数据分析工作流的运行方法、数据分析系统及存储介质与流程
本发明涉及数据处理领域,尤其涉及一种数据分析工作流的运行方法、数据分析系统及存储介质。
背景技术:
随着社会信息化和智能化水平提高,使用大数据分析系统训练业务模型,并使用训练好的业务模型实现大数据业务智能化处理也逐渐成为大数据行业的通用手段。但是,现有大数据分析系统在进行大数据分析时只能择一选用单机或分布式方式处理数据、训练模型,不能灵活配置资源消耗与数据分析之间的精细平衡,造成大数据分析系统的效率低。
技术实现要素:
为了解决上述技术问题,本发明提供一种数据分析工作流的运行方法,旨在提高数据分析系统的效率。
为了达到上述目的,本发明提出一种数据分析工作流的运行方法,所述数据分析工作流包括多于一个的工作流模块,所述运行方法包括以下步骤:
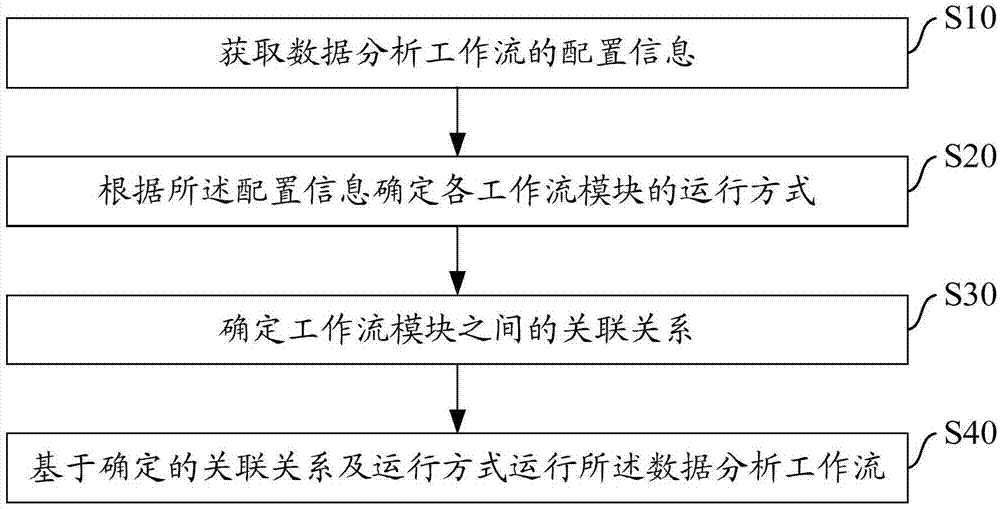
获取数据分析工作流的配置信息;
根据所述配置信息确定各工作流模块的运行方式;
确定工作流模块之间的关联关系;
基于确定的关联关系及运行方式运行所述数据分析工作流。
进一步地,所述关联关系包括并行/串行关系,所述基于确定的关联关系及运行方式运行所述数据分析工作流的步骤,包括:
基于确定的并行/串行关系,以单机或分布式方式运行所述各工作流模块。
进一步地,所述基于确定的并行/串行关系,以单机或分布式运行所述各工作流模块的步骤,包括:
基于确定的并行/串行关系,确定待运行工作流模块;
向本地资源管理中心提交资源运行申请;
基于申请到的运行资源对待运行工作流模块进行容器实例部署;
基于部署的容器实例运行所述待运行工作流模块。
进一步地,所述基于申请到的运行资源对待运行工作流模块进行容器实例部署的步骤,包括:
容器引擎接收本地资源管理中心发起的容器启动请求;
容器引擎基于待运行工作流模块的容器镜像启动容器。
进一步地,所述容器引擎基于待运行工作流模块的容器镜像启动容器的步骤,包括:
容器引擎检查本地是否存在与待运行工作流模块对应的容器镜像;
若否,则从容器镜像数据库拉取相应容器镜像至本地,启动容器;
若是,则基于预设启动策略启动容器。
进一步地,所述基于部署的容器实例运行所述待运行工作流模块的步骤,包括:
确定待运行工作流模块的运行方式;
若为单机运行方式,则基于启动的容器执行待运行工作流模块的计算分析任务;
若为分布式运行方式,则基于从分布式资源管理中心获取的运行会话执行待运行工作流模块的计算分析任务。
进一步地,还包括:
将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块。
进一步地,所述将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块的步骤,包括:
将以单机方式运行成功的工作流模块的输出文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地读取;或,
将以单机方式运行成功的工作流模块的输出文件上传至分布式文件系统dfs,由具有串行关系且分布式运行的工作流模块以加载dfs文件的方式引用;或,
将以分布式方式运行成功的工作流模块输出的dfs文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地加载引用;或,
将以分布式方式运行成功的工作流模块输出的分布式数据资源标识传递给具有串行关系且分布式运行的工作流模块。
进一步地,所述运行方法还包括以下步骤:
对数据分析工作流进行分步运行。
进一步地,在执行所述对数据分析工作流进行分步运行的步骤时,若所述工作流模块为分布式运行方式,还执行以下步骤:
基于检测到的预设启动参数,将当前运行引擎切换至分步运行模式;
捕获并记录分布式工作流模块的运行日志,输出为可查看的日志文件;
将工作流模块的输出文件由分布式存储转换为本地存储。
进一步地,所述工作流模块包括数据模块,所述数据模块中数据文件的格式包括下述至少之一:txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式。
进一步地,新建数据模块的步骤,包括:
确定数据接入类型;
基于数据接入类型确定数据的统一资源标识uri;
配置待接入数据文件的文件格式。
进一步地,还包括:
基于检测到的针对数据模块的预览或分析操作,显示对应的可视化信息。
进一步地,所述基于检测到的针对数据模块的预览或分析操作,显示相应的可视化信息的步骤,包括:
获取选择的数据接入类型;
根据所述数据接入类型以预设模式加载数据文件;
基于预设条件对加载的数据文件进行筛选或分析,并将筛选结果或分析结果进行可视化展示。
进一步地,所述根据所述数据接入类型以预设模式加载数据文件的步骤,包括:
当接入数据为本地文件时,以本地模式启动计算引擎spark组件线程加载本地数据文件;
当接入数据为dfs文件时,启动分布式集群上的spark组件服务加载数据文件。
进一步地,所述工作流模块包括分析模块,多于一个的分析模块基于两种以上的开发语言分别创建,创建分析模块的步骤,包括:
基于选择的开发语言使用对应的容器镜像创建所述分析模块。
进一步地,在所述基于选择的开发语言使用对应的容器镜像创建所述分析模块的步骤之前,还包括:
定制各开发语言的容器镜像。
进一步地,所述定制各开发语言的容器镜像的步骤,包括:
针对各发语言定制其运行时环境、日志监控服务、语言开发基础库,并封装成预设格式的容器镜像;
构建容器镜像与开发语言的一一映射关系。
进一步地,在执行基于选择的开发语言使用对应的容器镜像创建所述分析模块的步骤时,还执行以下步骤:
设置分析模块进行数据输入/输出的数据格式。
进一步地,所述基于选择的开发语言使用对应的容器镜像创建所述分析模块的步骤,包括:
基于选择的开发语言引用容器镜像内部预置的算法框架创建所述分析模块;或,
基于选择的开发语言对应的语言扩展包中包含的算法框架创建所述分析模块。
进一步地,所述运行方法还包括:
生成预设格式的算法模型,所述算法模型的格式包括pkl格式、预测模型标记语言pmml格式、h5格式中的至少之一。
进一步地,在生成预设格式的算法模型之后,还包括:
对生成的算法模型进行评估。
进一步地,所述对生成的算法模型进行评估的步骤,包括:
识别算法模型的格式;
根据算法模型的格式加载所述算法模型;
判定所述算法模型的类别;
根据所述算法模型的类别使用对应的评估指标进行评估。
进一步地,所述对生成的算法模型进行评估的步骤,还包括:
对算法模型的各评估指标的分数和算法模型信息进行存储。
进一步地,所述算法模型的类别包括下述至少之一:聚类、分类、回归、异常检测及语言处理。
进一步地,所述运行方法还包括:
对评估后的算法模型进行发布。
进一步地,所述对评估后的算法模型进行发布的步骤,包括:
基于算法模型的各评估指标的分数筛选待发布算法模型;
对筛选出的待发布算法模型进行发布。
进一步地,所述对筛选出的待发布算法模型进行发布的步骤,包括:
识别待发布算法模型的格式;
确定模型服务的部署策略和调用方式;
构建模型服务镜像,并基于所述部署策略申请发布资源;
基于申请到的发布资源运行所述模型服务镜像,按照识别的格式解析所述待发布算法模型,并按照确定的调用方式提供应用发布的算法模型的接口。
进一步地,所述模型服务的调用方式包括超文本传输协议-表述行状态转移http-rest接口调用、消息队列mq调用、及批处理batch调用中的至少一种。
本发明进一步提出一种数据分析系统,用于运行数据分析工作流,所述数据分析工作流包括多于一个的工作流模块,该数据分析系统包括:
获取模块,用于获取数据分析工作流的配置信息;
确定模块,用于根据所述配置信息确定各工作流模块的运行方式;
所述确定模块还用于确定工作流模块之间的关联关系;
运行模块,用于基于确定的关联关系及运行方式运行所述数据分析工作流。
进一步地,所述关联关系包括并行/串行关系,所述运行模块还用于基于确定的并行/串行关系,以单机或分布式方式运行所述各工作流模块。
进一步地,所述运行模块包括:
确定单元,用于基于确定的并行/串行关系,确定待运行工作流模块;
申请单元,用于向本地资源管理中心提交资源运行申请;
部署单元,用于基于申请到的运行资源对待运行工作流模块进行容器实例部署;
