一种对非平衡数据集的分类方法及系统与流程
本发明涉及非平衡数据处理技术领域,尤其涉及一种对非平衡数据集的分类方法及系统。
背景技术:
许多行业数据往往存在着数据分布不平衡现象。以二分类问题为例,其中一种样本所占的比例如果远远大于另一种样本所占的比例,则该数据集为非平衡数据集。其中,多数类样本也称为负类样本,少数类样本称为正类样本,负类样本与正类样本数之比称为不平衡率(ir,imbalancedrate)。典型例子包括:故障诊断数据、信用欺诈数据、医疗诊断数据等。由于对非平衡数据集进行分类预测时,少数类的分类预测准确率在实际中的参考价值更重要,但常用的分类预测模型通常对多数类的预测准确率更高,少数类的预测准确率偏低,而少数类的预测错误通常会带来更大的经济损失,甚至带来生命代价,如信用卡盗刷事故、煤矿突水及瓦斯突出事故等。因此,如何提高非平衡数据集少数类的分类预测准确率是近年来国内外的研究热点。
batuwita等人提出一种用于处理非平衡数据集的模糊支持向量机(即fsvm),为正负样本设置了不同的惩罚因子,设计模糊隶属度函数赋予训练样本不同的隶属度,但这种设计模糊隶属度函数方法仅仅考虑了样本与类中心的距离和样本非平衡性的情况,并没有考虑样本的分布特性,分类准确性差。蔡艳艳等人提出了新型双隶属度模糊支持向量机,有效提高了分类准确率,但也增加了复杂度,分类效率较低。
技术实现要素:
本发明的目的是提供一种对非平衡数据集的分类方法及系统,以解决现有技术中对非平衡数据集进行分类时效率低及准确性差的问题。
为实现上述目的,本发明提供了如下方案:
一种对非平衡数据集的分类方法,包括:
获取样本非平衡数据;所述样本非平衡数据包括正类数据和负类数据;所述正类数据表示所述样本非平衡数据中数量较少的一类数据,所述负类数据表示所述样本非平衡数据中数量较多的一类数据;
对样本非平衡数据进行随机划分得到训练集和测试集;所述训练集包括正类训练集和负类训练集;所述测试集包括正类测试集和负类测试集;
获取所述正类训练集的类中心c1和所述负类训练集的类中心c2以及所述训练集的中心c;
将所述类中心c1与所述训练集的中心c之差确定为正类超平面法向量w1,将所述类中心c2与所述训练集的中心c之差确定为负类超平面法向量w2,将所述类中心c1与所述类中心c2之差的模确定为两类类中心的距离t;
根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面和经过所述类中心c2的负类超平面;
根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离di+、第二距离di-、第三距离dli+和第四距离dli-;所述第一距离di+表示所述正类训练集中的正类数据到所述正类超平面的距离;所述第二距离di-表示所述负类训练集中的负类数据到所述负类超平面的距离;所述第三距离dli+表示所述正类训练集中的正类数据经过所述类中心c2到所述负类超平面的距离;所述第四距离dli-表示所述负类训练集中的负类数据经过类中心c1到所述正类超平面的距离;
根据近邻算法确定正类训练集中正类数据的紧密度ci+,根据近邻算法确定负类训练集中负类数据的紧密度ci-;
根据所述第一距离di+、所述第二距离di-、所述第三距离dl+、所述第四距离dl-所述紧密度ci+、所述紧密度ci-和所述两类类中心的距离t确定模糊隶属度函数(1),
其中,si+表示正类数据模糊隶属度,si-表示负类数据模糊隶属度,ε表示半径控制因子,σ表示样本权值赋予参数;
根据所述模糊隶属度函数(1)及模糊双支持向量机确定分类模型(2),
其中,ftwsvm1表示正类分类超平面,a表示第一待分类数据,w1表示正类分类超平面的法向量,e1表示元全部等于1的正类列向量,b1表示第一常数,d1表示第一惩罚参数,sa表示第一待分类数据的模糊隶属度,ξ表示松弛因子,s.t.表示约束条件,b表示第二待分类数据,e2表示元全部等于1的负类列向量,ftwsvm2表示负类分类超平面,w2表示负类分类超平面的法向量,b2表示第二常数,d2表示第二惩罚参数,sb表示第二待分类数据的模糊隶属度;
以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以测试集的查全率、查准率、g-mean和f值作为分类模型(2)的输出,采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型;
获取待测非平衡数据;
以所述待测非平衡数据作为所述优化后的分类模型的输入,得到对所述待测非平衡数据的分类结果。
