超算集群上的粒子追踪方法和系统与流程
本发明属于粒子追踪计算技术领域,具体地说,是涉及一种超算集群上的粒子追踪方法和系统。
背景技术:
在计算机中,集群(cluster)是使用多个计算单元,如典型的个人计算机或unix工作站,多个存储设备和记忆冗余的互连线路来组成一个对用户来说单一的、高可用的系统;或者说,集群是一组相互独立的、通过网络互联的计算机,他们构成一个组,并以单一系统的模式加以管理;一个客户与集群相互作用时,集群像是一个独立的服务器。通过集群技术,可以在付出较低成本的情况下,获得在性能、可靠性、灵活性方面的相对较高的收益。
在流体力学里,有两种描述流体运动的方法,欧拉法和拉格朗日方法;欧拉法描述的是任何时刻流畅中各种变量的分布,而拉格朗日法是去追踪每个粒子从某一时刻起的运动轨迹。拉格朗日粒子追踪算法可以模拟海流中漂浮物的移动轨迹,通过模拟粒子移动轨迹,可以研究粒子对海洋的影响。
实际应用中,在诸如suntans等的开源代码中增加拉格朗日粒子追踪方法之后,在集群上执行时,集群中的每个节点负责一个区域或范围内的粒子的追踪计算,则基于粒子随流体模型运动的特点,一个节点负责的区域或范围内的粒子,可能离开该区域或范围,也可能进入其他的节点负责的区域或范围,因此,集群中的每一个节点在加载了粒子完成了本节点的追踪计算任务之后,本节点的粒子可能已经不在本节点追踪范围内,则需要与其他对等节点进行粒子交换通信,向其他节点发送粒子以及从其他节点接收粒子,使得粒子变换节点执行后续追踪计算,这种大数据量的计算会导致计算速度比较慢的问题。
技术实现要素:
本申请提供了一种超算集群上的粒子追踪方法和系统,解决现有集群上执行粒子追踪计算存在计算速度慢的技术问题。
为解决上述技术问题,本申请采用以下技术方案予以实现:
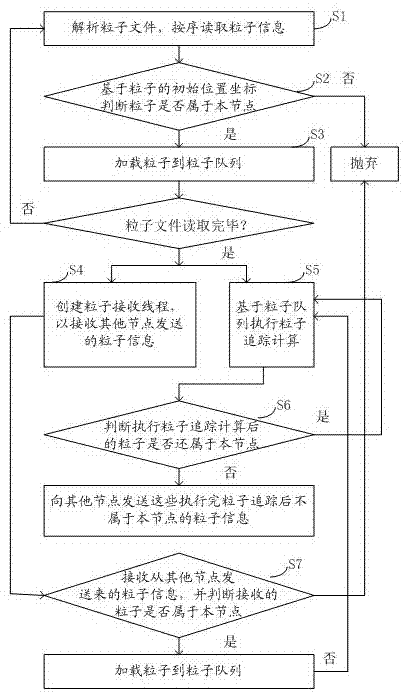
提出一种超算集群上的粒子追踪方法,包括:超算集群中的所有节点均执行以下步骤:步骤1、解析粒子文件,按序读取粒子信息;步骤2、基于粒子的初始位置坐标判断粒子是否属于本节点;若是,步骤3、加载所述粒子到粒子队列;步骤4、重复步骤1到步骤3,直至所述粒子文件读取完毕;步骤5、创建粒子接收线程,以接收其他节点发送的粒子信息;以及,步骤6、基于所述粒子队列执行粒子追踪计算。
提出一种超算集群上的粒子追踪系统,所述超算集群包括若干节点,所述系统包括读取模块、判断模块、加载模块、粒子追踪模块和接收线程创建模块;对于所述超算集群的所有节点,所述读取模块,用于解析粒子文件,按序读取粒子信息;所述判断模块,用于基于粒子的初始位置坐标判断粒子是否属于本节点;所述加载模块,用于加载所述粒子到粒子队列;所述粒子追踪模块,用于在所述粒子文件读取完毕后,基于所述粒子队列执行粒子追踪计算;所述接收线程创建模块,用于在所述粒子文件读取完毕后,创建粒子接收线程以接收其他节点发送的粒子信息。
与现有技术相比,本申请的优点和积极效果是:本申请提出的超算集群上的粒子追踪方法和系统中,将超算集群节点建立为网格模型,每个网格对应一个节点,进而确定节点范围;每个节点在加载粒子时,与现有技术中加载全部粒子不同的是,本申请在加载之前首先通过粒子的初始位置坐标判断粒子是否属于本节点追踪范围,若属于则加载到粒子队列中,若不属于则丢弃,这样不但减少了节点加载粒子的数量,也能够降低内存使用量,并降低后续追踪计算中的判断计算量,以及后续节点交换粒子信息的交换量和通信时间,从而能够显著提高集群上执行粒子追踪计算的计算速度;另一方面,节点在加载了本节点负责追踪的粒子后,创建一个粒子接收线程,在计算线程基于粒子队列进行粒子追踪计算同时能够接收其他节点发送来的粒子信息,而计算线程中包含有将粒子信息发送给其他节点的步骤,故本申请中,粒子信息的发送和接收并行进行,这进一步提高了集群上执行粒子追踪计算的计算速度,解决了现有集群上执行粒子追踪计算存在计算速度慢的技术问题。
