一种基于关节点特征的跌倒检测方法与流程
本发明涉及一种跌倒检测方法,更加详细而言,涉及一种基于关节点提取以及svm分类器的跌倒检测方法。
背景技术:
在世界范围内人口老龄化问题日益严重,并且预计在2050年,老年人(年龄超过60岁)人口数量将达到20亿之众,因此老年人的安全问题变得愈加重要。而对老年人的安全问题威胁最大的便是意外摔倒,导致老年人跌倒有多种原因,包括心脏病突发、遭到碰撞、地面湿滑等等。同时,跌倒也会给老年人带来诸如髋部骨折、创伤性脑损伤以及肢体骨折等多种问题,如不能及时发现,甚至可能导致老年人死亡。通过美国的一项调查表明,每年有大约250万老年人因跌倒而送入医院急诊科,并且这些送入急诊的老年人中大约有六分之一因送救不及时而死亡。
目前存在的跌倒检测算法主要分为三大类—基于可穿戴设备的跌倒检测算法、基于环境式的跌倒检测算法以及基于计算机视觉的跌倒检测算法。基于可穿戴设备的检测算法虽灵活方便、制作简单,但需要用户长期穿戴,会对人体活动带来很多的不方便;而基于环境式的跌倒检测算法,其使用成本相对较高并且使用区域具有一定的局限性;基于计算机视觉的检测算法无需穿戴,不会影响到用户的日常活动,并且也不需要在固定的环境安装所需的传感器,自然不会受到场地的限制,只要是装有摄像头的地点便可应用。由此可见基于计算机视觉的算法具有诸多优势以及广阔的应用前景。本发明所提出的跌倒检测方法便是基于计算机视觉的检测方法。
基于计算机视觉的跌倒检测方法面临着诸多的挑战,比如将人从复杂的背景中提取出来、不同的人体形不同以及场景中存在多个人时检测的准确率会大大降低。
技术实现要素:
本发明的目的是克服现有技术中的缺陷与不足,提出了一种基于关节点特征的跌倒检测方法,通过svm(supportvectormachine)分类器对提取出来的关节点进行分类,以判断此时人处于跌倒的哪个阶段,并对每一帧图像提取出关键的类别,进一步判断是否有人跌倒。
为实现上述目的,本发明采用如下技术方案:
一种基于关节点提取的跌倒检测方法,包括如下步骤:
步骤1:通过目标检测算法对获取到的视频的各帧图像分别进行处理,截取其中包含人的区域;
步骤2:提取步骤1中截取到的区域中的关节点,得到关节点信息,并对所述关节点信息进行归一化;
步骤3:对各帧图像的关节点信息进行分类,得到类别序列;
步骤4:对步骤3中得到的类别序列进行简化,将多个连续相同的类别用一个类别来代表;
步骤5:通过步骤4中得到的简化后的类别序列判断视频中是否有跌倒事件发生。
优选的,步骤1中,所述目标检测算法为yolo算法。
优选的,步骤1中,截取含人区域具体步骤如下:将存在人的区域进行扩展切割,将人体所在区域表示为(x,y,w,h),其中x为区域左上角的横坐标,y为区域左上角的纵坐标,w为区域的宽度,h为区域的高度;切割公式如下:
x_cut=x*0.9(1)
y_cut=y*0.9(2)
w_cut=x_cut+w*1.2<image.cols?w*1.2:image.cols-x_cut(3)
h_cut=y_cut+h*1.2<image.rows?h*1.2:image.rows-y_cut(4)
其中,x_cut为切割后的左上角的横坐标,y_cut为切割后的左上角的纵坐标,w_cut为切割后的图像的宽度,h_cut为切割后的图像的高度,image.cols为图像的宽度,image.rows为图像的高度。
优选的,针对单帧图像中有多人存在且两个人足够靠近的情况下可能存在不同的切割区域包含相同的两个人的情况,进而出现重复识别的问题;对于这一问题,本发明采用如下公式进行解决:
其中s1和s2为切割后的两个区域的面积,当公式(5)大于阈值时,则只保留两个区域中面积最大的那个区域。
优选的,步骤2中,通过openpose算法提取图像中人的关节点信息。
优选的,对步骤2所得关节点信息进行归一化,公式如下:
其中(x_nm,y_nm)为归一化后的关节点坐标,(x_base,y_base)为基准关节点的坐标;当无法识别到基准关节点时,将全部的关节点坐标置为0。
优选的,步骤3中,采用svm分类器将关节点信息分为5类:正常阶段pnormal、跌倒阶段pfalling、平躺阶段play、其他阶段pothers,以及全关节点为0的情况;正常阶段为:人正常直立行走以及正常坐的状态;平躺阶段为:人全身平躺在地上的状态;跌倒阶段为:人从正常阶段向平躺阶段的转化的过程;其他阶段:除上述3个阶段外的其他阶段。
优选的,步骤3中,根据不同阶段的重要程度不同对不同的阶段赋予不同的权重值,如果所述视频图像中存在多个人,提取出其中权重值最高的一个阶段作为该视频图像的关节点信息所处阶段的代表。