运行单元,用于基于部署的容器实例运行所述待运行工作流模块。
进一步地,所述部署单元用于:
接收本地资源管理中心发起的容器启动请求;
基于待运行工作流模块的容器镜像启动容器。
进一步地,所述部署单元还用于:
检查本地是否存在与待运行工作流模块对应的容器镜像;
若否,则从容器镜像数据库拉取相应容器镜像至本地,启动容器;
若是,则基于预设启动策略启动容器。
进一步地,所述运行单元还用于:
确定待运行工作流模块的运行方式;
若为单机运行方式,则基于启动的容器执行待运行工作流模块的计算分析任务;
若为分布式运行方式,则基于从分布式资源管理中心获取的运行会话执行待运行工作流模块的计算分析任务。
进一步地,所述运行模块还包括:
数据传递单元,用于将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块。
进一步地,所述数据传递单元还用于:
将以单机方式运行成功的工作流模块的输出文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地读取;或,
将以单机方式运行成功的工作流模块的输出文件上传至分布式文件系统dfs,由具有串行关系且分布式运行的工作流模块以加载dfs文件的方式引用;或,
将以分布式方式运行成功的工作流模块输出的dfs文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地加载引用;或,
将以分布式方式运行成功的工作流模块输出的分布式数据资源标识传递给具有串行关系且分布式运行的工作流模块。
进一步地,所述数据分析系统还包括:
分步运行模块,用于对数据分析工作流进行分步运行。
进一步地,若所述工作流模块为分布式运行方式,所述分步运行模块还用于:
基于检测到的预设启动参数,将当前运行引擎切换至分步运行模式;
捕获并记录分布式工作流模块的运行日志,输出为可查看的日志文件;
将工作流模块的输出文件由分布式存储转换为本地存储。
进一步地,所述工作流模块包括数据模块,所述数据模块中数据文件的格式包括下述至少之一:txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式。
进一步地,所述数据分析系统还包括新建模块,用于:
确定数据接入类型;
基于数据接入类型确定数据的统一资源标识uri;
配置待接入数据文件的文件格式。
进一步地,所述数据分析系统还包括:
显示模块,用于基于检测到的针对数据模块的预览或分析操作,显示对应的可视化信息。
进一步地,所述显示模块包括:
获取单元,用于获取选择的数据接入类型;
第一加载单元,用于根据所述数据接入类型以预设模式加载数据文件;
展示单元,用于基于预设条件对加载的数据文件进行筛选或分析,并将筛选结果或分析结果进行可视化展示。
进一步地,所述第一加载单元还用于:
当接入数据为本地文件时,以本地模式启动计算引擎spark组件线程加载本地数据文件;
当接入数据为dfs文件时,启动分布式集群上的spark组件服务加载数据文件。
进一步地,所述工作流模块包括分析模块,所述多于一个的分析模块基于两种以上的开发语言分别创建,所述数据分析系统还包括创建模块,用于:
基于选择的开发语言使用对应的容器镜像创建所述分析模块。
进一步地,所述创建模块还用于定制各开发语言的容器镜像。
进一步地,所述创建模块还用于:
针对各发语言定制其运行时环境、日志监控服务、语言开发基础库,并封装成预设格式的容器镜像;
构建容器镜像与开发语言的一一映射关系。
进一步地,所述创建模块还用于设置分析模块进行数据输入/输出的数据格式。
进一步地,所述创建模块还用于:
基于选择的开发语言引用容器镜像内部预置的算法框架创建所述分析模块;或,
基于选择的开发语言对应的语言扩展包中包含的算法框架创建所述分析模块。
进一步地,所述数据分析系统,还包括:
模型生成模块,用于生成预设格式的算法模型,所述算法模型的格式包括pkl格式、预测模型标记语言pmml格式、h5格式中的至少之一。
进一步地,所述数据分析系统,还包括:
评估模块,用于对生成的算法模型进行评估。
进一步地,所述评估模块包括:
识别单元,用于识别算法模型的格式;
第二加载单元,用于根据算法模型的格式加载所述算法模型;
类别判定单元,用于判定所述算法模型的类别;
评估单元,用于根据所述算法模型的类别使用对应的评估指标进行评估。
进一步地,所述评估模块,还包括:
存储单元,用于对算法模型的各评估指标的分数和算法模型信息进行存储。
进一步地,所述算法模型的类别包括下述至少之一:聚类、分类、回归、异常检测及语言处理。
进一步地,所述数据分析系统,还包括:
模型发布模块,用于对评估后的算法模型进行发布。
进一步地,所述模型发布模块包括:
筛选单元,用于基于算法模型的各评估指标的分数筛选待发布算法模型;
模型发布单元,用于对筛选出的待发布算法模型进行发布。
进一步地,所述模型发布单元还用于:
识别待发布算法模型的格式;
确定模型服务的部署策略和调用方式;
构建模型服务镜像,并基于所述部署策略申请发布资源;
基于申请到的发布资源运行所述模型服务镜像,按照识别的格式解析所述待发布算法模型,并按照确定的调用方式提供应用发布的算法模型的接口。
进一步地,所述模型服务的调用方式包括超文本传输协议-表述行状态转移http-rest接口调用、消息队列mq调用、及批处理batch调用中的至少一种。
本发明还提出一种数据分析系统,该数据分析系统包括存储器、处理器及存储于所述存储器并可在所述处理器上执行的数据分析工作流运行程序,所述数据分析工作流运行程序被所述处理器执行时实现如上所述的数据分析工作流的运行方法的步骤。
本发明还提出一种存储介质,该存储介质存储有计算机程序,所述计算机程序被执行时实现如上所述的数据分析工作流的运行方法的步骤。
本发明的上述技术方案的有益效果如下:
本发明实施例中,根据获取的数据分析工作流的配置信息,确定数据分析工作流的各工作流模块的运行方式,并确定工作流模块之间的关联关系,最后基于确定的关联关系及运行方式运行所述数据分析工作流,通过确定各工作流模块的运行方式及其之间的关联关系,使得数据分析工作流灵活地以单机和/或分布式方式运行,实现了灵活配置资源消耗与数据分析之间的精细平衡,提高了数据分析系统的效率。
附图说明
图1为本发明数据分析工作流的运行方法第一实施例的流程图;
图2为本发明数据分析工作流的运行方法第二实施例的流程图;
图3为本发明数据分析工作流运行方式示意图;
图4为图2中步骤s41的流程示意图;
图5为本发明数据分析工作流的数据流示意图;
图6为本发明数据分析工作流分布运行示意图;
图7为本发明数据分析工作流各模块间输入输出关系示意图;
图8为本发明数据分析工作流的运行方法第三实施例的流程图;
图9为本发明数据分析系统一实施例的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
本发明提出一种数据分析工作流的运行方法。
本发明中的数据分析工作流用于数据分析处理。该数据分析工作流包括多于一个的工作流模块,各个工作流模块之间具有关联关系。所述关联关系包括串行关系和并行关系,具有串行关系的两个工作流模块中,一个工作流模块的输出作为另一个工作流模块的输入,该输出可以是数据、算法模型等;具有并行关系的两个工作流模块可以同时开始运行。当采用连线表示工作流模块之间具有关联关系时,多个工作流模块的关联关系可以类似于树形拓扑结构。所述工作流模块包括分析模块(代码模块),进一步的还可以包括数据模块。
本发明实施例中的容器(container)是引用程序的隔离和封装装置,是指包含最小化操作系统的环境隔离装置,用于封装应用程序,进一步的,容器是代码模块的载体。本发明实施例中的容器可以是下述任意一种:docker、pouch、k8s(kubernetes)container、mesoscontainer或yarncontainer。上述k8s(kubernetes)、mesos或yarn属于资源管理框架(容器管理器或者是容器服务器);上述docker、pouch、k8s(kubernetes)container、mesoscontainer、yarncontainer属于容器。