结合附图阅读本申请实施方式的详细描述后,本申请的其他特点和优点将变得更加清楚。
附图说明
图1为本申请提出的超算集群上的粒子追踪方法的方法流程图;
图2为本申请提出的网格模型的结构图;
图3为本申请提出的超算集群上的粒子追踪系统的系统框图。
具体实施方式
下面结合附图对本申请的具体实施方式作进一步详细地说明。
本申请提出的超算集群上的粒子追踪方法,旨在通过结合加载粒子前的判断,以及并行收发粒子信息的技术手段,达到降低数据处理量,提高计算速度的效果,具体的,如图1所示,对于超算集群中的所有节点均执行以下步骤:
步骤s1:解析粒子文件,按序读取粒子信息。
粒子文件为一个记载有所有粒子信息的列表,粒子信息例如粒子的编号、结构、初始位置坐标等信息,粒子文件以行为单位,每行对应一个粒子的信息。
每个节点在读取粒子文件时,按照顺序逐行读取粒子信息,并在读取一行粒子信息之后,执行步骤s2:基于粒子的初始位置坐标判断粒子是否属于本节点。
从粒子信息中解析出粒子的初始位置坐标,并根据初始位置坐标判断该粒子是否属于本节点追踪的粒子。
本申请实施例中,在追踪粒子计算之前,首先建立超算集群节点的网格模型,并设定网格模型中的每个网格对应一个节点,其中每个节点负责对一定区域或范围内的粒子进行追踪计算,也即需要根据网格模型设定每个节点的范围,只对范围内的粒子进行追踪,如图2所示的实施例给出的网格模型包括四个网格1、2、3、4,每个网格对应一个节点,每个节点的范围为0.5,其中节点1的范围从0到0.5,其他节点类推。
还需定义粒子的结构,并在所有节点总和范围内,也即在建立的网格模型中确定出每个粒子的初始位置;当粒子被读取并解析出其初始位置坐标时,能够根据初始位置坐标确定其处于哪个节点范围内,从而能够确定其是否属于读取节点要处理的范围内。
作为一个优选的实施例,本申请将每个网格划分为若干三角形,每个三角形限定一个范围,并为每个三角形编号,也即为每个三角形分配id,当读取粒子信息解析到粒子的初始位置坐标后,首先判断其落于哪个三角形范围内,从而能够确定所属三角形的id,最后基于三角形的id判断粒子是否属于本节点,以此方式缩小了粒子初始位置坐标的查找范围,提高判断的效率。
上述,若判断粒子属于本节点处理范围,则
步骤s3:加载粒子到粒子队列;若否,则抛弃不加载;如此重复步骤s1至步骤s3,按照顺序每次读取一行粒子信息,并判断其是否属于本节点处理范围,属于则加载到本节点的粒子队列中,不属于则抛弃,直至粒子文件读取完毕。
粒子文件读取完毕后,并行执行以下两个步骤,步骤s4:创建粒子接收线程,以接收其他节点发送的粒子信息;以及,步骤s5、基于粒子队列执行粒子追踪计算。
网格模型中的每个节点,在读取粒子文件完成,并加载了属于本节点处理范围的粒子队列后,开始执行粒子追踪计算,并均建立一个属于本节点的粒子接收线程,以实现在追踪计算同时,接收其他节点发送来的粒子信息。
上述可见,本申请提出的超算集群上的粒子追踪方法中,每个节点在加载粒子时,与现有技术中加载全部粒子不同的是,本申请在加载之前首先通过粒子的初始位置坐标判断粒子是否属于本节点追踪范围,若属于则加载到粒子队列中,若不属于则丢弃,这样不但减少了节点加载粒子的数量,也能够降低内存使用量,并降低后续追踪计算中的判断计算量,以及后续节点交换粒子信息的交换量和通信时间,从而能够显著提高集群上执行粒子追踪计算的计算速度,解决了现有集群上执行粒子追踪计算存在计算速度慢的技术问题。