可选的,所述根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面和经过所述类中心c2的负类超平面,具体包括:
根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面w1x++b1=1(3)和经过所述类中心c2的负类超平面w2x-+b2=-1(4);其中,x+表示正类训练集中的正类数据,x-表示负类训练集中的负类数据。
可选的,所述根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离di+、第二距离di-、第三距离dli+和第四距离dli-,具体包括:
根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离
可选的,所述根据近邻算法确定正类训练集中正类数据的紧密度ci+,根据近邻算法确定负类训练集中负类数据的紧密度ci-,具体包括:
根据近邻算法确定正类训练集中正类数据的紧密度
可选的,所述以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以测试集的查全率、查准率、g-mean和f值作为分类模型(2)的输出,采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型,具体包括:
以样本非平衡数据的训练集和测试集作为分类模型(2)模型(2)的输入,以正类测试集的查全率
一种对非平衡数据集的分类系统,包括:
第一获取模块,用于获取非平衡数据;所述非平衡数据包括正类数据和负类数据;所述正类数据表示所述样本非平衡数据中数量较少的一类数据,所述负类数据表示所述样本非平衡数据中数量较多的一类数据;
训练集和测试集生成模块,用于对样本非平衡数据进行随机划分得到训练集和测试集;所述训练集包括正类训练集和负类训练集;所述测试集包括正类测试集和负类测试集
第二获取模块,用于获取所述正类训练集的类中心c1和所述负类训练集的类中心c2以及所述训练集的中心c;
法向量和两类类中心的距离t确定模块,用于将所述类中心c1与所述训练集的中心c之差确定为正类超平面法向量w1,将所述类中心c2与所述训练集的中心c之差确定为负类超平面法向量w2,将所述类中心c1与所述类中心c2之差的模确定为两类类中心的距离t;
超平面确定模块,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面和经过所述类中心c2的负类超平面;
距离确定模块,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离di+、第二距离di-、第三距离dli+和第四距离dli-;所述第一距离di+表示所述正类训练集中的正类数据到所述正类超平面的距离;所述第二距离di-表示所述负类训练集中的负类数据到所述负类超平面的距离;所述第三距离dli+表示所述正类训练集中的正类数据经过所述类中心c2到所述负类超平面的距离;所述第四距离dli-表示所述负类训练集中的负类数据经过类中心c1到所述正类超平面的距离;
紧密度确定模块,用于根据近邻算法确定正类训练集中正类数据的紧密度ci+,根据近邻算法确定负类训练集中负类数据的紧密度ci-;
模糊隶属度函数确定模块,用于根据所述第一距离di+、所述第二距离di-、所述第三距离dli+、所述第四距离dli-、所述紧密度ci+、所述紧密度ci-和所述两类类中心的距离t确定模糊隶属度函数(1),
其中,si+表示正类数据模糊隶属度,si-表示负类数据模糊隶属度,ε表示半径控制因子,σ表示样本权值赋予参数;
分类模型确定模块,用于根据所述模糊隶属度函数(1)及模糊双支持向量机确定分类模型(2),
其中,ftwsvm1表示正类分类超平面,a表示第一待分类数据,w1表示正类分类超平面的法向量,e1表示元全部等于1的正类列向量,b1表示第一常数,d1表示第一惩罚参数,sa表示第一待分类数据的模糊隶属度,ξ表示松弛因子,s.t.表示约束条件,b表示第二待分类数据,e2表示元全部等于1的负类列向量,ftwsvm2表示负类分类超平面,w2表示负类分类超平面的法向量,b2表示第二常数,d2表示第二惩罚参数,sb表示第二待分类数据的模糊隶属度;
优化后的分类模型生成模块,用于以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以测试集的查全率、查准率、g-mean和f值作为分类模型(2)的输出,采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型;