本发明中的运行引擎如无特别说明,均指代数据分析工作流运行引擎,也即数据分析系统的运行引擎。
本发明中的容器实例指具体某一个容器,一分析模块一般对应一个容器实例。本发明中的数据分析工作流对应多于一个的容器实例。
参照图1,图1为本发明的数据分析工作流的运行方法第一实施例的流程图。
在该实施例中,所述数据分析工作流的运行方法包括以下步骤:
s10:获取数据分析工作流的配置信息;
s20:根据所述配置信息确定各工作流模块的运行方式;
s30:确定工作流模块之间的关联关系;
s40:基于确定的关联关系及运行方式运行所述数据分析工作流。
本发明实施例的数据分析工作流的运行方法,通过获取的数据分析工作流的配置信息,确定数据分析工作流的各工作流模块的运行方式,如根据各工作流模块的版本(所述工作流模块的版本一般指基于某一种开发语言开发的代码模块的更新/迭代版本)、开发语言、标识等配置信息可以确定各工作流模块是单机运行还是分布式运行,接着根据各工作流模块的输入输出关系确定各工作流模块之间的关联关系,确定各工作流模块的运行顺序,使得数据分析工作流能够按照确定的关联关系及运行方式运行,解决了现有数据分析系统只能以单机或分布式方式择一运行造成的资源消耗大、效率低的技术问题,提高了数据分析系统的效率。具体的,所述配置信息包括下述至少之一:工作流模块的版本、开发语言、标识、创建人、创建日期、数据输入方式、输入数据格式、输入数据量、输出信息,计算资源负载状态,分析模块中算法的迭代次数,分析模块中算法的运算量。
进一步参照图2,在图2所示的实施例中,步骤s40包括:
s41:基于确定的并行/串行关系,以单机或分布式方式运行所述各工作流模块。
在本实施例中,实现工作流模块的单机或分布式运行,以及实现工作流模块之间的串行运行或并行运行,涉及到数据分析工作流中各工作流模块的标识识别、并行/串行关系推导。具体的,由数据分析工作流运行引擎加载所有工作流模块的基本信息,以此来获取数据分析工作流的配置信息。
数据分析工作流运行时,具有串行关系的下游模块需要依赖上游模块的输出作为数据输入,因而可以根据工作流模块的输入输出依赖关系确定工作流模块之间的关联关系,所述输入输出依赖关系可根据用户输入的工作流模块之间连线的箭头指向进行识别,本发明中的串行关系可以是具有输入输出依赖关系,本发明中的并行关系可以看作是无输入输出依赖关系。在其他实施例中,所述数据分析工作流的配置信息也可以包括所述输入输出依赖关系。基于确定的工作流模块之间的串行/并行关系,可以确定各工作流模块的运行顺序,以便在运行所述数据分析工作流时,按照各工作流模块的运行顺序及运行方式单机运行或分布式运行各个工作流模块。如图3所示,工作流模块a、b、e为顺序执行,工作流模块a、c、d为顺序执行;工作流模块b、c之间,工作流模块e、d之间均为并行执行。实线框为分布式运行的工作流模块(以分析模块为例),虚线框为单机运行的工作流模块(以分析模块为例)。
由于在创建工作流模块时,此时的工作流模块仅指分析模块,可以对基于不同开发语言创建的分析模块进行标识,因而可以基于各分析模块的标识和/或开发语言确定各分析模块为单机运行或分布式运行。分析模块的单机运行和分布式运行使用的开发语言有明显区别。为支持分布式运行,需使用编程语言的分布式版本,分布式版本和单机版本引用的编程语言库不同,因此分析模块不同运行方式版本只需在容器镜像集成相应的语言库,设置对应的运行时(runtime)组件即可。所述容器镜像一般指容器的模板,运行中的容器镜像构成容器;本实施例中的容器镜像具体为代码编译、运行、调试的集成环境的静态封装。所述runtime组件用于为应用程序运行的时候提供获取或保存容器系统状态所需要的支撑服务。因此使用不同运行方式的分析模块可通过容器镜像来区分。所述容器优选采用docker应用容器引擎技术,在容器的os(operatingsystem)管理系统的上一层提供一层runtime运行时以便code代码可以调用os相关信息和输入输出管理。分析模块的语言版本、单机运行或分布式运行等信息可以在创建分析模块时作为模块配置信息写到存储单元中。所述存储单元可以是san(storageareanetwork,存储区域网络)、nas(networkattachedstorage,网络附加存储)、nfs(networkfilesystem,网络文件系统)、或对象存储系统。
在本发明的另一实施例中,也可以基于数据模块的数据接入方式、数据格式、数据量大小,计算资源负载状态信息,以及分析模块中算法的计算复杂程度,由系统智能选择分析模块的运行方式(单机运行或分布式运行)。计算资源包括单机运行及分布式运行的当前排队情况,所述计算资源负载状态信息包括单机集群负载情况和分布式集群负载情况。所述计算复杂程度包括但不限于算法的迭代次数、算法的运算量。当然也可以基于上游分析模块输出的数据类别、数据格式、数据量、分析模块中算法的计算复杂程度等确定分析模块的运行方式。如当数据接入方式为hadoop分布式文件系统hdfs文件或分布式数据库hive表,数据量为2t,分布式平台当前有可用计算资源,分析模块算法迭代次数较多、运算量较大,系统智能判断采用分布式运行该分析模块;当数据接入方式为本地文件,数据量为1g,单机计算集群当前有可用计算资源,计算复杂程度一般,系统智能判断采用单机运行该分析模块。
本发明通过确定各工作流模块的运行方式及其之间的关联关系,使得数据分析工作流灵活地以单机和/或分布式方式运行,实现了灵活配置资源消耗与数据分析之间的精细平衡,打通了小数据集单机概念验证与大数据集分布式工程训练间的多层工程壁垒,支撑从原始数据到模型服务工程化的全过程,提高了数据分析系统的效率。
进一步地,参照图4,基于上述实施例的数据分析工作流的运行方法,步骤s41,包括:
s411:基于确定的并行/串行关系,确定待运行工作流模块;
s412:向本地资源管理中心提交资源运行申请;
s413:基于申请到的运行资源对待运行工作流模块进行容器实例部署;
s414:基于部署的容器实例运行所述待运行工作流模块。
在本实施例中,根据各工作流模块之间的输入输出依赖关系确定各工作流模块之间的并行/串行关系,所述输入输出依赖关系根据各工作流模块之间的箭头方向进行识别,存在依赖关系的工作流模块串行运行,无输入输出依赖关系的工作流模块可并行运行。因而可以根据确定的并行/串行关系确定数据分析工作流中的待运行工作流模块,也即当一个工作流模块不存在输入输出依赖关系或所依赖的工作流模块已运行完毕,则可以确定该工作流模块为待运行工作流模块,可进一步向本地资源管理中心提交资源运行申请。该申请可由运行引擎(如controller组件)提交到本地的容器资源管理中心(如mesos或kubernetes)。具体的,本地资源管理中心监控当前各节点的可用资源数量;当资源不足时,该申请进入排队等待状态;如资源可用,则本地资源管理中心会将运行该待运行工作流模块的容器实例部署到可用资源较多的节点,如各节点可用资源数量相同,则依照预置的部署策略进行部署。所述容器实例为具体运行一工作流模块(分析模块)的容器。
具体部署过程包括:容器引擎接收本地资源管理中心发起的容器启动请求,容器引擎基于待运行工作流模块的容器镜像启动容器。所述容器引擎可以是docker服务。在接收到所述容器启动请求后,容器引擎检查本地是否存在与待运行工作流模块对应的容器镜像;如果不存在对应的容器镜像,则从容器镜像数据库拉取相应容器镜像至本地,所述拉取表示从数据库到本地的下载动作;如果存在对应的容器镜像,则基于预设启动策略启动容器,所述预设启动策略可以是用户自定义的任一启动策略。
进一步地,在基于部署的容器实例运行所述待运行工作流模块时,还需要确定待运行工作流模块的运行方式;若为单机运行方式,则基于启动的容器执行待运行工作流模块的计算分析任务,也即将运行待运行工作流模块的容器实例根据本地资源使用情况,部署到资源可用的节点,并在启动的容器内执行相应的计算分析任务;若为分布式运行方式,则除了在本地资源管理中心获取运行资源部署容器实例之外,还基于从分布式资源管理中心获取的运行会话执行待运行工作流模块的计算分析任务。具体的,在确定所述待运行工作流模块为分布式运行时,在向本地资源管理中心提交资源运行申请之外,还向分布式资源管理中心(如spark)提交资源申请,资源不足则排队等待,资源可用则获取一运行会话(sparksession,从数据分析工作流开始到结束的整个过程及其各种支撑服务),并使用该运行会话执行计算分析任务,进一步的,当下游工作流模块仍为分布式运行时,保留该运行会话,以节省资源申请时间,同时可直接引用已运行工作流模块的输出文件(数据或模型),极大地提高了运行效率。
