一种数据聚合清洗方法及系统与流程
本发明涉及数据清洗领域,具体的说,涉及了一种数据聚合清洗方法及系统。
背景技术:
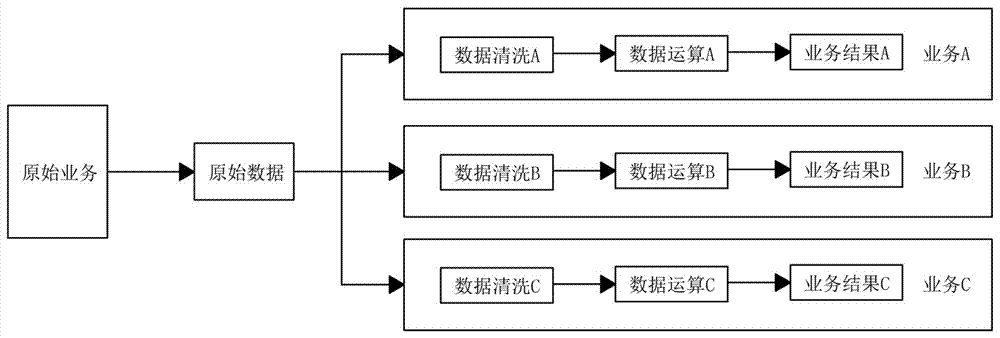
如图1所示,在传统hadoop数据聚合清洗业务中,即使要处理的数据源相同,但按照业务的不同仍需要设计不同的数据清洗流程,这样会造成清洗业务效率及灵活度低下;因为各个清洗业务的结果有强业务关联性,故无法提供给其他清洗业务作为输入数据,这会导致运算力的大量浪费;由于每个清洗业务均会直接读取原始数据,这会引起大量重复的i/o操作,甚至会降低原始业务的i/o性能,从而影响原始业务系统;并且各个清洗业务的开发人员水平不尽相同,但每个清洗业务均需要直接接触原始业务系统,可能会出现因操作不规范引起的数据安全问题,从而威胁原始业务的安全性。
为了解决以上存在的问题,人们一直在寻求一种理想的技术解决方案。
技术实现要素:
本发明的目的是针对现有技术的不足,从而提供了一种数据聚合清洗方法及系统,能够降低批量数据清洗业务对原始业务的干扰,提升数据安全性。
为了实现上述目的,本发明所采用的技术方案是:一种数据聚合清洗方法,该清洗方法包括以下步骤:
从原始业务系统中提取原始数据;
提取的原始数据经前置清洗后生成前置清洗结果存储在公共数据库内;
不同清洗业务根据需求从公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果。
基于上述,所述前置清洗采用最小颗粒度清洗方法,包括以下步骤:
将提取的原始数据送入至一个或多个mapreducejob作业中;
每个mapreducejob使用多个预设正则表达式对原始数据的所有有效字段进行匹配,剥离干扰信息,取出目标格式数据,每个正则表达式对应一种原始数据;
匹配结束后将目标格式数据以结构化数据的形式保存在hbase数据库内,即形成前置清洗结果。
基于上述,不同清洗业务根据需求从公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果的具体步骤为:
创建一个与hbase数据库关联的hive外联表,并对不同清洗业务的数据读取权限进行限制;
不同清洗业务根据需求和数据读取权限从hbase数据库内提取所需前置清洗结果,并基于该清洗业务的数据运算方法进行清洗运算,以生成相应的清洗结果。
基于上述,从原始业务系统中提取原始数据后,将原始数据复制到临时存储服务器中,再从临时存储服务器中读取原始数据进行前置清洗。
基于上述,所述前置清洗采用父业务清洗方法,具体包括以下步骤:
选取一个清洗业务作为父业务,并依次比较各个清洗业务与父业务之间的重合度,当重合度大于预设重合度阈值时,将该清洗业务并入父业务中;
提取的原始数据经父业务清洗后,即生成前置清洗结果。
本发明还提供一种数据聚合清洗系统,该清洗系统包括数据读取器、前置清洗设备、公共数据库和多个业务不同的后置清洗设备,
所述数据读取器用于从原始业务系统中提取原始数据;
所述前置清洗设备,用于对提取的原始数据进行前置清洗,并将生成的前置清洗结果存储在所述公共数据库内;
所述后置清洗设备根据需求从所述公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果。
基于上述,所述前置清洗设备包括hbase数据库和一个或多个mapreducejob作业,
每个mapreducejob作业内均设有多个正则表达式,每个正则表达式对应一种原始数据,不同mapreducejob作业具有不同的正则表达式;
所述mapreducejob使用预设的正则表达式对原始数据的所有有效字段进行匹配,并在匹配结束后将匹配结果以结构化数据的形式保存在hbase内,即生成前置清洗结果。
基于上述,还包括与所述hbase数据库相关联的hive外联表,所述hive外联表还用于对不同清洗业务的数据读取权限进行限制;不同清洗业务根据需求、所述hive外联表以及数据读取权限从所述hbase数据库内提取所需前置清洗结果。
基于上述,还可以包括临时存储服务器,所述临时存储服务器与所述数据读取器连接,用于存储所述数据读取器读取的原始数据;所述前置清洗设备与所述临时存储服务器连接,用于从所述临时存储服务器中读取原始数据。
