优选出的高校进行分类,可以提高用户对推荐结果有清晰的了解。
一种高考志愿优化装置,包括用户信息获取模块、历史信息调用模块、志愿推荐模块,所述的用户信息获取模块同历史信息调用模块连接,所述的历史信息获取模块同志愿推荐模块连接。
一种高考志愿优化终端,包括一个或多个处理器;以及存储装置,用于存储一个或多个程序;当所述一个或多个程序被所述的一个或多个处理器执行,使得所述的一个或多个处理器实现上述的高考志愿推荐方法。
一种高考志愿优化存储介质,所述的一个或多个程度可被一个或多个处理器执行,以实现上述的方法。
与现有技术相比,本发明具有的有益效果为:获取用户的省排名和分数信息后,同该省的历年高考录取信息对比,参照历年的录取信息,获取考生用户的排名可被录取的院校,参照历史信息推荐院校,准确率较高;本发明通过对海量的高校进行筛选,进行推荐,并对推荐的结果进行优化,选用的优化方法的效率高,结果准确。
附图说明
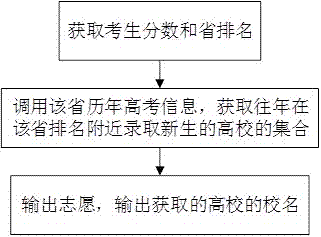
图1为一种高考志愿优化方法的流程示意图。
图2为一种高考志愿优化方法的另一种实施方式的流程示意图。
图3为一种高考志愿优化方法的另一种实施方式的流程示意图。
图4为一种高考志愿优化方法的另一种实施方式的流程示意图。
图5为一种高考志愿优化方法的另一种实施方式的流程示意图。
图6为一种高考志愿优化方法的另一种实施方式的流程示意图。
图7为一种高考志愿优化装置的连接示意图。
图8为一种高考志愿优化装置的另一种连接示意图。
图9为一种高考志愿优化装置的另一种连接示意图。
具体实施方式
以下实施列是对本发明的进一步说明,不是对本发明的限制。
实施例1
在本申请的一些实施例中,一种高考志愿优化方法,包括:获取用户当前的省排名和分数;调用该省历年高考信息,获取往年在该省排名及大于该省排名分数段录取新生的高校的集合;根据获取的高校的集合,输出推荐的志愿。
获取用户的省排名和分数信息后,同该省的历年高考录取信息对比,参照历年的录取信息,获取考生用户的排名可被录取的院校。
参照历史信息推荐院校,准确率较高。
如图1所示,获取考生的分数和省排名后,调用历年招生录取信息,获取在该省排名所在分数段录取考生的高校,向考生输出志愿,即输出获取的高校的校名。
在本申请的另一些实施例中,所述的获取省排名和分数信息后,进行合理性验证,所述的合理性验证为:调用当前年度的分数段统计信息,根据分数段统计信息和用户的分数获得省实际排名;若用户输入的省排名同省实际排名不符,提示用户验证未通过,重新请求获取用户的省排名及分数信息;若用户输入的省排名同省实际排名相符,验证通过。
合理性验证是为了防止用户持续输入错误的信息,造成计算资源浪费。
如图2所示,获取考生分数和省排名后,进行合理性验证,验证通过即进行下一步,验证未通过需重新获取分数和省排名。
在本申请的另一些实施例中,在获取用户的省排名和分数信息前,将当年考生划分为k个梯度,划分标准为将l个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k≤l;推荐的志愿为在该梯度内录取往届考生的高校中一部分或全部。
在一个梯度内分析考生可填报的志愿,可以减轻系统的处理负荷,并提高准确率。
在本申请的另一些实施例中,在调用该省历年高考信息后,将往年考生划分为k`个梯度,划分标准为将l`个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k`≤l`;所述的k`=k,所述的l`=l。
将历届的考生同当前的考生同样的分类,方便进行相同梯度内的对比与分析。
如图3所示,获取招生信息后,将全省考生划分梯度,再获取考生的分数及省排名,根据划分的梯度,获取在该省排名所在分数段录取考生的高校。
在本申请的另一些实施例中,建立人工鱼群寻优模型,所述的模型中的各种参数为:种群规模n为当年的考生人数;人工鱼可视域visual为步长的1~10倍;步长step根据用户的省排名进行变化,省排位的值越大,步长越长;拥挤因子为0.1~100;尝试次数try_number为1~1000;向量x(x1,x2,……xn),xi为欲寻优的变量。
