基于非参数核密度估计的太阳能集热器出力概率建模方法与流程
本发明涉及光热系统建模技术领域,特别涉及一种太阳能集热器出力概率建模方法。
背景技术:
在能源问题日益突出的今天,太阳能作为一种清洁且来源广泛的可再生能源受到人们的广泛关注。太阳能集热器能够将太阳能有效地转化为热能,但其制热量受到室外温度、太阳辐射等因素影响,导致其出力具有随机性、间歇性和周期性,而目前对太阳能集热器出力研究集中在对其机理模型性能分析,并未考虑由于实际天气条件的随机性和不同集热器模型的差异性导致实际集热器出力的不确定性,因此无法准确评估太阳能集热器出力大小。而在工程设计中,集热器选型需要满足实际负荷需求,研究分析集热器出力的概率特性以及具有普遍意义的集热器出力概率特性建模方法是计算集热器有效出力大小的前提,因而具有重要的理论和工程价值。
据检索,目前采用非参数核密度估计概率建模主要应用在风电功率预测领域,如公开号为cn105354636a的中国专利申请公开了一种基于非参数核密度估计的风功率波动性概率密度建模方法。具体步骤如下:通过小波分解对风功率样本数据的波动量进行提取,基于波动量样本建立相应的非参数核密度估计模型,然后针对模型带宽选择问题,构造了一种以拟合优度检验为约束条件的约束带宽优化模型,利用约束序优化算法对该优化模型进行求解。
又如公开号为cn106548253a的中国专利申请公开了一种基于非参数核密度估计的风电功率预测的方法,所述方法包括:步骤一,获取预设的时间范围内历史的风电场数据,将实测风电功率数据划分为多个子区间,其中,所述风电场数据包括实测风速和实测风电功率;步骤二,统计每个子区间内的实测风电功率,并根据各个实测风速子区间内的风电功率分布,分别建立风电功率概率密度函数;步骤三,确定实测风电功率的置信区间,删除置信区间外的风电功率数据所得置信区间内的数据就是筛选出来的建模数据;步骤四,采用s型函数拟合建模数据,建立风电功率预测模型进行预测。
上述两种对风电功率进行概率建模的方法均存在不足之处,第一种技术方案在考虑约束带宽优化模型时仅考虑了拟合优度检验,并未对结果进行实际数据分析后修正,因此不能准确评估概率模型与观测分布的误差,缺乏对误差的定量分析,导致误差可能偏大。第二种技术方案的并未考虑不同时间尺度下不同地区的风电场概率密度函数不同,导致最终概率分布结果也不同,仅考虑了某单一风电场预设时间范围内的历史数据,并且缺乏拟合优度检验和实际修正,不具有结果评价指标。
技术实现要素:
本发明的目的在于克服已有技术的缺点,提供基于非参数核密度估计的太阳能集热器出力概率建模方法。该方法更能精确的反映集热器在不同时间尺度下出力的随机特性和变化规律,具有良好的稳定性,能达到更好的适用性和准确性。
本发明实现其发明目的所采用的技术方案是:
一种基于非参数核密度估计的太阳能集热器出力概率建模方法,包括以下步骤:
步骤1:获取历史实测逐时气象数据并按不同年份数进行统计;
步骤2:通过式(1)的太阳能集热器出力非参数核密度估计模型,求解单位面积集热器出力值p和带宽值h:
式中:h为待求解带宽值,pi为p1~pn中n个历史实测气象数据出力样本值中的第i个样本值,n为在采样周期内的样本个数;