基于上述,所述前置清洗设备还可以合并重合度较高的清洗业务作为父业务,并利用父业务对提取的原始数据进行数据清洗,生成前置清洗结果。
本发明相对现有技术具有突出的实质性特点和显著的进步,具体的说,本发明通过设置前置清洗设备对原始数据进行前置清洗,并将前置清洗结果存储在公共数据库中,各个清洗业务根据需要从公共数据库中提取所需数据进行相应的数据清洗,该方法将原始业务系统与各个清洗业务进行隔绝,大大降低了原始业务的i/o压力,减少了各个清洗业务对原始业务的干扰;
同时本发明中的前置清洗采用的是最小颗粒度清洗方法,通过将各个清洗业务重复的运算工作单独剥离出来,减少重复运算,以提升处理效率;不论清洗业务如何变更,仅需要读取最小结果内的数据,最小结果被重复利用,运算力的利用率得以提高;通过hive关联表对各个清洗业务读取权限进行限制,从而仅向每个清洗业务提供其运算需要的数据部分,大大提升了数据安全性,防止数据被滥用;
并且由于最小结果的结构化存储方式,不论是调整或是新增清洗业务,只需要关注其数据运算部分即可,而无需重写数据清洗方法,这使得下级的清洗业务更加灵活。
附图说明
图1是传统数据聚合清洗流程示意图。
图2是本发明所述的数据聚合清洗方法的流程示意图。
图3是前置清洗方法的流程示意图。
具体实施方式
下面通过具体实施方式,对本发明的技术方案做进一步的详细描述。
原始数据以工作日志为例,在使用weblogic容器运行的系统内,会产生大量的工作日志,在传统清洗业务中,若需要统计一段时间内所有日志级别为error的日志条目数量(清洗业务a),需要直接读取原始日志,完全读取日志文件后,统计出相应的条目数量;若同时还有其他清洗业务,如统计出现warn级别日志的发生热点时间段(清洗业务b),则需要再次从原始日志文件读取,仍需要完整读取整个日志文件后得出结果。日志文件通常存储在原始业务所在的服务期内,这样反复频繁读物大体积文件显示会对原始业务造成干扰。且原始日志文件的读取效率十分低下,反复读取同一份日志文件会消耗大两的时间与计算力。
为了解决上级问题,如图2所示,本发明提供了一种数据聚合清洗方法,该清洗方法包括以下步骤:
从原始业务系统中提取原始数据;
提取的原始数据经前置清洗后生成前置清洗结果存储在公共数据库内;
具体的,如图3所示,前置清洗采用最小颗粒度清洗方法,这里所述的“最小颗粒度”体现:若原始数据格式为a-b-c-d-e,最小颗粒度的目标是取出字段a、b、c、d、e,此时的颗粒度为最小。
最小颗粒度清洗方法的具体步骤为:将提取的原始数据以分布式架构hfds送入至一个或多个mapreducejob作业中;
每个mapreducejob使用多个预设的正则表达式对原始数据的所有有效字段进行匹配,剥离干扰信息,取出目标格式数据;优选的,一个正则表达式对应一种类型数据结构,用于进行该类型数据结构的匹配,其针对性极强,如数据格式为a-b-c的数据所对应的正则表达式与数据格式为a-b-cd的数据所对应的正则表达式完全不同;但在某些场景下,如weblogic日志、tomcat日志,其数据格式/结构完全一致,所以可以使用相同的正则表达式,即实现“通用”;
匹配结束后采用hbasebulkload将匹配结果以结构化数据的形式批量保存在hbase数据库内,即形成前置清洗结果;
不同清洗业务根据需求从公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果。
为了便于理解,假设原始数据的数据结构为”a-b-c-d-e”,当前的有效字段为5个,即“a、b、c、d、e”。此时有两个分析需求,这里称他们为a1与a2;如分析方法a1需要原始数据的a、b、c三个字段,分析方法a2需要b、c、d三个字段,传统清洗过程中,a1、a2分析方法需要针对自己的需求分别对原始数据进行清洗,以取出自己需要的字段,这样会造成重复的工作,即对同一种数据清洗两次,即a1需要完整清洗一次原始数据,取出a、b、c字段,a2还需要再完整清洗一次原始数据,取出b、c、d字段。
但在本发明中,我们使用前置清洗方法对原始数据进行清洗,即一次性取出所有有效字段“a、b、c、d、e”,a1与a2方法只需要针对自己的需求直接从hbase数据库中拿取目标字段进行相应的数据清洗和分析即可,而不需要对原始数据再次清洗。该方法将原始业务系统与各个清洗业务进行隔绝,大大降低了原始业务的i/o压力,减少了各个清洗业务对原始业务的干扰。