进一步地,步骤s414之后,还包括:对运行失败的工作流模块进行代码编译运行调试。具体的,在执行完相应的计算分析任务后,容器结束,本地资源管理中心释放资源。如果该工作流模块运行成功,数据分析工作流继续执行其他可执行的工作流模块,如与该工作流模块有串行关系的下游模块。如果该工作流模块运行失败,后续待处理的数据已经异常,继续运行已无意义,为避免工作流在下次运行失败,可以对运行失败的工作流模块进行代码编译运行调试,极大地提高了工作流模块的开发效率。
进一步地,数据分析系统可同时运行两个或两个以上的数据分析工作流,为保证各个数据分析工作流之间程序与数据隔离,以避免工作流运行紊乱、内容异常。本发明实施例还对数据分析工作流采取以下方式进行隔离:运行空间隔离,每个数据分析工作流去本地资源管理中心申请新的资源空间,该数据分析工作流内分析模块运行时均在该资源空间内运行,资源空间之间相互隔离,以保证不同数据分析工作流的程序隔离;数据空间隔离,每个数据分析工作流启动运行后,运行引擎会创建新的目录,该目录与数据分析工作流一一对应,数据分析工作流内各工作流模块之间的数据传递使用相对引用路径,且运行引擎会检查访问路径,排除绝对路径引用,最后由运行引擎根据数据库记录的工作流模块间的依赖关系,获取到依赖的工作流模块的输出文件的名称,通过该名称使用相对路径访问当前目录文件,从而实现数据隔离。
进一步地,在步骤s414之后,还包括:
s415:将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块。
为支持工作流模块间的数据流(输出文件)根据工作流模块的运行方式自适应切换格式,数据分析工作流运行引擎要在能准确识别工作流模块运行方式的前提下,实现多场景自适应。如图5所示,将数据源封装成数据模块(图中方框),在数据分析工作流中使用合适的分析模块(图中圆角框)加载,并将结果传递给下个分析模块,该过程可能重复多次。该图概括描述了数据分析工作流中数据流的传递过程。数据的加载一般根据数据模块的特点选取相应的加载模块,因此加载过程和方法相对固定,如本地文件适合由单机运行的加载模块进行加载,分布式文件系统文件(如hive表、hdfs文件)存储于分布式集群、数据量较大,适合由分布式运行的加载模块进行加载。进一步的,因数据格式、数据量、分析处理方法及运算量等原因,后续过程可能会混合使用单机和分布式两种运行方式,对应的数据流(输出文件)的数据存储方式也会多次变化。具体如下:
场景一:将以单机方式运行成功的工作流模块的输出文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地读取。本场景对应单机处理到单机处理。单机运行的工作流模块在运行时引用数据的方式为加载本地文件,当上游模块为单机运行模块时,输出存储为本地文件,具有串行关系的单机运行的工作流模块直接从本地读取该本地文件即可。
场景二:将以单机方式运行成功的工作流模块的输出文件上传至分布式文件系统dfs,由具有串行关系且分布式运行的工作流模块以加载dfs文件的方式引用。本场景对应单机处理到分布式处理。分布式运行的工作流模块在运行时引用数据的方式为使用二维数据结构数据框dataframe(df)引用(资源标识)、数据集dataset(ds)引用(资源标识)、或hdfs文件。当上游模块为单机运行模块时,没有dataframe(df)引用(资源标识)或dataset(ds)引用(资源标识),运行引擎自动将本地文件上传至hdfs,以保证具有串行关系的分布式运行的工作流模块以加载dfs文件的方式,无差别地直接引用该数据流。
场景三:将以分布式方式运行成功的工作流模块输出的dfs文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地加载引用。本场景对应分布式处理到单机处理。单机运行的工作流模块在运行时引用数据的方式为加载本地文件。当上游模块为分布式运行模块时,可输出的文件格式为dataframe(df)引用(资源标识)、dataset(ds)引用(资源标识)、或hdfs文件,具有串行关系的单机运行模块无法引用dataframe(df)引用(资源标识)或dataset(ds)引用(资源标识),因此运行引擎自动将hdfs文件下载到本地文件系统,保证该单机运行模块可以加载本地文件的方式,无差别引用该数据流。
场景四:将以分布式方式运行成功的工作流模块输出的分布式数据资源标识传递给具有串行关系且分布式运行的工作流模块。本场景对应分布式处理到分布式处理。上游模块可提供dataframe(df)引用(资源标识)、dataset(ds)引用(资源标识)、或hdfs文件,都可被具有串行关系的分布式运行的本工作流模块使用。但上游模块重新存储到hdfs和本分布运行模块读取hdfs文件都需要耗费较大时间,所以运行引擎优选将上游模块输出的dataframe(df)引用(资源标识)或dataset(ds)引用(资源标识)直接传递给分布运行模块,从而提高工作流的效率,此时各工作流模块在同一个运行会话,极大地提高了数据分析工作流的运行效率。
进一步地,在数据分析工作流中的分析模块较多,各分析模块运行方式不同,数据量较大时,如对某一分析模块进行调试运行时,都需要完整运行整个工作流,会浪费较多的时间和运行资源,因而本发明实施例还支持分步运行数据分析工作流,也即该数据分析工作流的运行方法还可以包括:对数据分析工作流进行分步运行。
参照图6,对数据分析工作流进行分布运行,具体包括:①基于检测到的作用于所述工作流模块的第一预设操作,从第一指定工作流模块开始运行数据分析工作流。如图6,从分析模块6开始运行该数据分析工作流时,运行分析模块6、8、11、12、且分析模块10依赖的其他分支所有节点也运行,即执行分析模块6、8、0、2、5、7、9、10、11、12,如从分析模块11运行该工作流,则只会运行分析模块11、12。②基于检测到的作用于所述工作流模块的第二预设操作,控制数据分析工作流运行至第二指定工作流模块。如图6,控制数据分析工作流运行至分析模块6时,只运行与分析模块具有串行关系的上游模块0、1、3、4、6。③基于检测到的作用于所述工作流模块的第三预设操作,运行数据分析工作流中的第三指定工作流模块。如图6,运行指定分析模块6时,则只会运行该分析模块6。④基于检测到的作用于所述工作流模块的第四预设操作,控制数据分析工作流从第四指定工作流模块运行至第五指定工作流模块。如指定分析模块2为起点、分析模块9为终点运行该工作流时,只会运行模块2、5、7、9,如指定分析模块6为起点、10为终点,则会运行分析模块6、8、0、2、5、7、9、10。
由于在数据分析工作流的各工作流模块均为单机运行模块时,模块间数据流的传递通过本地文件实现,运行完毕可以进行查看结果和日志,可以满足工作流的分步运行。但分析模块在分布式运行时,输出的文件和运行信息(运行上下文)均在分布式集群,不能直接满足分步运行需求,因而为支持多运行方式的工作流分步运行,需要每个分布式或单机运行的分析模块的输出都可进行保存和查看。具体需要由工作流运行引擎基于检测到的预设启动参数,将当前运行引擎切换至分步运行模式;运行引擎在分步运行模式下,捕获并记录每个分布式运行的分析模块的运行日志,输出为可查看的日志文件;将分析模块的输出文件由分布式存储转换为本地存储,保证分析模块的输出可被查看、下载、引用。本发明实施例通过支持数据分析工作流的分步运行,提升了工作流模块特别是分析模块的开发效率。
进一步地,所述数据分析工作流中的工作流模块包括数据模块,所述数据模块中数据文件的格式包括下述至少之一:txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式。本实施例中的数据模块支持多类型数据接入,包括但不限于:本地文件、hdfs文件及hive表;其中,所述本地文件包括txt文本、csv文本、tsv文本、图像文件、音频文件;所述hdfs文件包括txt文本、csv文本、tsv文本、图像文件、音频文件、parquet压缩文件、orc文本文件、序列化文件sequencefile格式文件。