人工鱼群算法用于在获取的高校的集合内优选出录取概率高的高校,其中步长同考生的排名有关,根据一定的变化规律设置步长,以提高优选结果的准确性;人工鱼的可视域同步长有一定的关联,表明优选算法可以根据用户的省排名进行较为准确的优选。
进一步地,所述的模型中的各种参数为:种群规模n为当年的考生人数;人工鱼可视域visual为步长的1倍;步长step根据用户的省排名进行变化,省排位的值越大,步长越长;拥挤因子为0.1;尝试次数try_number为1;向量x(x1,x2,……xn),xi为欲寻优的变量。
进一步地,建立人工鱼群寻优模型,所述的模型中的各种参数为:种群规模n为当年的考生人数;人工鱼可视域visual为步长的10倍;步长step根据用户的省排名进行变化,省排位的值越大,步长越长;拥挤因子为100;尝试次数try_number为1000;向量x(x1,x2,……xn),xi为欲寻优的变量。
如图4所示,在获取高校的集合后,建立人工鱼群模型,在高校的集合中优化筛选出录取概率和学校质量较好的子集高校,向用户推荐的是筛选的高校。
在本申请的另一些实施例中,所述的人工鱼群模型中各种参数为:种群规模n为划分的梯度内的学生人数;人工鱼可视域visual为步长的2倍;所述的步长step同省排位的关系为
步长随着省排名的提高而增大,表明人工鱼群算法需要根据省排名进行调整,以提高准确率;人工鱼的初始位置设置为今年排位在去年排位的位置,可以充分的利用历史数据,提高优化结果的准确性。
进一步地,所述的步长step同省排位的关系为
进一步地,所述的步长step同省排位的关系为
更进一步地,所述的步长step同省排位的关系为
在本申请的另一些实施例中,获取高校的集合后,进行模拟投档,计算用户被集合内的每个高校录取的概率因子,所述的概率因子为历年的学校平均投档排位值同该考生排名的差值与平均投档排位值的比值。
模拟投档即计算用户被录取的概率,利用平均的排位值以及考生的排位值进行计算,概率更为准确。
在本申请的另一些实施例中,在优选出的高校的集合中进行分类,所述的分类的方法为:将高校分为冲刺类、稳妥类和保底类高校,所述的冲刺类高校不大于20所,所述的保底类高校不大于30所;获取阈值概率系数,所述的阈值概率系数为用户输入,或者所述的阈值概率系数为该类别高校平均的录取概率因子±差值阈值系数,所述的差值阈值系数为相应类别最后的高校录取的概率因子同该类别中所有高校的录取概率因子的平均数的差值;所述的冲刺类高校的阈值概率系数的较小值大于稳妥类高校的阈值概率系数的较大值,所述的稳妥类高校的阈值概率系数的较小值大于保底类高校的阈值概率系数的较大值。
帮助用户对优选出的高校进行分类,可以提高用户对推荐结果有清晰的了解。
如图5所示,划分梯度设置在获取用户的分数和省排名之前,先将本年度的高考考生划分为一定的梯度,然后将往届考生划分为同样的梯度;之后获取用户的分数和省排名,对该排名进行合理性验证后,若通过,则调用用户在其所在梯度的历年高考信息,获取往年在该省排名附近录取新生的高校的集合;建立人工鱼群寻优模型,在高校的集合中进行优选,获得高校集合的子集;对优选出的高校进行线差法核验,对核验通过的高校进行分类,分类依据阈值概率系数,该系数从用户处获取或者根据平均的录取概率因子加减不同的差值阈值系数得到。
在本申请的一些实施例中,所述的输出志愿前进行核验,所述的核验方法为获取可推荐的志愿的高校近5年同相应省控线的线差为平均线差,获取用户分数同省控线的线差为实际线差;若实际线差大于平均线差,则核验通过,输出推荐的志愿;若实际线差小于等于平均线差,则核验不通过,重新调用历年高考信息,剔除核验不合格的高校后,重新推荐高校。
通过线差法核验是为了提高高校推荐的合理性及准确性。
在本申请的另一些实施例中,概率因子为概率因子组,包括:所述的调用该省历年高考录取信息包括各高校历年在该省的招生录取信息,所述的招生录取信息包括最高分、最低分、省控线、批次、计划数、投档数、投档分、最低排位、平均线差和最低线差;根据历年招生录取信息,获取高校的平均概率因子,所述的概率因子为任一个高校在该分数段录取该用户的概率系数,所述的概率因子为历年的学校平均投档排位值同该考生排名的差值同平均投档排位的比值;根据历年招生录取信息,获取高校的调节因子,所述的调节因子用于修正平均概率因子;获取概率因子组,所述的概率因子组=平均概率因子×∏调节因子。