优选的,选取一个滑动窗口,对步骤3中获取的类别序列进行滤波,去除异常的类别后进入步骤4。
优选的,步骤5中,通过判断步骤4中得到的简化后的类别序列是否存在连续的跌倒与平躺状态,来判断视频中是否有跌倒事件发生;如果存在则说明视频中有跌倒事件发生,否则说明视频中此时间段暂无跌倒事件。
有益效果:1、本发明所采用的基于关节点特征的方法有效的解决了不同人的体形不同的问题,因为本发明只需考虑人关节点的信息而不需要考虑人的外部轮廓信息;
2、当视频中某一时刻存在多个人时,也即某一时刻视频中存在多个跌倒的阶段,本发明只提取其中权重值最大的阶段作为该时刻的阶段的代表,这样便有效的避免了其他无关阶段的影响,进而提高了在视频中存在多人的情况下的识别准确率;
3、通过yolo算法与openpose算法相结合,提高了关节点提取的准确率。
附图说明
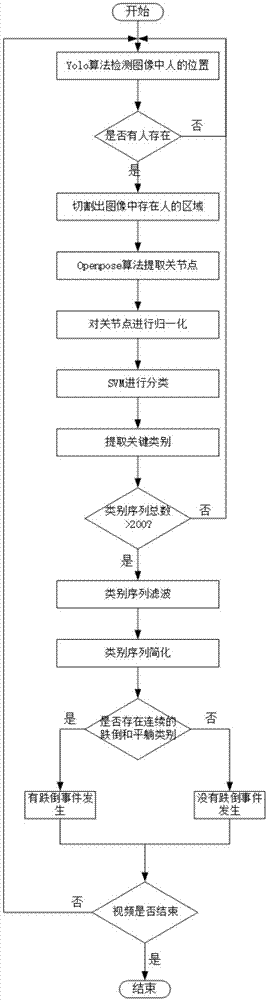
图1是本发明一种基于关节点特征的跌倒检测方法的算法流程图。
图2是本发明提取的关节点示意图,其中0-17分别表示人体不同位置的关节点,0-鼻子,1-颈部,2-右肩关节,3-右肘关节,4-右手腕关节,5-左肩关节,6-左肘关节,7-左手腕关节,8-右髋关节,9-右膝关节,10-右脚踝关节,11-左髋关节,12-左膝关节,13-左脚踝关节,14-右眼,15-左眼,16-右耳,17-左耳。
具体实施方式
下面结合实施例对本发明做更进一步的解释。
步骤1:获取视频数据;
步骤2:每隔5帧取1帧图像进行处理;
步骤3:通过yolo(youonlylookonce)算法对步骤2中获取到的图像进行处理,识别此帧图像中是否存在人,如果有人存在则将人所在的区域切割出来,进入步骤4,否则返回步骤2;
步骤4:通过openpose算法对步骤3中切割出来的图像进行处理,提取图像中人的关节点信息,并对这些关节点信息进行归一化;
步骤5:通过svm分类器对步骤4中获取的关节点信息进行分类;
步骤6:从步骤5得到的类别中提取出最为关键的一个类别,并将这个类别存储下来,重复步骤2到步骤6直到存储的类别数量达到一定的值时(此处取200),将这些类别数据送入步骤7;
步骤7:选取一个滑动窗口,对步骤6中获取的类别序列进行滤波,去除误检的类别;
步骤8:对步骤7中得到的类别序列进行简化,将多个连续相同的类别简化为一个类别;
步骤9:通过判断步骤8中得到的类别数据是否存在接连的跌倒与平躺阶段,如果存在则说明视频中有跌倒事件发生,否则说明视频中此时间段暂无跌倒事件发生。
对于步骤3,由于openpose存在会在无人区域误识别出关节点的问题,本发明采用yolo算法初步对区域中的人进行识别与定位,将确定存在人的区域送入到openpose算法中进行关节点的提取。
步骤3中yolo算法检测图像中是否有人存在的步骤如下:yolo算法首先对图像进行分块处理,共分成了7*7的小块;然后每一个小块负责预测中心点落在这个小块中的目标的类别和位置;最后通过神经网络,yolo算法能够准确的预测出图像中各目标的类别及其所在位置;之后我们对yolo算法识别出的所有目标类别进行判断,如果其中有类别是“人”,则说明图像中存在人,否则说明图像中不存在人。当图像中有人存在时,我们记录下图像中“人”所在的位置。
步骤3中的图像切割方法具体如下:将存在人的区域进行扩展切割,本发明将人体所在区域表示为(x,y,w,h)其中x为区域左上角的横坐标,y为区域左上角的纵坐标,w为区域的宽度,h为区域的高度。切割公式如下:
x_cut=x*0.9(1)
y_cut=y*0.9(2)
w_cut=x_cut+w*1.2<image.cols?w*1.2:image.cols-x_cut(3)
h_cut=y_cut+h*1.2<image.rows?h*1.2:image.rows-y_cut(4)
其中公式(3)中的image.cols为图像的宽度,公式(4)中的image.rows为图像的高度,公式(3)和公式(4)是为了防止所截取的区域越界。
步骤3中,由于采取了扩展切割,在多人存在且两个人足够靠近的情况下可能存在不同的切割区域包含相同的两个人的情况,从而导致重复识别的问题。此处本发明仿照iou(intersectionoverunion)的思路来解决这个问题,其公式如下:
其中s1和s2为切割后的两个区域,当公式(5)大于一定阈值时,则只保留两个区域中面积最大的那个区域,通过实验测试得到,当阈值为85%时效果最佳。