在运行数据分析工作流之前,需要基于数据模块和分析模块构建数据分析工作流,所述数据模块可以直接调用数据分析系统中的已有数据模块,当然在数据分析系统中无可用的数据模块时,还需要新建数据模块。
具体地,由于数据的格式多种多样,为保证新建的数据模块能够被大范围引用,在新建数据模块时,需要:①确定数据接入类型,可以基于用户选择或系统默认确定数据的接入类型为本地文件、hdfs文件或hive表中之一;②基于数据接入类型确定数据的统一资源标识uri;③配置待接入数据文件的文件格式,可以基于用户选择配置,也可以由系统自动识别接入的数据文件属于txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式中之一,进一步还可以根据数据接入类型及文件格式配置下述至少之一:列分隔符,行分隔符,编码格式及是否将首行作为列名;④在接收到保存指令时,根据系统预置操作保存所述数据接入类型、数据的uri、文件格式,数据模块新建完成。通过前述步骤完成数据模块的新建后,所述数据模块信息会以只读方式存储,如存储至数据库,该数据模块信息不可修改,且实际标识的数据文件也只能以只读方式进行引用,保证多次引用该数据模块时的可用性和安全性。
进一步地,在基于数据接入类型确定数据的uri时,具体包括:当接入数据为本地文件时,将接入数据上传至本地存储,并将本地存储路径确定为数据的uri;当接入数据为hdfs文件时,对hdfs文件的指定路径进行验证,并将验证成功的hdfs路径确定为数据的uri;当接入数据为hive表时,对hive表的指定库进行验证,并将验证成功的hive表路径确定为数据的uri。
进一步地,本发明实施例还能够实现多格式数据图形化预览和分析统计,也即可以基于检测到的预览或分析操作,显示对应的可视化信息。具体包括:
获取选择的数据接入类型;
根据所述数据接入类型以预设模式加载数据文件,当接入数据为本地文件时,以本地模式启动计算引擎spark组件线程加载本地数据文件,当接入数据为dfs文件时,启动分布式集群上的spark组件服务加载数据文件;
基于预设条件对加载的数据文件进行筛选或分析,并将筛选结果或分析结果进行可视化展示。如读取加载文件的前100行并发送给页面展示,或,随机抽取1万行数据或者加载10m大小数据作为统计样本,假如数据大小小于上述条件则整个文件都作为统计样本,统计样本中各项指标,包括但不限于按类别统计:有效值、唯一值、空值3项指标的绝对数量和百分比,按数值统计:最大值、最小值、平均值、中位数、总和等等。特别的,对加载文件进行可视化展示时,针对不同场景(不同的数据接入方式、不同的格式)都使用spark组件加载数据,以使用同样的代码实现上述数据预览分析等功能,不需要重复开发代码,且展示效果一致。本实施例可快速直观预览数据模块中的数据及统计结果,高效率完成数据可用性评估,且通过模块化的封装复用,大幅提升了数据探查及数据引用效率。
进一步地,所述工作流模块包括分析模块,多于一个的分析模块基于两种以上的开发语言分别创建,创建分析模块的步骤,包括:
定制各开发语言的容器镜像;
基于选择的开发语言使用对应的容器镜像创建所述分析模块。
所述定制各开发语言的容器镜像的步骤,包括:
针对各发语言定制其运行时环境、日志监控服务、语言开发基础库,并封装成预设格式的容器镜像;
构建容器镜像与开发语言的一一映射关系。
本发明实施例的数据分析工作流中的多于一个的分析模块基于两种以上的开发语言分别创建,具体的,具有并行/串行关系的工作流模块使用不同的开发语言分别创建。优选地,所述开发语言包括:r、sparkr(r分布式版本)、python、pyspark(python分布式版本)、sql、scala。如具有串行关系的上游工作流模块采用r开发语言进行创建,依赖该上游工作流模块输出的下游模块可以采用python开发语言进行创建,也可以采用sparkr开发语言进行创建。为支持多语言编程开发,需要定制各开发语言的容器镜像,也即定制各开发语言进行编译、运行、调试的集成环境的静态封装。所述容器镜像,包含代码编辑器功能:代码编辑,关键字高亮,行号显示,注释变色显示,缩进对齐,代码文件目录显示,代码版本管理,运行参数定义,输入输出定义;容器镜像还包括代码调试器功能:调试/测试文件选择,文件调试,文件测试,调试/测试停止,调试日志显示,运行参数输入,代码输入输出选择,容器当前状态显示,启动容器,停止容器。
为支持分析模块的多语言开发,针对各开发语言定制其编译运行调试的集成环境,包括运行时环境、日志监控服务、语言开发基础库,并封装成格式统一的模板,具体为容器化技术的镜像,也即容器镜像,并构建容器镜像与开发语言的一一映射关系,不同的开发语言对应的容器镜像不同。当选择某个开发语言进行创建分析模块时,使用对应的容器镜像即可。所述运行时环境指能够运行数据分析工作流的数据分析系统的寄存器以及存储器的结构,用来管理并保存指导执行过程所需的信息。
进一步地,为支持多语言调试,在创建分析模块时还支持:
对创建的所述分析模块进行调试。
所述对创建的所述分析模块进行调试的步骤,包括:
基于容器镜像内置的日志监控服务获取程序全部日志;
将所述全部日志显示于页面日志显示区,以供调试。
为方便对创建的分析模块进行调试,需支持参数调试并提供完整的、实时的日志。具体可在容器镜像内预置日志监控服务(容器镜像内置系统服务),该服务在容器启动时随容器启动,作为容器的系统级服务在容器存活期间一直运行,在程序运行时,日志监控服务将参数(代码参数)以程序启动参数方式传递给程序,并捕获程序全部日志,并将日志全部、无改动、实时的传递到页面日志显示区,使开发人员对程序的运行过程完全掌握,提高开发人员的效率。
进一步地,为保证代码多次稳定运行,需要调试环境和实际运行环境完全一致,且多次运行环境不变。运行环境包括:配置(例如库文件版本、运行库文件的个数、依赖的服务的个数和服务的属性),程序运行需要的库文件,字符集,资源(例如网络资源、存储资源)等。具体可通过容器化技术保证调试环境和运行环境一致。调试成功后(即运行后的输出达到预期效果),通过容器实例提交容器镜像,因而使用容器镜像启动容器即可完全还原调试运行环境。而且每次容器运行环境都基于此容器镜像启动,保证了多次运行环境的一致性。
进一步地,在创建分析模块时,还可以选择分析模块进行数据输入/输出的数据格式。进一步地,在分析模块创建完成之后,还可以调整分析模块的输入/输出数据格式。
本发明实施例中,数据分析工作流运行引擎和容器化的运行环境支持的数据存储规范已经支持20余种数据格式,并可弹性扩充,目前包括但不限于csv、txt、tsv、pdf、html、json、pkl、pmml、h5、dataset(ds)、parquet、orc、rds等。在创建分析模块时,系统默认每一分析模块的输入输出均有一个通用的数据格式,用户也可以选择分析模块的输入输出数据格式,以保证不同分析模块间数据传递的准确性、可用性、一致性、复用性。如图7,数据分析工作流中包含分析模块a、b、c、d、e等,在其他实施例中,分析模块a也可以是数据模块,每一分析模块会有输入/输出。为保证数据传递的准确性:模块c的输出1输至模块d的输入2,也不是模块d的输入1。为保证数据传递的可用性:模块c的输出1格式必须和模块d的输入2的格式相同,保证模块2可正常解析。为保证数据传递的一致性:模块c的输出1必须和模块d的输入2完全一致,输出的数据不允许做任何改动。为保证数据传递的复用性:模块c的输出1可同时输出到模块d的输入2和模块e的输入1,可多模块使用。同一连线上的数据需要统一数据格式,不同连线可以不同。