根据录取信息获取的概率因子再经过调节因子的调节,可以得到更为准确的录取概率,也就是概率因子组。
在本申请的另一些实施例中,将考试年份分为大年和小年;根据所述的大年或小年的划分,分别得出大年和小年录取不同分数段的考生的概率因子,分别为大年概率因子与小年概率因子;取大年概率因子与概率因子的比值得到大年调节因子;取小年概率因子与概率因子的比值得到小年调节因子。
进一步地,在本申请的另一些实施例中,大小年的录取规则根据政策变化及专家分析确定。
或者,在本申请的另一些实施例中,所述的调用的历年高考信息中包括历年各高校的投档数、投档分和平均分;根据历年的平均分、投档分和投档数,得出年平均分、年平均投档分和平均投档数,根据年平均分、年平均投档分或者平均投档数将n个考试年份分为大年和小年;若考试年份i的平均分、投档分或投档数大于年平均分、年平均投档分或平均投档数,则考试年份i为大年;若考试年份j的平均分、投档分或投档数小于等于年平均分、年平均投档分或平均投档数,则考试年份j为小年;1≤i≤j≤n;根据所述的大年或小年的划分,分别得出大年和小年录取不同分数段的考生的概率因子,分别为大年概率因子与小年概率因子;取大年概率因子与概率因子的比值得到大年调节因子;取小年概率因子与概率因子的比值得到小年调节因子。
有着大小年之分的高校的概率因子同平均的概率因子的差别较大,通过相应的调节因子进行调节后,会显著的提高准确率。
在本申请的另一些实施例中,所述的大年的概率因子组=平均概率因子×大年调节因子;所述的小年的概率因子组=平均概率因子×小年调节因子。
在本申请的一些实施例中,所述的获取用户当前的省排名和分数信息后,再获取用户的出省意愿,将用户的出省意愿分为仅省内高校和全国高校;若用户的出省意愿为仅省内高校,则在推荐院校时,剔除外省高校,仅保留省内的高校;若用户的出省意愿为全国高校,则在推荐院校时,推荐全国的高校;调用的该省的高考招生信息中包括全国高校在该省的招生信息,根据该招生信息,得出全国调节因子;所述的全国调节因子为全国概率因子同平均概率因子的比值;所述的全国概率因子为全国高校在该省的平均投档排位值与考生排名的差值同全国高校在该省的平均投档排位值的比值。
省内高校在省内的录取人数或者分数一般较为稳定,因此采用平均的概率因子计算得到的概率的准确度较高,而外省的高校在该省的招生人数或分数的变化率较大,因此需要进行修正。
如图6所示,划分梯度设置在获取用户的分数和省排名之前,先将本年度的高考考生划分为一定的梯度,然后将往届考生划分为同样的梯度;之后获取用户的分数和省排名,对该排名进行合理性验证后,若通过,则调用用户在其所在梯度的历年高考信息,获取往年在该省排名附近录取新生的高校的集合;建立人工鱼群寻优模型,在高校的集合中进行优选,获得高校集合的子集;对优选出的高校进行线差法核验,对核验通过的高校进行分类,分类依据阈值概率系数,该系数从用户处获取或者根据录取的概率因子组加减不同的差值阈值系数得到;概率因子组为概率因子根据大小年调节因子和出省意愿的调节因子进行调节。
一种高考志愿优化装置,在本申请的另一些实施例中,如图7所示,包括用户信息获取模块、历史信息调用模块、志愿推荐模块,所述的用户信息获取模块同历史信息调用模块连接,所述的历史信息获取模块同志愿推荐模块连接。所述的用户信息获取模块的功能为:获取用户当前的省排名及分数信息;所述的历史信息调用模块的功能为:调用该省历年高考信息,获取往年在该省排名及大于该省排名分数段录取新生的高校的集合;所述的志愿推荐模块的功能为:根据获取的高校的集合,输出推荐的志愿。
获取用户的省排名和分数信息后,同该省的历年高考录取信息对比,参照历年的录取信息,获取考生用户的排名可被录取的院校。
参照历史信息推荐院校,准确率较高。