步骤3:修正非参数核密度估计模型:分别采用k-s检验和χ2检验计算得到带宽值h的检验评估值,然后将两个检验评估值分别与对应临界值比较,若计算得出k-s检验和χ2检验评估值均小于等于带宽值的临界值,则带宽值满足拟合精度要求;若两个评估结果值中的至少一个大于带宽值的临界值,则返回步骤2,修改设定精度要求a值大小,重复步骤2、3,直至满足步骤3检验要求为止。
与现有的技术相比,本发明的有益效果是:
1、本发明建立的概率模型与传统的集热器机理模型相比,更能精确的反映集热器在不同时间尺度下出力的随机特性和变化规律,能够在前期缺乏历史运行数据的条件下,用于光热系统的规划和可靠性研究;
2、本发明提出的基于黄金分割理论求解非参数核密度估计的最优带宽的方法,通过拟合优度检验和误差修正,能够说明在保证拟合平滑度的同时保证了准确度,同时在考虑不同时间尺度下的集热器出力时,该模型具有良好的稳定性;
3、本发明通过与常见的参数估计概率模型对比,说明非参数核密度估计法在不需做出任何先验分布假设的条件下,通过出力数据样本驱动,能达到更好的适用性和准确性。
附图说明
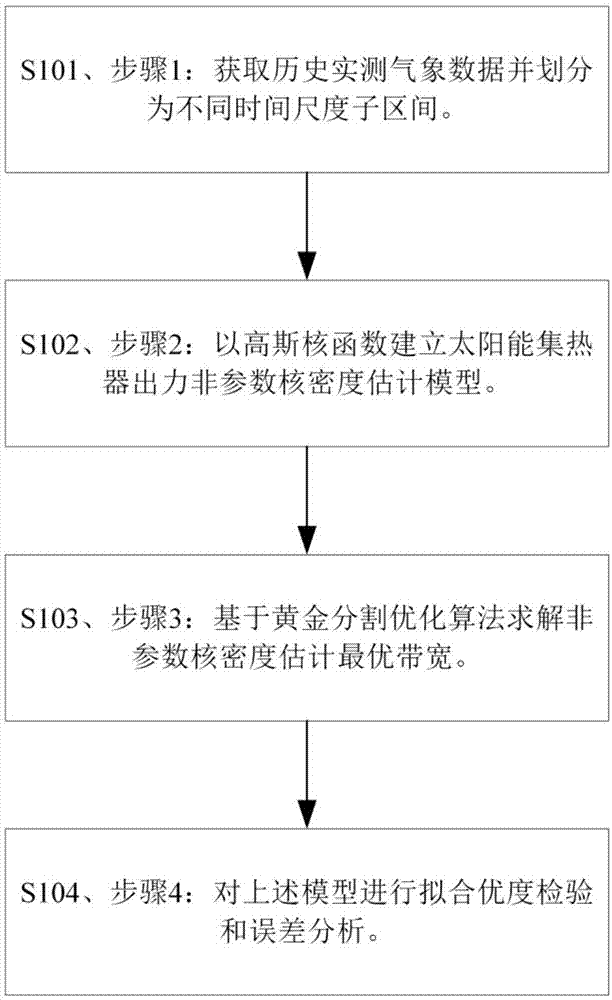
图1是本发明提供的一种基于非参数核密度估计的太阳能集热器出力概率建模方法流程图;
图2是本发明采用黄金分割法优化求解流程图;
图3是本发明实施例中集热器出力样本数据图;
图4(a)是本发明实施例中1年数据采用3种方法拟合结果对比图;
图4(b)是本发明实施例中5年数据采用3种方法拟合结果对比图;
图4(c)是本发明实施例中10年数据采用3种方法拟合结果对比图;
图4(d)是本发明实施例中20年数据采用3种方法拟合结果对比图;
图5是本发明实施例中建模方法与常见4种概率建模拟合结果对比图。
具体实施方式
如图1所示,基于非参数核密度估计的太阳能集热器出力概率建模方法,包括以下步骤:
步骤1:获取历史实测逐时气象数据并按不同年份数进行统计;
步骤2:通过式(1)的太阳能集热器出力非参数核密度估计模型,求解单位面积集热器出力值p和带宽值h:
式中:h为待求解带宽值,pi为p1~pn中n个历史实测气象数据出力样本值中的第i个样本值,n为在采样周期内的样本个数。
式(1)的推导过程如下:设p1,p2,…,pn为单位面积集热器出力在设定的采样周期内的n个样本,则集热器出力的概率密度函数的非参数核密度估计可表示为式(2):
式中:f(p,h)为基于非参数核密度估计的集热器出力概率密度函数;k(p,h)为核函数;p为待求解的单位面积集热器出力值;h为带宽值,带宽值的大小影响整个模型精度,h值越大精度越低,但计算量降低。
为了满足概率密度函数的连续性,核函数多选择平滑非负的单峰概率密度函数。核函数的选择具有多样性,但一旦带宽值h确定,不同核函数的选择对非参数核密度估计的准确性影响不大,因此选择式(3)高斯核函数作为集热器出力概率密度非参数核密度估计的核函数。
其中本模型的高斯核函数取值如式(4)所示:
式中:pi为p1~pn中n个历史实测气象数据出力样本值中的第i个样本值,p为待求解的单位面积集热器出力值,h为带宽值。
将式(4)带入式(3)再带入式(2)可以得到集热器出力的概率密度非参数核密度估计式(1)。
核密度估计法的核心问题是最优带宽值h的选取,带宽选择过大会使f(p)相对比较平滑,但准确性较差;带宽选择过小会使f(p)波动性较大,处于欠平衡的状态。因此需要综合考虑带宽的大小保证核密度估计的准确性和平滑性。