本发明实施例的数据分析工作流的所有特性通过运行引擎和容器化技术来实现,运行引擎将分析模块的所有输出/输入进行详细记录,包括输入/输出数据格式、对应连接模块标识id,连接的输出/输入标识id,并根据这些信息自动推断分析模块间的依赖关系及运行顺序。如模块b/c只依赖模块a,模块d依赖模块b和模块c。通过模块id和输入/输出id,运行引擎可保证数据传递的准确性。通过输入输出数据格式信息,运行引擎可配合有数据输出的分析模块的容器化运行环境,将输出数据按照指定格式写入到运行引擎的存储服务,并设置该数据为只读,防止被篡改和删除。运行输入数据的分析模块时,运行引擎又配合输入数据的分析模块的容器化运行环境将数据从存储空间读入,并使用同样的格式规范对数据进行了解析,以此保证数据传递的可用性和一致性。运行引擎根据分析模块间依赖关系会允许所有依赖该输出的分析模块读取该输出数据,因此多个依赖该输出的分析模块均有读取权限,以此保证数据的复用性。
本发明实施例中的分析模块支持两种以上的开发语言进行分别创建,能够充分利用各开发语言的特性,实现协同处理,极大提升了开发效率和灵活性,方便复用各开发语言已有成果,并集中管理。
进一步地,为提高分析模块的开发效率,本发明实施例支持多种算法框架来创建分析模块,具体可以是:
①基于选择的开发语言引用容器镜像内部预置的算法框架创建所述分析模块。在创建分析模块时,分析模块对应的容器镜像内预置了预设数量的算法框架,如内置了python语言支持的sklearn、tensorflow、caffe、mxnet、keras、h2o、theano等算法框架;r语言支持的rpart、neuralnet、c50、nbclust、svm等算法框架;scala语言支持的sparkml(sparpk机器学习框架)算法框架。基于所选语言支持的算法框架,用户在创建分析模块时无需手动安装扩展包,即可直接使用对应框架,例如用代码进行引用。
②基于选择的开发语言对应的语言扩展包中包含的算法框架创建所述分析模块。本发明实施例集成了现有主流机器学习语言r、python、sql、scala等的扩展包(package)仓库(库文件),仓库包含对应语言的几乎所有扩展包,所述算法框架包含在扩展包中。用户还可以在创建分析模块的过程中使用系统内置自定义扩展包仓库中的任何扩展包。安装所述扩展包后(可以安装于容器镜像内),即可直接使用对应框架,例如用代码进行引用。
进一步地,为支持数据分析工作流可运行多种算法框架,需要保证:①单个框架的运行环境完整性,所述运行环境包括:配置(例如库文件版本、运行库文件的个数、依赖的服务个数和服务属性),程序运行需要的库文件,字符集,资源(例如网络资源、存储资源)等,即在构建数据分析工作流时,算法框架的所有环境依赖是完整的、正确的。本发明实施例通过容器化技术,用调试完毕的容器镜像保证框架的依赖完整。②多个算法框架的兼容性,即多个算法框架间不会有运行环境的冲突。本发明实施例的容器间是相互隔离的,每个容器和其他容器互不干扰,不存在兼容冲突③算法框架间数据的规范性,由运行引擎和容器化运行环境支持的数据存储规范保证。
本发明实施例的数据分析工作流支持多种算法框架,便于开发人员使用多种算法框架的丰富算法库和工具类,提高编码效率和模型训练效率,而且多种算法框架之间无缝整合,便于开发人员挑选更优方案。
进一步地,参照图8,基于上述实施例的数据分析工作流的运行方法,图示实施例的运行方法还包括:
s50:生成预设格式的算法模型。
基于容器化技术及容器的运行时环境具备强大的兼容及定制能力,本发明实施例的算法模型支持pkl格式、预测模型标记语言pmml格式、h5格式中的至少之一。
进一步地,所述生成预设格式的算法模型的步骤,包括:
基于python语言的序列化标准pickle,将具有串行运行关系的工作流模块的模型对象(算法模型文件)通过序列化的pkl文件进行传递;
在所述数据分析工作流运行成功时,生成pkl格式的算法模型。
为支持pkl格式的算法模型,①容器运行时环境集成python语言的序列化标准pickle,将各工作流模块的模型对象序列化后存为pkl文件;②具有串行关系的下游模块加载pkl文件并反序列化还原模型对象;③依照上述方式保证工作流模块间通过pkl文件传递。
进一步地,所述生成预设格式的算法模型的步骤,包括:
基于标记语言标准pmml使用pipeline对运行工作流模块生成的对象进行封装;
基于自定义json格式将各工作流模块的pipeline信息写入输出文件,形成json文件;
在所述数据分析工作流运行成功时,将所述json文件解析为多条pipeline信息,对所述pipeline信息进行整合、转换处理,生成pmml格式的算法模型。
为支持pmml格式的算法模型,①容器运行时环境集成聚类、分类、回归、异常检测及语言处理等模型标记语言标准pmml,将模型训练生成的过程信息用pipeline对象封装;②将各模块的pipeline信息用自定义json格式写入到输出文件,如果有输入的json文件,追加至输入的json文件中再输出;③在工作流运行成功时,由模型输出模块将输入的json文件解析为多条pipeline信息,并按顺序整合,转换为pmml算法模型输出。
进一步地,所述生成预设格式的算法模型的步骤,包括:
基于python语言的容器标准h5py及深度学习模型使用的keras+tensorflow/theano算法框架,将具有串行运行关系的工作流模块的模型对象通过序列化的h5文件进行传递;
在所述数据分析工作流运行成功时,生成h5格式的算法模型。
为支持h5格式的算法模型,①容器运行时环境集成python语言存储数据集的容器标准h5py,及深度学习模型使用的keras+tensorflow/theano框架,将神经网络结构定义、编译及训练参数等信息用h5格式封装(相当于封装为一个文件);②具有串行关系的下游模块加载h5文件反序列化还原模型对象;③依照上述方式保证工作流模块间通过h5文件传递。
进一步地,参照图8,基于上述实施例的数据分析工作流的运行方法,图示实施例的运行方法还包括:
s60:对生成的算法模型进行评估。
进一步地,所述对生成的算法模型进行评估的步骤,包括:
识别算法模型的格式;
根据算法模型的格式加载所述算法模型;
判定所述算法模型的类别;
根据所述算法模型的类别使用对应的评估指标进行评估;
对算法模型的各评估指标的分数和算法模型信息进行存储。
算法模型从定义到最终发布上线产生业务价值,需要经历模型构建、参数调整、模型训练、模型评估、模型筛选以及模型发布等。为保证发布最佳的算法模型,需要对生成的算法模型进行评估。所述算法模型根据目的不同可以分为预测和聚类两大类别,对应不同的业务场景,如识别信用卡客户群的聚类算法场景,预测客户流失、金融产品推荐预测的分类算法场景,预测保险理赔额度、现金备付的回归算法场景,识别欺诈、异常交易的异常检测场景,基于语义分析、词频分析的语言处理场景。因此需要不同的评估指标来判断模型的有效性和实用性。聚类模型基于silhouette(轮廓)系数、homogeneity(同质性)、completeness(完整性)、和/或v-measure进行评估。分类模型基于曲线下面积(areaunderthecurve,auc)、准确率、精确率、召回率、f1分数、和/或对数损失进行评估。回归模型基于解释差异分值、均值误差、均方误差、均方根误差、均方根对数误差、r2值、和/或绝对均值误差进行评估。异常检测模型基于曲线下面积(areaunderthecurve,auc)、准确率、精确率、召回率、f1分数、和/或对数损失进行评估。
为支持评估指标自适应,①通过对算法模型进行多格式自动解析,自动识别算法模型格式(模型自动解析只会匹配对应的真实格式,即pmml、pkl、h5其中一种);②根据算法模型格式,采用对应解析格式还原模型对象(算法模型文件),即加载算法模型,实现算法模型的具体功能;③根据算法模型的基本信息(模型创建时选择的格式、模型使用的算法)判定该算法模型属于聚类、分类、回归、异常检测、语言处理中的何种类别(此信息在模型创建阶段由用户选定或系统自动判断给出),如果基本信息为空,则从编码语言层面,根据模型对象所属类进行判定;④根据算法模型类别使用不同的评估指标进行评估;⑤将各指标得分及算法模型信息(模型创建时选择的格式、模型使用的算法、创建时间、创建人、更新时间等)存储,例如存储到数据库。
进一步地,参照图8,基于上述实施例的数据分析工作流的运行方法,图示实施例的运行方法还包括:
s70:对评估后的算法模型进行发布。