在本申请的另一些实施例中,所述的用户信息获取模块同合理性验证模块连接,所述的合理性验证模块同历史信息调用模块连接,所述的合理性验证模块的功能为:获取省排名和分数信息后,进行合理性验证;所述的合理性验证为:调用当前年度的分数段统计信息,根据分数段统计信息和用户的分数获得省实际排名;若用户输入的省排名同省实际排名不符,提示用户验证未通过,重新请求获取用户的省排名及分数信息;若用户输入的省排名同省实际排名相符,验证通过。
合理性验证模块是为了防止用户持续输入错误的信息,造成计算资源浪费。
在本申请的另一些实施例中,所述的优化装置中还包括梯度划分模块连接,所述的梯度划分模块的功能为:在获取用户的省排名和分数信息前,将当年考生划分为k个梯度,划分标准为将l个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k≤l;推荐的志愿为在该梯度内录取往届考生的高校中一部分或全部。
在一个梯度内分析考生可填报的志愿,可以减轻系统的处理负荷,并提高准确率。
在本申请的另一些实施例中,所述的梯度划分模块同往年梯度划分模块连接,所述的往年梯度划分模块的功能为:在调用该省历年高考信息后,将往年考生划分为k`个梯度,划分标准为将l`个分数段中相邻的一个或数个分数段划分到一个梯度内,所述的k`≤l`;所述的k`=k,所述的l`=l。
将历届的考生同当前的考生同样的分类,方便进行相同梯度内的对比与分析。
在本申请的另一些实施例中,所述的历史信息调用模块同优化模块连接,所述的优化模块的功能为建立人工鱼群寻优模型,所述的模型中的各种参数为:种群规模n为当年的考生人数;人工鱼可视域visual为步长的1~10倍;步长step根据用户的省排名进行变化,省排位的值越大,步长越长;拥挤因子为0.1~100;尝试次数try_number为1~1000;向量x(x1,x2,……xn),xi为欲寻优的变量。
人工鱼群算法用于在获取的高校的集合内优选出录取概率高的高校,其中步长同考生的排名有关,根据一定的变化规律设置步长,以提高优选结果的准确性;人工鱼的可视域同步长有一定的关联,表明优选算法可以根据用户的省排名进行较为准确的优选;人工鱼的初始位置设置为今年排位在去年排位的位置,可以充分的利用历史数据,提高优化结果的准确性。
在本申请的另一些实施例中,所述的优化模块中的算法的部分参数:所述的人工鱼群模型中各种参数为:种群规模n为划分的梯度内的学生人数;人工鱼可视域visual为步长的2倍;所述的步长step同省排位的关系为
步长随着省排名的提高而增大,表明人工鱼群算法需要根据省排名进行调整,以提高准确率。
进一步地,所述的步长step同省排位的关系为
进一步地,所述的步长step同省排位的关系为
更进一步地,所述的步长step同省排位的关系为
在本申请的另一些实施例中,所述的历年信息调用模块同概率计算模块连接,所述的概率计算模块的功能为:获取高校的集合后,进行模拟投档,计算用户被集合内的每个高校录取的概率因子,所述的概率因子为历年的学校平均投档排位值同该考生排名的差值与平均投档排位值的比值。
模拟投档即计算用户被录取的概率,利用平均的排位值以及考生的排位值进行计算,概率更为准确。
应当理解,历年信息调用模块同概率计算模块的连接线路之间还可以设置其他模块,包括但不限于所述的优化模块和核验模块以及下文所述的年份划分模块和就读地区意愿获取模块
在本申请的另一些实施例中,所述的优化装置还包括分离模块,所述的分类模块同志愿推荐模块连接,所述的分类模块的功能为:在优选出的高校的集合中进行分类,所述的分类的方法为:将高校分为冲刺类、稳妥类和保底类高校,所述的冲刺类高校不大于20所,所述的保底类高校不大于30所;获取阈值概率系数,所述的阈值概率系数为用户输入,或者所述的阈值概率系数为该类别高校平均的录取概率因子±差值阈值系数,所述的差值阈值系数为相应类别最后的高校录取的概率因子同该类别中所有高校的录取概率因子的平均数的差值;所述的冲刺类高校的阈值概率系数的较小值大于稳妥类高校的阈值概率系数的较大值,所述的稳妥类高校的阈值概率系数的较小值大于保底类高校的阈值概率系数的较大值。
帮助用户对优选出的高校进行分类,可以提高用户对推荐结果有清晰的了解。