参阅图2,作为本发明的一种优选的实施方式,采用黄金分割法求解式(1)中的带宽值h,具体步骤如(a)~(f):
(a)设定计算精度ε=a;
(b)采用黄金分割法的试算点计算公式,对每次迭代区间上下限进行重复计算,公式如下:
式中:ui、vi分别为第i次迭代后新区间的上下限,i为迭代次数,初始值i=1,设pi的初始值为0,qi的初始值为h1,
(c)若qi-pi<ε,则停止计算,取最小点
式中:
当emise(ui)>emise(vi),进行步骤(d);当emise(ui)≤emise(vi),进行步骤(e)。
(d)令pi+1=ui,qi+1=qi,ui+1=vi,emise(ui)=emise(vi),重新计算vi+1点:vi+1=pi+1+0.618(qi+1-pi+1)。计算vi+1的函数值emise(vi+1),继续步骤(f)。
(e)令pi+1=pi,qi+1=vi,vi+1=ui,emise(vi)=emise(ui),重新计算ui+1点:ui+1=pi+1+0.382(qi+1-pi+1)。计算vi+1的函数值emise(vi+1),继续步骤(f)。
(f)令i=i+1,返回步骤(c)重复步骤(c)~(e),直到满足qi-pi<ε精度要求为止。
当然除了本发明方法,还可以采用常见的求解方法有解析法和经验公式法,分别求得最优带宽值h:
方法一:解析法
式中:n为样本总数,σ为样本标准差。
方法二:经验公式法
式中:σ为样本标准差,iqr为样本四分位距。
但传统的解析法存在求解复杂,且需要略去两个高阶无穷小量,因此其精度存在一定误差。
步骤3:修正非参数核密度估计模型:分别采用k-s检验和χ2检验计算得到带宽值h的检验评估值,然后将两个检验评估值分别与对应临界值比较(分别通过查《thekolmogorov–smirnovgoodnessoffit》1951,massey著和《统计学》清华大学出版社出版社2004附表二表5得到)。若计算得出k-s检验和χ2检验评估值均小于等于带宽值的临界值,则带宽值满足拟合精度要求;若两个评估结果值中的至少一个大于带宽值的临界值,则返回步骤2,修改设定精度要求a值大小,重复步骤2、3,直至满足步骤3检验要求为止。k-s检验和χ2检验方法见《拟合优度检验》科学出版社2011版,杨振海著。
实施例1
本发明采用a地区20年的天气实测数据为基础,设计以下仿真算例,来验证本发明方法的适用性。
1)仿真数据说明:
实测天气数据包括逐时太阳辐射照度、干球温度、风速。分别以1年、5年、10年、20年数据对模型适用于不同时间尺度进行分析,采样区间为采暖季(当年11月15日-次年3月15日)每日9:00-15:00,采样间隔为1小时。
2)太阳能集热器模型的建立:
根据能量平衡方程可以得到单位面积集热器出力表达式,如式(7)所示:
式中:qu为单位面积集热器有效能,i为太阳总辐射照度,τ为玻璃盖板透光率,α为吸热体吸收率,ul为集热器总热损失系数,tfi为集热器工质入口温度,tfo为集热器工质出口温度,te为环境温度。
经太阳能集热器模型计算统计后的20年的集热器出力样本数据分别如图3所示。
3)拟合优度检验对比:
采用高斯核函数,分别采用解析法、经验公式法和本发明黄金分割法计算得到最优带宽进行对比分析,分别以1年、5年、10年和20年的集热器出力作为样本数据,得到3种方法所得的带宽及核密度估计分布的拟合优度检验结果如表1所示,概率密度曲线如图3所示。