模型发布具体分为模型筛选和模型发布两个阶段,模型筛选即用评估阶段生成的各评估指标进行横向对比,筛选出符合业务场景、性能更好的算法模型;模型发布即解析模型,发布为可提供在线预测、聚类等功能的服务。因而,步骤s70,具体包括:
基于算法模型的各评估指标的分数筛选待发布算法模型;
对筛选出的待发布算法模型进行发布。
进一步地,所述对筛选出的待发布算法模型进行发布的步骤,包括:
识别待发布算法模型的格式;
确定模型服务的部署策略和调用方式;
构建模型服务镜像,并基于所述部署策略申请发布资源;
基于申请到的发布资源运行所述模型服务镜像,按照识别的格式解析所述待发布算法模型,并按照确定的调用方式提供应用发布的算法模型的接口。
为支持多格式的模型发布,①通过对算法模型进行多格式自动解析,自动识别算法模型的格式(模型自动解析只会匹配对应的真实格式,即pmml、pkl、h5其中一种);②确定模型服务的部署策略,即部署模型服务实例个数,每个服务实例使用资源的大小,所述部署策略可以由用户自定义设置,也可以是系统默认的部署策略;③确定模型服务的调用方式,可以是超文本传输协议-表述行状态转移http-rest接口调用、消息队列mq调用、及批处理batch调用中的至少一种,所述调用方式可以由用户选择,也可以由系统默认选定;④服务发布引擎使用算法模型文件及模型解析服务(数据分析系统的自身组件,用于智能识别模型格式)作为源文件构建模型服务镜像(预置了模型服务的镜像),如镜像构建失败则模型发布失败;⑤按照确定的部署策略,服务发布引擎向发布集群的资源管理中心申请资源,如资源不足则模型发布失败;⑥使用构建的模型服务镜像启动容器,按照识别的算法模型的格式解析算法模型文件,并按照确定的模型服务的调用方式,提供应用该发布的算法模型的接口,模型发布完成。
本发明对应所述数据分析工作流的运行方法,进一步提出一种数据分析系统,该数据分析系统用于运行数据分析工作流,该数据分析系统的实现方式参照上述数据分析工作流的运行方法的实现方式。
参照图9,图9为本发明的数据分析系统一实施例的结构示意图。
在该实施例中,所述数据分析系统100包括:
获取模块10,用于获取数据分析工作流的配置信息;
确定模块20,用于根据所述配置信息确定各工作流模块的运行方式;
所述确定模块20还用于确定工作流模块之间的关联关系;
运行模块30,用于基于确定的关联关系及运行方式运行所述数据分析工作流。
所述运行模块30可以是数据分析工作流运行引擎。
进一步地,所述关联关系包括并行/串行关系,所述运行模块30还用于基于确定的并行/串行关系,以单机或分布式方式运行所述各工作流模块。
进一步地,所述运行模块30包括:
确定单元31,用于基于确定的并行/串行关系,确定待运行工作流模块;
申请单元33,用于向本地资源管理中心提交资源运行申请;
部署单元35,用于基于申请到的运行资源对待运行工作流模块进行容器实例部署;
运行单元37,用于基于部署的容器实例运行所述待运行工作流模块。
进一步地,所述部署单元35用于:
接收本地资源管理中心发起的容器启动请求;
基于待运行工作流模块的容器镜像启动容器。
所述部署单元35可以是容器引擎。
进一步地,所述部署单元35还用于:
检查本地是否存在与待运行工作流模块对应的容器镜像;
若否,则从容器镜像数据库拉取相应容器镜像至本地,启动容器;
若是,则基于预设启动策略启动容器。
进一步地,所述运行单元37还用于:
确定待运行工作流模块的运行方式;
若为单机运行方式,则基于启动的容器执行待运行工作流模块的计算分析任务;
若为分布式运行方式,则基于从分布式资源管理中心获取的运行会话执行待运行工作流模块的计算分析任务。
进一步地,所述运行模块30还包括:
数据传递单元39,用于将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块。
进一步地,所述数据传递单元39还用于:
将以单机方式运行成功的工作流模块的输出文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地读取;或,
将以单机方式运行成功的工作流模块的输出文件上传至分布式文件系统dfs,由具有串行关系且分布式运行的工作流模块以加载dfs文件的方式引用;或,
将以分布式方式运行成功的工作流模块输出的dfs文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地加载引用;或,
将以分布式方式运行成功的工作流模块输出的分布式数据资源标识传递给具有串行关系且分布式运行的工作流模块。
进一步地,所述数据分析系统100还包括:
分步运行模块40,用于对数据分析工作流进行分步运行。
进一步地,若所述工作流模块为分布式运行方式,所述分步运行模块40还用于:
基于检测到的预设启动参数,将当前运行引擎切换至分步运行模式;
捕获并记录分布式工作流模块的运行日志,输出为可查看的日志文件;
将工作流模块的输出文件由分布式存储转换为本地存储。
进一步地,所述工作流模块包括数据模块,所述数据模块中数据文件的格式包括下述至少之一:txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式。
进一步地,所述数据分析系统100还包括新建模块50a,用于:
确定数据接入类型;
基于数据接入类型确定数据的统一资源标识uri;
配置待接入数据文件的文件格式。
进一步地,所述数据分析系统100还包括:
显示模块60,用于基于检测到的针对数据模块的预览或分析操作,显示对应的可视化信息。
进一步地,所述显示模块60包括:
获取单元61,用于获取选择的数据接入类型;
第一加载单元63,用于根据所述数据接入类型以预设模式加载数据文件;
展示单元65,用于基于预设条件对加载的数据文件进行筛选或分析,并将筛选结果或分析结果进行可视化展示。
进一步地,所述第一加载单元63还用于:
当接入数据为本地文件时,以本地模式启动计算引擎spark组件线程加载本地数据文件;
当接入数据为dfs文件时,启动分布式集群上的spark组件服务加载数据文件。
进一步地,所述工作流模块包括分析模块,多于一个的分析模块基于两种以上的开发语言分别创建,所述数据分析系统100还包括创建模块50b,用于:
基于选择的开发语言使用对应的容器镜像创建所述分析模块。
进一步地,所述创建模块50b还用于定制各开发语言的容器镜像。
进一步地,所述创建模块50b还用于:
针对各发语言定制其运行时环境、日志监控服务、语言开发基础库,并封装成预设格式的容器镜像;
构建容器镜像与开发语言的一一映射关系。
进一步地,所述创建模块50b还用于设置分析模块进行数据输入/输出的数据格式。
进一步地,所述创建模块50b还用于:
基于选择的开发语言引用容器镜像内部预置的算法框架创建所述分析模块;或,
基于选择的开发语言对应的语言扩展包中包含的算法框架创建所述分析模块。
进一步地,所述数据分析系统100,还包括:
模型生成模块70,用于生成预设格式的算法模型,所述算法模型的格式包括pkl格式、预测模型标记语言pmml格式、h5格式中的至少之一。
进一步地,所述数据分析系统100,还包括:
评估模块80,用于对生成的算法模型进行评估。
进一步地,所述评估模块80包括:
识别单元81,用于识别算法模型的格式;
第二加载单元83,用于根据算法模型的格式加载所述算法模型;
类别判定单元85,用于判定所述算法模型的类别;
评估单元87,用于根据所述算法模型的类别使用对应的评估指标进行评估。
进一步地,所述评估模块80,还包括:
存储单元89,用于对算法模型的各评估指标的分数和算法模型信息进行存储。
进一步地,所述算法模型的类别包括下述至少之一:聚类、分类、回归、异常检测及语言处理。
进一步地,所述数据分析系统100,还包括:
模型发布模块90,用于对评估后的算法模型进行发布。
进一步地,所述模型发布模块90包括:
筛选单元91,用于基于算法模型的各评估指标的分数筛选待发布算法模型;
模型发布单元93,用于对筛选出的待发布算法模型进行发布。
进一步地,所述模型发布单元93还用于:
识别待发布算法模型的格式;
确定模型服务的部署策略和调用方式;
构建模型服务镜像,并基于所述部署策略申请发布资源;