步骤4中openpose算法提取关节点的步骤如下:openpose算法采用了一个具有两个分支的网络结构,其中的一个分支负责预测关节点的位置(此时仅仅是预测出哪里存在关节点,但不知道具体是哪一个人的哪个关节点),另一个分支负责预测各关节点之间的位置关系。openpose算法首先通过上述网络同时预测关节点的位置以及身体各关节点之间的关联度,最后通过匈牙利算法分析前面预测出的两部分,以得出人体的关节点位置(即肩部关节点的位置是什么、肘部关节点位置是什么等等)。
对于步骤4中的归一化方法,本发明选取图2中的关节点1为基准点进行归一化,归一化公式如下:
其中)x_nm,y_nm)为归一化后的关节点坐标,(x_base,y_base)为基准关节点(即关节点1)的坐标。当无法识别到基准关节点时,我们将全部的关节点坐标置为0。
步骤5中,本发明总共分了5类,包括跌倒的4个阶段以及全关节点为0的情况。跌倒的4个阶段分别为正常、跌倒、平躺以及其他4个阶段。正常阶段为:人正常直立行走以及正常坐的状态;平躺阶段为:人全身平躺在地上的状态;跌倒阶段为:人从正常阶段向平躺阶段的转化的过程;其他阶段为:除其余3个阶段的其他阶段,例如坐下阶段和起立阶段。同时本发明根据不同阶段的重要程度不同对不同的阶段赋予不同的权重值,在此本发明将正常阶段表示为pnormal,跌倒阶段表示为pfalling,平躺阶段表示为play,其他阶段表示为pothers,全关节点为0的阶段表示为pzero。各阶段的重要程度如下:pfalling>play>pothers>pnormal>pzero,因此本发明对各阶段赋予权值如下:ωfalling=4,ωlay=3,ωothers=2,ωnormal=1,ωzero=0。
步骤5中svm分类器分类步骤如下:首先,通过le2ifalldetection数据集对svm分类器进行训练,svm分类器的分类类别如前段所述;在检测阶段,将通过openpose算法提取到的关节点信息送入到训练好的svm分类器中进行分类,这样便得到了输入的关节点对应的人所处的跌倒阶段。
步骤6中,如果图像中存在多个人,则通过步骤4可以提取出多个关节点,通过步骤5我们将识别出多个类别,因此对于同一帧图像我们能够识别出多个类别,这样便会对最终的识别结果造成影响。由于本发明需要检测的是视频中是否存在跌倒事件,因此我们只需要提取出其中对识别跌倒来说最为关键的一个类别即可。本发明按照前一段所述的权值来提取关键类别,如此时从第i帧图像中识别到的类别序列为{pfalling,play,pothers,pnormal,pzero},则其提取过程如下:
其中framei表示视频中的第i帧图像,最后从每一帧图像中提取出最为关键的一个类别。
步骤7中,本发明选取了一个滑动窗口,对滑动窗口中帧图像识别出的类别序列进行滤波。由于步骤5中的svm分类器对帧图像的分类并未达到100%的识别准确率,因此必然存在误检的情况,由于视频中的类别是连续的,因此本发明采用了滑动窗口的策略,取滑动窗口中识别出来的类别众数来填充整个滑动窗口,这样便有效的去除滑动窗口中的毛刺。本发明所取滑动窗口的大小为5,如此时滑动窗口中所包含的识别类别为{pfalling,pfalling,pothers,pfalling,pfalling},则其滤波过程如下:
其中pothers为其中的误检点,通过滤波操作有效的去除了其中的误检点。
步骤8中,从步骤7中获取了去除了毛刺的类别序列,这样在步骤8中我们得到的便是连续的类别序列,由于是连续的相同的类别,则这些类别可以通过一个类别来代表,这样便得到了一个简化的识别类别序列,同时,本发明也对这个类别序列进行去零点处理(这里的零点是指类别为pzero的帧,由于不管pzero出现在其余的哪个类别中,将它去除都不会对最终的识别结果产生负面影响,反而会提高识别的准确率)。如此也便大大简化了我们下一步对视频中是否存在跌倒事件的判别,进而提高了计算的效率与准确率。假设我们从步骤7中获取到的类别序列为{pnoraml…pnormal,pzero…pzero,pnoraml…pnormal,pfalling…pfalling,play…play},则此序列的简化过程如下:
步骤9中,本发明对步骤8中获取到的类别序列进行判断,如若类别中存在接连的pfalling和play类别则判断视频中有跌倒事件发生,否则没有跌倒发生。即若序列为{pnormal,pfalling,play}则视频中有跌倒事件发生,若序列为{pnormal,pothers,play}则视频中没有跌倒事件发生。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!