同时本发明中的前置清洗采用的是最小颗粒度清洗方法,即通过mapreducejob作业将各个清洗业务重复的运算工作单独剥离出来,对一种格式的数据只进行一次清洗,即可满足之后所有需要利用该数据进行分析的各种需求,减少了重复运算,提升了处理效率;而且不论清洗业务如何变更,仅需要读取hbase数据库中的数据,这些数据被重复利用,也使得运算力的利用率得以提高;并且由于hbase数据库中的数据是以结构化存储方式进行存储,因此不论是调整或是新增清洗业务,只需要关注其数据运算部分即可,而无需重写数据清洗方法,这使得下级的清洗业务更加灵活。
具体的,不同清洗业务根据需求从公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果的具体步骤为:
创建一个与hbase数据库关联的hive外联表,并可根据清洗业务的不同对不同清洗业务的数据读取权限进行限制;限制可以有多种维度,主要是类型、深度、密度,具体表现在业务上,就是清洗业务可不可以读取特定hive表内的数据、可以读哪几列、可以读多久;
不同清洗业务根据需求和数据读取权限从hbase数据库内提取所需前置清洗结果,并基于该清洗业务的数据运算方法进行清洗运算,以生成相应的清洗结果。
通过对不同清洗业务的数据读取权限进行限制,使得不同的清洗业务只能读取和清洗特定需求的前置清洗结果,与传统hadoop数据聚合清洗业务相比,该方法极大提升了数据清洗的安全性,有效防止了数据被滥用。
更进一步的,从原始业务系统中提取原始数据后,还可以将原始数据复制到临时存储服务器中,再从临时存储服务器中读取原始数据进行前置清洗。从而将原始数据与前置清洗业务也分割开,使得前置清洗业务也无法直接读取原始数据,这样大大降低了生产原始数据的原始业务服务器的i/o压力,进一步减少了数据清洗对原始业务的干扰。
需要注意的是,所述前置清洗还可以采用父业务清洗方法,具体包括以下步骤:
选取一个清洗业务作为父业务,并依次比较各个清洗业务与父业务之间的重合度,当重合度大于预设重合度阈值时,将该清洗业务并入父业务中;
提取的原始数据经父业务清洗后,即生成前置清洗结果。
该方法通过合并重合度高的清洗业务,将各个清洗业务中重复度高的运算工作剥离出来,使得重复度高的运算工作只需要进行一次,与传统hadoop数据聚合清洗业务相比,该方法同样将原始业务系统与各个清洗业务进行隔绝,大大降低了原始业务的i/o压力,减少了各个清洗业务对原始业务的干扰,同时该方法的运算也大幅度减少,处理效率得到提升。
本发明还提供一种数据聚合清洗系统,该清洗系统包括数据读取器、前置清洗设备、公共数据库和多个业务不同的后置清洗设备,
所述数据读取器用于从原始业务系统中提取原始数据;
所述前置清洗设备,用于对提取的原始数据进行前置清洗,并将生成的前置清洗结果存储在所述公共数据库内;
所述后置清洗设备根据需求从所述公共数据库内提取所需前置清洗结果进行清洗运算,以生成相应的清洗结果。
具体的,所述前置清洗设备包括hbase数据库和一个或多个mapreducejob作业,
每个mapreducejob作业内均针对不同类型数据结构设置有正则表达式,每个正则表达式对应一种原始数据,不同mapreducejob作业具有不同的正则表达式;
所述mapreducejob使用预设的正则表达式对原始数据的所有有效字段进行匹配,并在匹配结束后将匹配结果以结构化数据的形式保存在hbase内,即生成前置清洗结果。
具体的,所述清洗系统还包括与所述hbase数据库相关联的hive外联表,所述hive外联表还用于对不同清洗业务的数据读取权限进行限制;不同清洗业务根据需求、所述hive外联表以及数据读取权限从所述hbase数据库内提取所需前置清洗结果。
具体的,所述清洗系统还可以包括临时存储服务器,所述临时存储服务器与所述数据读取器连接,用于存储所述数据读取器读取的原始数据;所述前置清洗设备与所述临时存储服务器连接,用于从所述临时存储服务器中读取原始数据。
具体的,所述前置清洗设备还可以合并重合度较高的清洗业务作为父业务,并利用父业务对提取的原始数据进行数据清洗,生成前置清洗结果。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 还没有人留言评论。精彩留言会获得点赞!