基于申请到的发布资源运行所述模型服务镜像,按照识别的格式解析所述待发布算法模型,并按照确定的调用方式提供应用该发布的算法模型的接口。
进一步地,所述模型服务的调用方式包括超文本传输协议-表述行状态转移http-rest接口调用、消息队列mq调用、及批处理batch调用中的至少一种。
本发明还提出一种数据分析系统,该数据分析系统包括存储器、处理器及存储于所述存储器并可在所述处理器上执行的数据分析工作流运行程序,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
获取数据分析工作流的配置信息;
根据所述配置信息确定各工作流模块的运行方式;
确定工作流模块之间的关联关系;
基于确定的关联关系及运行方式运行所述数据分析工作流。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:基于确定的并行/串行关系,以单机或分布式方式运行所述各工作流模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于确定的并行/串行关系,确定待运行工作流模块;
向本地资源管理中心提交资源运行申请;
基于申请到的运行资源对待运行工作流模块进行容器实例部署;
基于部署的容器实例运行所述待运行工作流模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
接收本地资源管理中心发起的容器启动请求;
容器引擎基于待运行工作流模块的容器镜像启动容器。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
检查本地是否存在与待运行工作流模块对应的容器镜像;
若否,则从容器镜像数据库拉取相应容器镜像至本地,以启动容器;
若是,则基于预设启动策略启动容器。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
确定待运行工作流模块的运行方式;
若为单机运行方式,则基于启动的容器执行待运行工作流模块的计算分析任务;
若为分布式运行方式,则基于从分布式资源管理中心获取的运行会话执行待运行工作流模块的计算分析任务。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
将运行成功的工作流模块的输出文件传递给具有串行关系的工作流模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
将以单机方式运行成功的工作流模块的输出文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地读取;或,
将以单机方式运行成功的工作流模块的输出文件上传至分布式文件系统dfs,由具有串行关系且分布式运行的工作流模块以加载dfs文件的方式引用;或,
将以分布式方式运行成功的工作流模块输出的dfs文件存储至本地,由具有串行关系且单机运行的工作流模块进行本地加载引用;或,
将以分布式方式运行成功的工作流模块输出的分布式数据资源标识传递给具有串行关系且分布式运行的工作流模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
对数据分析工作流进行分步运行。
进一步地,若所述工作流模块为分布式运行方式,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于检测到的预设启动参数,将当前运行引擎切换至分步运行模式;
捕获并记录分布式工作流模块的运行日志,输出为可查看的日志文件;
将工作流模块的输出文件由分布式存储转换为本地存储。
进一步地,所述工作流模块包括数据模块,所述数据模块中数据文件的格式包括下述至少之一:txt文本格式、csv文本格式、tsv文本格式、图像格式、音频格式、parquet存储格式、orc文件格式、序列化文件sequencefile格式。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
确定数据接入类型;
基于数据接入类型确定数据的统一资源标识uri;
配置待接入数据文件的文件格式。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于检测到的针对数据模块的预览或分析操作,显示对应的可视化信息。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
获取选择的数据接入类型;
根据所述数据接入类型以预设模式加载数据文件;
基于预设条件对加载的数据文件进行筛选或分析,并将筛选结果或分析结果进行可视化展示。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
当接入数据为本地文件时,以本地模式启动计算引擎spark组件线程加载本地数据文件;
当接入数据为dfs文件时,启动分布式集群上的spark组件服务加载数据文件。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于选择的开发语言使用对应的容器镜像创建所述分析模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
定制各开发语言的容器镜像。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
针对各发语言定制其运行时环境、日志监控服务、语言开发基础库,并封装成预设格式的容器镜像;
构建容器镜像与开发语言的一一映射关系。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
设置分析模块进行数据输入/输出的数据格式。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于选择的开发语言引用容器镜像内部预置的算法框架创建所述分析模块;或,
基于选择的开发语言对应的语言扩展包中包含的算法框架创建所述分析模块。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
生成预设格式的算法模型,所述算法模型的格式包括pkl格式、预测模型标记语言pmml格式、h5格式中的至少之一。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
对生成的算法模型进行评估。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
识别算法模型的格式;
根据算法模型的格式加载所述算法模型;
判定所述算法模型的类别;
根据所述算法模型的类别使用对应的评估指标进行评估。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
对算法模型的各评估指标的分数和算法模型信息进行存储。
进一步地,所述算法模型的类别包括下述至少之一:聚类、分类、回归、异常检测及语言处理。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
对评估后的算法模型进行发布。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
基于算法模型的各评估指标的分数筛选待发布算法模型;
对筛选出的待发布算法模型进行发布。
进一步地,所述数据分析工作流运行程序被所述处理器执行时实现如下操作:
识别待发布算法模型的格式;
确定模型服务的部署策略和调用方式;
构建模型服务镜像,并基于所述部署策略申请发布资源;
基于申请到的发布资源运行所述模型服务镜像,按照识别的格式解析所述待发布算法模型,并按照确定的调用方式提供应用发布的算法模型的接口。
进一步地,所述模型服务的调用方式包括超文本传输协议-表述行状态转移http-rest接口调用、消息队列mq调用、及批处理batch调用中的至少一种。
本发明还提出一种存储介质,该存储介质存储有计算机程序,所述计算机程序被执行时实现如上所述的数据分析工作流的运行方法的步骤。
- 还没有人留言评论。精彩留言会获得点赞!