第三获取模块,用于获取待测非平衡数据;
分类结果生成模块,用于以所述待测非平衡数据作为所述优化后的分类模型的输入,得到对所述待测非平衡数据的分类结果。
可选的,所述超平面确定模块具体包括:
正类超平面和负类超平面确定单元,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面w1x++b1=1(3)和经过所述类中心c2的负类超平面w2x-+b2=-1(4);其中,x+表示正类训练集中的正类数据,x-表示负类训练集中的负类数据。
可选的,所述距离确定模块,具体包括:
距离确定单元,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离
可选的,所述紧密度确定模块,具体包括:
正类数据的紧密度确定单元,用于根据近邻算法确定正类训练集中正类数据的紧密度
负类数据的紧密度确定单元,用于根据近邻算法确定负类训练集中负类数据的紧密度
可选的,所述优化后的分类模型生成模块,具体包括:
优化后的分类模型生成单元,用于以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以正类测试集的查全率
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明的对非平衡数据集的分类方法及系统,计算获得正类和负类训练集的类中心c1和c2以及训练集中心c,进而确定两类类中心的距离t、正类超平面、负类超平面、第一距离、第二距离、第三距离和第四距离,根据近邻算法确定正类数据和负类数据的紧密度ci+和ci-。根据第一距离、第二距离、紧密度ci+、ci-和两类类中心的距离t确定模糊隶属度函数(1),根据模糊隶属度函数(1)及模糊双支持向量机确定分类模型(2)。采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型。将待分类的非平衡数据输入优化后的分类模型,得到对待分类的非平衡数据的分类结果。本发明的方法或系统通过使用基于模糊隶属度函数的确定分类模型,根据样本点对分类超平面贡献的不同和两类样本非平衡率的不同赋予样本点不同的隶属度值,减轻了样本间的不平衡性,降低了样本中含有的噪声点对分类超平面的影响,从而提高了使用本发明的方法或系统时的分类结果的准确性。
本发明的方法或系统还通过本发明的方法或系统通过使用基于模糊隶属度函数和模糊双支持向量机的确定分类模型,对两个二次规划问题做处理,大大降低了算法的复杂度,提高了运算效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
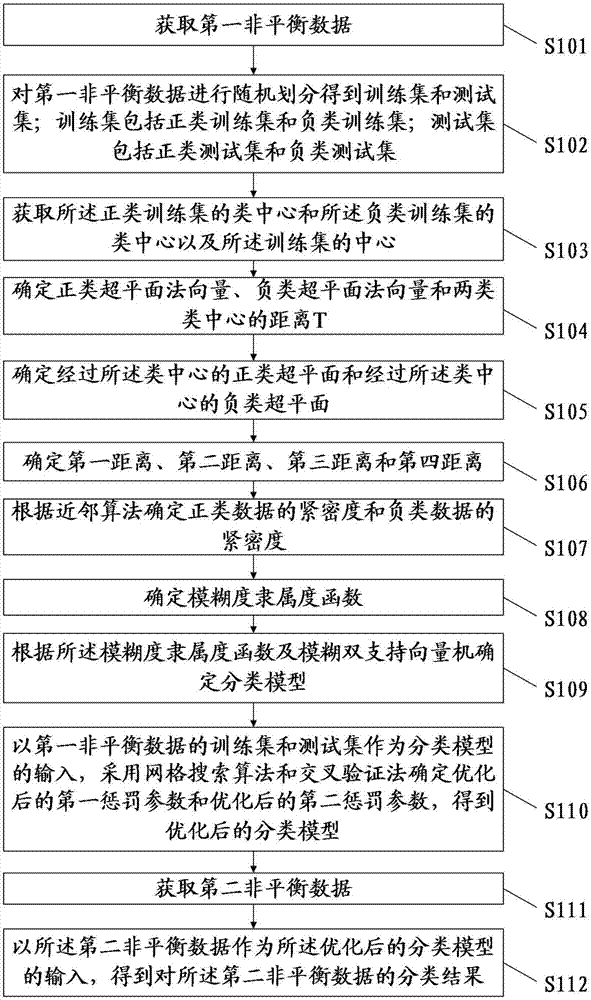
图1为本发明所提供的对非平衡数据集的分类方法流程图;
图2为本发明所提供的对非平衡数据集的分类系统结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种对非平衡数据集的分类方法及系统,以解决现有技术中对非平衡数据集进行分类时效率低及准确性差的问题。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明所提供的对非平衡数据集的分类方法流程图。如图1所示,一种对非平衡数据集的分类方法,包括:
步骤s101:获取样本非平衡数据;本实施例中选取casia汉语情感语料库中的生气情感样本作为正类样本,casia汉语情感语料库中的剩余种类的情感样本作为负类样本。选取样本语音的mfcc特征,音质特征还有韵律特征,分别对应求得语音特征的均值,方差以及标准差三种特征值,得到非平衡数据。非平衡数据中包括正类数据和负类数据。负类数据多于正类数据。
步骤s102:对样本非平衡数据进行随机划分得到训练集和测试集;所述训练集包括正类训练集和负类训练集;所述测试集包括正类测试集和负类测试集;
步骤s103:获取所述正类训练集的类中心c1和所述负类训练集的类中心c2以及所述训练集的中心c。
步骤s104:将所述类中心c1与所述训练集的中心c之差确定为正类超平面法向量w1,将所述类中心c2与所述训练集的中心c之差确定为负类超平面法向量w2,将所述类中心c1与所述类中心c2之差的模确定为两类类中心的距离t。
步骤s105:根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面和经过所述类中心c2的负类超平面。
