一种基于时空关注度机制的多行人在线跟踪方法与流程
本发明涉及计算机视频处理技术领域,具体地,涉及一种基于时空关注度机制的多行人在线跟踪方法。
背景技术:
多行人跟踪任务就是要在包含多个行人的视频中,计算每个行人目标的轨迹并进行追踪。该算法在实际场景有广泛的应用,比如无人驾驶、智能视频监控、球类运动分析等。其挑战在于(1)视频中行人目标数量不定,随时可能进入和离开视野范围;(2)不同行人间容易频繁交互产生遮挡,对目标的跟踪造成干扰。
现有的多行人跟踪方法可以分为离线和在线两大类。离线方法以整体视频内容作为输入,分析当前视频帧时可以利用过去和未来帧的全局信息建立全局优化的图模型,因此对目标遮挡和短暂丢失等问题的鲁棒性更强。然而其局限性在于无法应用在实时场景中,比如无人驾驶和球赛实况分析。相比之下,在线方法只利用历史视频帧信息实时计算当前帧的目标位置,因而应用范围更广。
现有的多行人在线跟踪方法存在以下局限:(1)传统跟踪算法中的搜索区域存在正负训练样本不均衡的问题,有效的正样本很少而作用微小的背景负样本却很多。这会在一定程度上降低跟踪模型的抗干扰性能,造成跟踪对象的漂移。(2)由于行人间的交互频繁发生,仅仅利用历史帧信息计算得到的轨迹中容易包含位置不准确或被遮挡的噪声样本。现有的在线多行人跟踪方法没有对噪声样本的抗干扰和过滤机制,噪声的不断积累会对后续跟踪产生干扰,造成目标轨迹的偏移或丢失。
目前没有发现同本发明类似技术的说明或报道,也尚未收集到国内外类似的资料。
技术实现要素:
本发明的目的在于克服上述现有多行人在线跟踪方法的不足之处,提出了一种基于时空关注度机制的多行人在线跟踪方法,可以应用于智能视频监控,无人驾驶等场景中。首先,针对跟踪算法正负样本不均衡的问题,本发明设计了融合自适应样本权重项的目标函数,根据跟踪模型训练过程计算得到的损失值重新分配样本权重,提升了样本训练的有效性。然后针对跟踪中产生的位置不准确或者被遮挡的噪声样本,本发明设计了融合时空关注度机制的深度神经网络模型。在空域上,该网络会自主学习关注样本中的相关区域而忽略非相关区域,在时域上模型会根据轨迹中的样本一致性主动关注轨迹中的正确样本而忽略噪声样本,从而提升了对行人保持持续跟踪的能力。
本发明是通过以下技术方案实现的。
一种基于时空关注度机制的多行人在线跟踪方法,包括以下步骤:
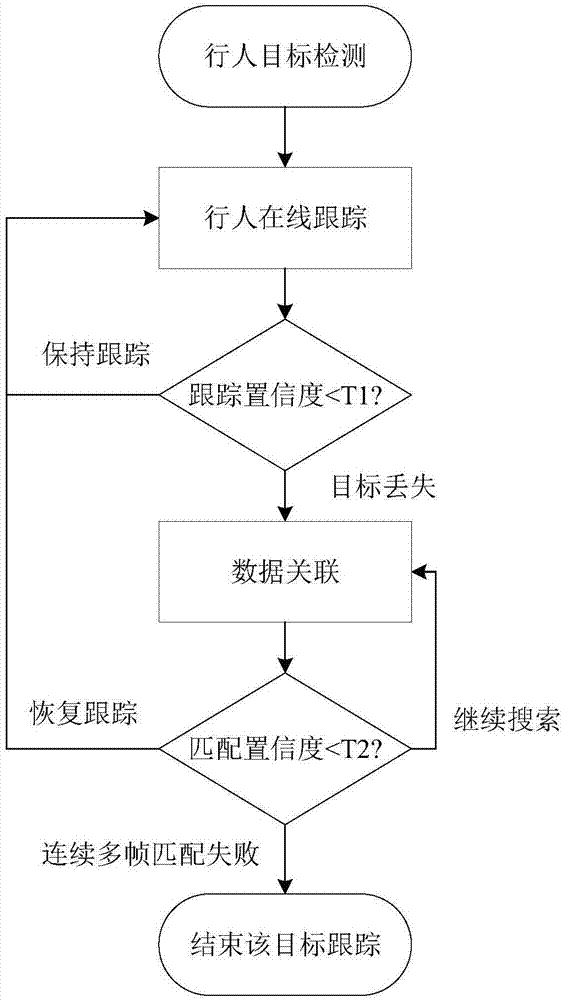
s1:使用dpm目标检测算法检测出当前视频帧中行人目标的位置;
s2:对当前视频帧中的每个行人进行在线目标跟踪并计算目标跟踪的置信度分数;
s3:如果行人目标跟踪的置信度分数低于设定阈值则暂停跟踪,判定目标进入丢失状态,此时需在后续视频帧中不断对新检测到的候选行人目标和已丢失行人目标的轨迹之间进行数据关联,若已丢失行人目标关联成功则恢复s2的跟踪;
s4:若行人目标保持丢失状态超过预设的时间阈值,则判定该行人目标消失在场景中,并终止对该行人目标的跟踪。
优选地,s2中所述的在线目标跟踪并计算目标跟踪的置信度分数,包括以下步骤:
s21:以行人第一帧的初始检测框为中心,选取长宽分别为该检测框长宽2倍的矩形区域作为采样区域,采集正负图像样本,初始化训练卷积滤波器f;其中,正图像样本为与检测框的交并比大于0.9的矩形区域内图像,负图像样本为与检测框的交并比小于0.4的矩形区域内图像;
s22:在当前帧的目标搜索区域内,用上一帧训练学习到的卷积滤波器f对目标搜索区域做卷积操作,取置信度值最高的位置作为当前帧行人目标的位置;
s23:利用当前帧采样区域的正负样本,训练更新卷积滤波器f;
s24:采用s23中当前帧训练更新得到的卷积滤波器f对下一帧目标搜索区域做卷积操作,并取置信度值最高的位置作为下一帧行人目标的位置。
优选地,s23中,训练更新卷积滤波器f采用如下目标优化函数:
其中,m表示训练卷积滤波器f模型所利用的历史视频帧数,αj表示第j帧的学习权重,q(t)表示每一帧中不同位置样本的自适应权重项,可以根据不同位置样本的损失值的相对大小自适应分配样本权重,l2表示l2范数,d表示多分辨卷积滤波器f的分辨率个数,w(t)表示空域正则化函数,fd(t)表示多分辨卷积滤波器f中编号为d的滤波器fd(t),xj表示第j个训练样本,sf表示利用卷积滤波器f对样本xj做卷积的操作函数,yj表示第j个训练样本期望的置信度响应值分布。
优选地,s3中的数据关联包括空域关联和时域关联两个过程,其中,空域关联过程将需要关联的两张图片输入融合空域关注度机制的深度神经网络提取空域关注度特征,时域关联过程将需要关联的目标轨迹中每个样本的空域关注度特征输入融合时域关注度机制的深度神经网络判定数据关联的置信度。
优选地,空域关联过程中使用的融合空域关注度机制的深度神经网络结构,从输入到输出包括:两个权值参数共享的特征提取层、一个匹配层、一个卷积核大小为1x1的卷积层、两个空域关注度层、一个特征合并层和一个全连接层a。
优选地,匹配层对特征提取层提取的卷积特征图xα,xβ做归一化并计算xα,xβ间的相似矩阵s如下:
其中
优选地,对于卷积特征图xα,将相似矩阵s经过卷积核大小为1x1的卷积层输出对应的空域关注度层aα,aα上每个位置的关注度值计算如下:
其中,θs表示1x1卷积层的权值向量,
对于卷积特征图xβ,将相似度矩阵s的转置st经过卷积核大小为1x1的卷积层,输出对应的空域关注度层aβ,aβ上每个位置的关注度值计算如下:
其中,θs表示1x1卷积层的权值向量,
优选地,卷积特征图xα,xβ分别与其对应的空域关注度层aα,aβ相乘,经过全局池化得到融合空域关注度的特征向量
优选地,时域关联过程中使用的融合时域关注度机制的深度神经网络结构,从输入到输出包括:一个双向长短时记忆层、一个全连接层b、一个时域关注度层、一个加权平均池化层和一个二分类输出层。
优选地,时域关注度层计算得到的每个样本的时域关注度值定义如下:
其中,
优选地,加权平均池化层将时域关注度层计算得到的时域关注度值{a1,…,at}作为权重对时域双向特征
与现有技术相比,本发明具有如下有益效果:
(1)针对现有在线跟踪算法用于训练模型的正、负样本不均衡的问题提出了融合自适应样本权重项的跟踪目标函数,根据样本在模型训练过程中计算得到的损失值重新分配样本权重,提升了模型更新的有效性;
(2)针对数据关联中易受被遮挡或位置偏移的噪声样本干扰的问题,提出了融合时空域关注度机制的深度神经网络匹配模型,使其在空域上关注比对图片中的相关区域而忽略非相关区域,在时域上模型关注历史轨迹中的正样本而忽略噪声样本,从而提升了多行人跟踪的准确率。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明提供的基于时空关注度机制的多行人在线跟踪方法流程图。
图2为本发明一实施例提供的融合空域关注度机制的深度神经网络结构示意图。
图3为本发明一实施例提供的融合时域关注度机制的深度神经网络结构示意图。
具体实施方式
下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
实施例
本实施例提供了一种基于时空关注度机制的多行人在线跟踪方法,下面结合一具体应用实例,对本发明实施例的技术方案进行详细说明。
本实施例采用的视频来自多目标跟踪数据集mot16,该数据集包含7个训练视频和7个测试视频,每个视频包含不同的场景、拍摄角度和人群密度。
本实施例涉及的多行人在线跟踪方法,其流程图如图1所示,包括如下具体步骤:
1.使用dpm(deformablepartsmodel)目标检测算法检测出当前视频帧的行人目标位置。
2.对视频帧中的每个行人同时进行在线跟踪并计算跟踪的置信度分数,具体步骤如下:
(1)给定视频第一帧中某个行人目标的检测框,以该行人检测框中心为中心,选取长宽分别为该检测框长宽2倍的矩形区域作为采样区域,均匀采集正负图像样本(其中,正图像样本为与检测框的交并比大于0.9的矩形区域内图像,负图像样本为与检测框的交并比小于0.4的矩形区域内图像),用于初始化学习卷积滤波器f,使得该滤波器在对应目标中心位置的样本上置信度响应值最高。