另一方面,节点在加载了本节点负责追踪的粒子后,创建一个粒子接收线程,在计算线程基于粒子队列进行粒子追踪计算同时能够接收其他节点发送来的粒子信息,而本申请中,在步骤s5执行完粒子追踪计算之后,还执行步骤s6:判断执行粒子追踪计算后的粒子是否还属于本节点,若因为粒子随流体的运动,存在已经不属于本节点追踪范围内的粒子,则向其他节点发送这些执行完粒子追踪后不属于本节点的粒子信息,可见,则本申请步骤s5中,计算线程中还包含有将粒子信息发送给其他节点的步骤。
由于粒子随流体运行的特点,粒子可能在本节点追踪计算之后移动到其他节点负责计算的范围内,也存在其他节点追踪完成后移动到本节点计算追踪的范围内,故一个节点在执行粒子追踪之后,除了需要将本节点的部分粒子发送出去,也要接收从其他节点发送的粒子,本申请实施例的步骤s4在创建了粒子接收线程之后,粒子接收线程执行步骤s7:接收从其他节点发送来的粒子信息,并判断接收的粒子是否属于本节点;若是,则将接收的粒子加载到粒子队列,并执行步骤s5。
上述可见,粒子接收线程的创建使得本申请中,粒子信息的发送和接收并行进行,这进一步提高了集群上执行粒子追踪计算的计算速度。
基于上述提出的超算集群上的粒子追踪方法,本申请还提出一种超算集群上的粒子追踪系统,超算集群包括若干个节点3,如图3所示,该系统包括读取模块31、判断模块32、加载模块33、粒子追踪模块34和接收线程创建模块35。
对于超算集群的所有节点3,读取模块31用于解析粒子文件,按序读取粒子信息;判断模块32用于基于粒子的初始位置坐标判断粒子是否属于本节点;加载模块33用于加载粒子到粒子队列;粒子追踪模块34用于在粒子文件读取完毕后,基于粒子队列执行粒子追踪计算;接收线程创建模块35用于在粒子文件读取完毕后,创建粒子接收线程以接收其他节点发送的粒子信息。
该系统还包括网格模型建立模块36、粒子结构定义模块37和粒子初始位置确定模块38;网格模型建立模块36用于建立超算集群节点的网格模型;粒子结构定义模块37用于定义粒子结构;粒子初始位置确定模块38用于基于粒子结构确定每个粒子在网格模型中的初始位置。
具体的,网格模型建立模块36包括设定单元361和网格划分单元362;设定单元361用于设定每个网格对应一个节点,并设定节点范围;网格划分单元362用于将每个网格划分为若干三角形;则判断模块32具体用于基于粒子的初始位置坐标判断粒子所属三角形的id;基于三角形的id判断粒子是否属于本节点。
本申请实施例中,粒子接收线程具体用于,在接收其他节点发送的粒子信息后,判断接收的粒子是否属于本节点,若是,则将接收的粒子加载到粒子队列,若否,则抛弃。
本申请实施例中,粒子追踪模块34包含有粒子发送单元341,用于判断执行粒子追踪计算后的粒子是否还属于本节点,若否,则向其他节点发送执行粒子追踪后不属于本节点的粒子信息。
具体的超算集群上的粒子追踪系统的粒子追踪方法,已经在上述提出的超算集群上的粒子追踪方法中详述,此处不予赘述。
上述本申请提出的超算集群上的粒子追踪方法和系统,每个节点在加载粒子时首先通过粒子的初始位置坐标判断粒子是否属于本节点追踪范围,若属于则加载到粒子队列中,若不属于则丢弃,这样不但减少了节点加载粒子的数量,也能够降低内存使用量,并降低后续追踪计算中的判断计算量,以及后续节点交换粒子信息的交换量和通信时间,从而能够显著提高集群上执行粒子追踪计算的计算速度;节点在加载了本节点负责追踪的粒子后,创建一个粒子接收线程,在计算线程基于粒子队列进行粒子追踪计算同时能够接收其他节点发送来的粒子信息,而计算线程中包含有将粒子信息发送给其他节点的步骤,故本申请中,粒子信息的发送和接收并行进行,进一步提高了集群上执行粒子追踪计算的计算速度,解决了现有集群上执行粒子追踪计算存在计算速度慢的技术问题。
应该指出的是,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的普通技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!