在本申请的一些实施例中,所述的优化装置还包括核验模块,所述的核验模块的功能为输出志愿前进行核验,所述的核验方法为获取可推荐的志愿的高校近5年同相应省控线的线差为平均线差,获取用户分数同省控线的线差为实际线差;若实际线差大于平均线差,则核验通过,输出推荐的志愿;若实际线差小于等于平均线差,则核验不通过,重新调用历年高考信息,剔除核验不合格的高校后,重新推荐高校。
通过线差法核验是为了提高高校推荐的合理性及准确性。
如图8所示,用户信息获取模块同合理性验证模块连接,所述的合理性验证模块同梯度划分模块连接,所述的梯度划分模块同往年梯度划分模块连接,往年梯度划分模块同历史信息调用模块连接,历史信息调用模块同优化模块连接,优化模块同概率计算模块连接,概率计算模块同分类模块连接,分类模块同核验模块连接,核验模块同志愿推荐模块连接。
在本申请的另一些实施例中,所述的核验概率计算模块同年份划分模块连接,所述年份划分模块的功能为:从历史信息调用模块传递来的信息中调用历年高考信息中包括历年各高校的投档数、投档分和平均分;根据历年的平均分、投档分和投档数,得出年平均分、年平均投档分和平均投档数,根据年平均分、年平均投档分或者平均投档数将n个考试年份分为大年和小年;若考试年份i的平均分、投档分或投档数大于年平均分、年平均投档分或平均投档数,则考试年份i为大年;若考试年份j的平均分、投档分或投档数小于等于年平均分、年平均投档分或平均投档数,则考试年份j为小年;1≤i≤j≤n;年份划分模块根据所述的大年或小年的划分,分别得出大年和小年录取不同分数段的考生的概率因子,分别为大年概率因子与小年概率因子;再取大年概率因子与概率因子的比值得到大年调节因子;以及取小年概率因子与概率因子的比值得到小年调节因子。
有着大小年之分的高校的概率因子同平均的概率因子的差别较大,通过相应的调节因子进行调节后,会显著的提高准确率。
在本申请的另一些实施例中,所述的大年的概率因子组=平均概率因子×大年调节因子;所述的小年的概率因子组=平均概率因子×小年调节因子。
在本申请的一些实施例中,所述的概率计算模块同就读地区意愿获取模块连接,所述的就读地区意愿获取模块获取用户的出省意愿,将用户的出省意愿分为仅省内高校和全国高校;若用户的出省意愿为仅省内高校,则在推荐院校时,剔除外省高校,仅保留省内的高校;若用户的出省意愿为全国高校,则在推荐院校时,推荐全国的高校;调用的该省的高考招生信息中包括全国高校在该省的招生信息,根据该招生信息,调节模块得出全国调节因子。
省内高校在省内的录取人数或者分数一般较为稳定,因此采用平均的概率因子计算得到的概率的准确度较高,而外省的高校在该省的招生人数或分数的变化率较大,因此需要进行修正。
在本申请的一些实施例中,概率因子组=平均概率因子×全国调节因子。
在本申请的另一实施例中,概率因子组=平均概率因子×大年调节因子×全国调节因子。
在本申请的另一实施例中,概率因子组=平均概率因子×小年调节因子×全国调节因子。
进一步地,在本申请的另一些实施例中,所述的志愿推荐模块的功能为输出志愿,在输出志愿前推荐的志愿进行分类,将概率计算模块计算出的各高校的概率因子组中小于一定值的剔除,仅保留概率因子组较高的高校,以提高推荐的准确性。
如图9所示,梯度划分模块同往年梯度划分模块连接,往年梯度划分模块同用户信息获取模块连接,所述的用户信息获取合理性验证模块连接,所述的合理性验证模块同历史信息验证模块连接,所述的历史信息验证模块同优化模块连接,所述的优化模块同核验模块连接,所述的核验模块年份划分模块连接,所述的年份划分模块同就读地区意愿获取模块连接,所述的就读地区意愿获取模块同概率计算模块连接,概率计算模块同分类模块连接,所述的分类模块同志愿推荐模块连接。
一种高考志愿优化终端,包括一个或多个处理器;以及存储装置,用于存储一个或多个程序;当所述一个或多个程序被所述的一个或多个处理器执行,使得所述的一个或多个处理器实现如上述的高考志愿优化方法。
一种高考志愿优化存储介质,所述的一个或多个程度可被一个或多个处理器执行,以实现上述的方法。
上列详细说明是针对本发明可行实施例的具体说明,以上实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
- 还没有人留言评论。精彩留言会获得点赞!