(2)在接下来的视频帧中,以上一帧的行人检测框中心为中心,选取长宽分别为该检测框长宽2倍的矩形区域作为当前帧的目标搜索区域,用上一帧训练学习到的卷积滤波器f对搜索区域做卷积操作,取置信度响应值最高的位置作为当前帧行人目标的位置。
(3)以当前帧搜索区域内行人目标的位置区域作为正样本,以搜索区域内的其他样本作为负样本,训练更新卷积滤波器f。本实施例定义的用于更新卷积滤波器的目标函数中引入了自适应样本权重项q(t),该目标函数的具体定义如下:
其中,m表示训练模型所利用的历史视频帧数,αj表示第j帧的学习权重,q(t)表示每一帧中不同位置样本的自适应权重项,可以根据不同位置样本的损失值的相对大小自适应分配样本权重,l2表示l2范数,d表示多分辨卷积滤波器f的分辨率个数,w(t)表示空域正则化函数,fd(t)表示多分辨卷积滤波器f中编号为d的滤波器fd(t),xj表示第j个训练样本,sf表示利用卷积滤波器f对样本xj做卷积的操作函数,yj表示第j个训练样本期望的置信度响应值分布。
(4)在下一帧中,以当前帧的行人检测框中心为中心,选取长宽分别为该检测框长宽2倍的矩形区域作为下一帧的目标搜索区域,用当前帧训练学习到的卷积滤波器f对搜索区域做卷积操作,计算置信度响应分布图,并取置信度响应值最高的位置作为下一帧行人目标的位置。
3、当行人被遮挡时,跟踪的置信度分数会低于一定阈值造成目标丢失,本实施例将跟踪置信度阈值设置为0.2。低于该阈值时,判定目标暂时丢失,并需要在后续视频帧中不断将新检测到的候选行人目标和已丢失行人目标的轨迹做数据关联,一旦丢失目标重新关联上就恢复第2步的跟踪。数据关联过程中涉及空域比对和时域比对两个环节。空域上将候选行人样本图片与已丢失行人的历史轨迹中每个样本图片单独提取特征并进行比对,时域上需要综合历史轨迹中所有样本的比对信息,计算匹配关联的置信度。数据关联的具体步骤如下:
(1)在空域上,在该实施例中将需要比对的两张行人图片缩放为大小为224x224的正方形图片,输入图2所示的融合空域关注度机制的深度神经网络提取比对特征。该神经网络从输入到输出包含两个权值参数共享的特征提取层,一个匹配层,一个卷积核大小为1x1的卷积层,两个空域关注度层,一个特征合并层和一个全连接层。其中,特征提取层利用resnet50分类网络结构提取两张图片的卷积特征图xα,xβ,本实施例中卷积特征图的维度为7x7x2048。匹配层对resnet50提取的卷积特征做归一化并计算xα,xβ间的相似矩阵s如下:
本实施例中,
其中θs表示1x1卷积层的权值向量,
其中,θs表示1x1卷积层的权值向量,
(2)在时域上,将历史轨迹中所有样本的空域比对特征输入图3所示的融合时域关注度机制的深度神经网络,计算数据关联的置信度。该神经网络从输入到输出包含一个双向长短时记忆层(bi-directionallongshorttermmodel,bi-lstm),一个全连接层,一个时域关注度层,一个加权平均池化层和一个二分类输出层。其中,bi-lstm层可以综合历史轨迹中所有样本的空域比对特征
接下来,加权平均池化层将时域关注度层计算得到的时域关注度值{a1,…,at}作为权重对时域双向特征
最终将融合时域关注度的特征向量
4.本实施例中,若目标持续保持丢失状态超过50帧,则认为该目标已消失在场景中,并放弃对其的继续跟踪。
本实施例采用多目标跟踪准确率(multiple0bjecttrackingaccuracy,mota)来评估本发明提出的多行人在线跟踪方法的性能。实验中使用未引入本发明上述实施例提出的自适应样本权重项和时空关注度机制的传统方法作为对比基准,通过逐步融合本发明上述实施例提出的改进方法并加以评估,验证本发明上述实施例所提供的技术方案的有效性。表1给出了mot16数据集上的mota评估结果。实验证明,本发明上述实施例较之传统方法能够更好地处理被遮挡和位置偏移的噪声样本,从而有效提升多行人在线跟踪的精度。
表1
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!