表1三种方法拟合优度检验结果
通过表1可以看出,在进行不同时间尺度下的拟合优度检验时,本发明计算所得带宽均能通过卡方检验和k-s检验,并且为三类方法中的最小值。从图4(a)至图(d),可以得到,由于时间尺度的不同会导致概率分布直方图平滑程度的改变,不同时间尺度下采用本发明方法拟合的分布都大致符合原概率分布趋势,具有良好的平滑度和准确度。经验公式法和解析法由于采用近似计算求解,导致带宽选取较大,概率密度曲线平滑度增加,拟合精度降低,不能反映图4(a)所示的短时间尺度下的概率分布直方图的波动。但由图4(a)至图(d),随着时间尺度的增加,概率分布曲线趋于平滑,采用经验公式法和解析法也能够较好拟合概率密度曲线,与本发明方法差距逐渐越小。
因此本发明提出的非参数核密度估计具有良好的稳定性和准确性,同时本发明所提出的黄金分割法求解最优带宽与其余两种方法相比,最大的优点在于计算所得带宽值准确度更高拟合效果更好,也避免了带宽选择过大导致的拟合过于平滑、精度降低的问题。
4)误差检验对比:
采用式(8)和式(9)表示的平均误差百分数(mape,记为emape)和均方根误差(rmse,记为ermse)作为本发明误差分析的指标。两个误差指标越小,说明光热出力概率模型与数据观测分布之间的差异越小。
式中:n为区间数;rgi为本发明建立概率密度模型通过离散化后第i个出力区间的概率,例如根据求解得到的概率密度曲线,划分为n个区间,若i=1,统计第一个区间内符合出力范围的次数,用该次数除去总共样本数量,即可求得第一个区间的rg1值;roi为实际样本值生成的直方图在第i个区间的概率,原理同上,例如根据实际样本值,划分为n个区间,若i=1,统计第一个区间内符合出力范围的次数,用该次数除去总共样本数量,即可求得第一个区间的ro1值。举一具体例子进行说明:例如根据仿真值,可以经过以上步骤求解得到的概率密度曲线,假设得到出力范围为0~100w/m2,划分为10个区间,若第一个区间0~10w/m2内有m个符合,则可求得第一个区间的rg1值为m/n,依次求得第i个区间的rgi值;原理同上,根据实际样本值,可依次求得第i个区间的roi值。
根据emape和ermse作为检验指标,以a地区1年、5年、10年和20年的集热器出力数据作为样本进行定量对比分析,三种方法误差检验结果如表2所示。
表2三种方法误差检验结果
通过表2可以看出,本发明方法各检验指标均小于前两种方法:emape在25%以内,ermse在0.006以内,满足精度要求。
5)常见拟合模型的对比:
为进一步验证本发明模型与现有常用概率分布模型拟合精度上的差异,将本发明建立的非参数核密度估计模型与指数分布、对数正态分布、gama分布和正态分布进行对比,对比结果如图5所示。由图5可知,与常用概率模型对比,本发明方法拟合程度较好,不仅能够反映集热器出力数据的概率分布趋势且保证了一定的平滑度。目前文献中常见的几种概率分布模型虽然能够从趋势上大致拟合概率分布直方图,但由于在不同地区、不同时间尺度的条件下,不同集热器出力实际概率分布不同,因此不具有普适性。其中gama分布拟合虽趋势较为一致,但是无法准确拟合厚尾部分,导致拟合精度不高,与本发明所提出的非参数核密度估计模型相比仍存在较大差距。
- 还没有人留言评论。精彩留言会获得点赞!