一种基于生成对抗网络模型的图像补全方法与流程
本发明涉及深度学习神经网络技术领域,具体涉及一种基于生成对抗网络模型的图像补全方法。
背景技术:
生成式对抗网络(generativeadversarialnetwork,简称gan)是由goodfellow在2014年提出的深度学习框架,它基于“博奕论”的思想,构造生成器(generator)和判别器(discriminator)两种模型,前者通过输入(0,1)的均匀噪声或高斯随机噪声生成图像,后者对输入的图像进行判别,确定是来自数据集的图像还是由生成器产生的图像。
在传统的对抗网络模型中,判别器接收的是随机噪声,通过不断地学习数据集中的分布,将随机噪声生成满足数据集分布的图像。在这种情况下,整个网络的训练速度较慢,并且没有自动补全图像的功能。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,构建了一种基于生成对抗网络模型的图像补全方法。
本发明的目的可以通过采取如下技术方案达到:
一种基于生成对抗网络模型的图像补全方法,所述的图像补全方法包括下列步骤:
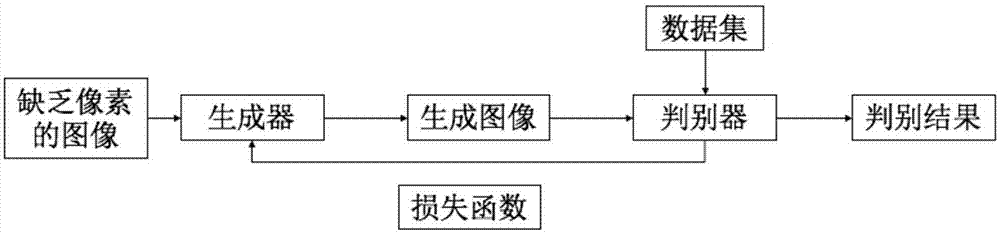
s1、构造原始生成对抗网络模型,生成器通过生成图像输入至判别器进行网络训练;
s2、构造深度卷积神经网络作为生成器与判别器;
在原始的生成对抗网络模型中,充当生成器与判别器功能的模型较为简单,而在本发明中,采用深度卷积神经网络作为生成器与判别器,能够以更高的效率学习到数据集中图像的特征。
s3、去除数据集图像中的部分像素,输入生成器中;
s4、在生成器中运用卷积神经网络对图像进行补全;
s5、将补全之后的图像与数据集图像输入判别器中判别,更新损失函数。
进一步地,所述的步骤s2中构造的神经网络包含多个卷积核,其中卷积核的个数根据数据集图像特征的复杂程度设置。
进一步地,所述的步骤s4中在生成器中运用卷积神经网络对图像进行补全,具体过程如下:
s41、利用卷积神经网络充当生成器、判别器;
s42、利用卷积将输入图像缺失的像素进行补全。
进一步地,所述的步骤s5中,将补全之后的图像与数据集图像输入判别器中判别,更新损失函数。
其中,所述的损失函数的表达式为:
其中,d(x)表示判别器对图像的判别,pr表示数据集图像的分布,pg表示生成图像的分布,λ为超参数,
本发明相对于现有技术具有如下的优点及效果:
高效性:本发明根据图像补全的操作过程,将去除部分像素的图片输入至生成器中,通过卷积神经网络充当生成器与判别器的功能,通过对抗训练与更新损失函数,实现了生成器自动补全图像的效果。
附图说明
图1是生成对抗网络通过图像补全进行训练的整体流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
本实施例公开了一种基于生成对抗网络模型的图像补全方法,具体包括下列步骤:
步骤s1、构造原始生成对抗网络模型,生成器通过生成图像输入至判别器进行网络训练。
步骤s2、构造深度卷积神经网络作为生成器与判别器;
不同的卷积核,体现在矩阵数值的不同、行列数的不同。
构造多个卷积核,在处理图像的过程中,不同的卷积核意味着能够在网络训练的过程中学习到生成图像的不同特征。
在传统的对抗网络模型中,判别器接收的是随机噪声,通过不断地学习数据集中的分布,将随机噪声生成满足数据集分布的图像。在这种情况下,整个网络的训练速度较慢,并且没有自动补全图像的功能。而本发明根据图像补全的操作过程,将去除部分像素的图片输入至生成器中,通过卷积神经网络充当生成器与判别器的功能,通过对抗训练与更新损失函数,实现了生成器自动补全图像的效果。
在实际应用中,应该根据数据集图像特征的复杂程度,设置卷积核的个数。
步骤s3、去除数据集图像中的部分像素,输入生成器中。
步骤s4、在生成器中运用卷积神经网络对图像进行补全。
具体方法如下:
s41、利用卷积神经网络充当生成器、判别器;
s42、利用卷积将输入图像缺失的像素进行补全。
步骤s5、将补全之后的图像与数据集图像输入判别器中判别,更新损失函数。具体过程如下:
s51、将补全之后的图像与数据集图像输入判别器中判别,更新损失函数。
损失函数的作用是衡量判别器对生成图像判断的能力。损失函数的值越小,说明在当前迭代中,判别器能够有较好的性能辨别生成器的生成图像;反之则说明判别器的性能较差。
损失函数的表达式为:
其中,d(x)表示判别器对图像的判别,pr表示数据集图像的分布,pg表示生成图像的分布,λ为超参数,
综上所述,本实施例公开了一种基于生成对抗网络模型的图像补全方法,在传统的对抗网络模型中,判别器接收的是随机噪声,通过不断地学习数据集中的分布,将随机噪声生成满足数据集分布的图像。在这种情况下,整个网络的训练速度较慢,并且没有自动补全图像的功能。而本发明根据图像补全的操作过程,将去除部分像素的图片输入至生成器中,通过卷积神经网络充当生成器与判别器的功能,通过对抗训练与更新损失函数,实现了生成器自动补全图像的效果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!