步骤s106:根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离di+、第二距离di-、第三距离dli+和第四距离dli-;所述第一距离di+表示所述正类训练集中的正类数据到所述正类超平面的距离;所述第二距离di-表示所述负类训练集中的负类数据到所述负类超平面的距离;所述第三距离dli+表示所述正类训练集中的正类数据经过所述类中心c2到所述负类超平面的距离;所述第四距离dli-表示所述负类训练集中的负类数据经过类中心c1到所述正类超平面的距离;
步骤s107:根据近邻算法确定正类训练集中正类数据的紧密度ci+,根据近邻算法确定负类训练集中负类数据的紧密度ci-。
步骤s108:根据所述第一距离di+、所述第二距离di-、所述第三距离dli+、所述第四距离dli-、所述紧密度ci+、所述紧密度ci-和所述两类类中心的距离t确定模糊隶属度函数(1),
其中,si+表示正类数据模糊隶属度,si-表示负类数据模糊隶属度,ε表示半径控制因子,σ表示样本权值赋予参数;ε可起到对数据集预处理的作用,将大部分有效样本控制在超球体内;σ为一个很小的数,结合k近邻准则,对样本点进行权值赋予。
步骤s109:根据所述模糊隶属度函数(1)及模糊双支持向量机确定分类模型(2),
其中,ftwsvm1表示正类分类超平面,a表示第一待分类数据,w1表示正类分类超平面的法向量,e1表示元全部等于1的正类列向量,b1表示第一常数,d1表示第一惩罚参数,sa表示第一待分类数据的模糊隶属度,ξ表示松弛因子,s.t.表示约束条件,b表示第二待分类数据,e2表示元全部等于1的负类列向量,ftwsvm2表示负类分类超平面,w2表示负类分类超平面的法向量,b2表示第二常数,d2表示第二惩罚参数,sb表示第二待分类数据的模糊隶属度。
步骤s110:以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以测试集的查全率、查准率、g-mean和f值作为分类模型(2)的输出,采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型。
步骤s111:获取待测非平衡数据;本实施例中选取太原理工大学tyut2.0情感语音数据库中的高兴情感样本作为正类样本,太原理工大学tyut2.0情感语音数据库中的剩余种类的情感样本作为负类样本。选取样本语音的mfcc特征,音质特征还有韵律特征,分别对应求得语音特征的均值,方差以及标准差三种特征值,得到非平衡数据。非平衡数据中包括正类数据和负类数据。负类数据多于正类数据。
步骤s112:以所述待测非平衡数据作为所述优化后的分类模型的输入,得到对所述待测非平衡数据的分类结果。
本实施例的方法通过使用基于模糊隶属度函数的确定分类模型,根据样本点对分类超平面贡献的不同和两类样本非平衡率的不同赋予样本点不同的隶属度值,减轻了样本间的不平衡性,降低了样本中含有的噪声点对分类超平面的影响,从而提高了使用本发明的方法时的分类结果的准确性。本实施例的方法还通过使用基于模糊隶属度函数和模糊双支持向量机的确定分类模型,对两个二次规划问题做处理,大大降低了算法的复杂度,提高了运算效率。
在实际应用中,根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面w1x++b1=1(3)和经过所述类中心c2的负类超平面w2x-+b2=-1(4);其中,x+表示正类训练集中的正类数据,x-表示负类训练集中的负类数据。
根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离
根据近邻算法确定正类训练集中正类数据的紧密度
以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以正类测试集的查全率
recall,precision分别代表分类器正确预测正负类样本的比率,但很多时候具有高recall的分类器不一定有高的precision,故引入几何均值g-mean来评价分类器性能,g-mean越大,分类效果越好。f-value考虑的是少数类的查全率和查准率的结合。
本实施例中,提供了第一距离di+、所述第二距离di-、第三距离dli+、所述第四距离dli-、所述紧密度ci+、所述紧密度ci-的具体计算公式,还提供了分类结果中包含的查全率、查准率、g-mean和f值的具体计算方法。
在实际应用中,以模糊双支持向量机(ftwsvm)模型为基础,引入模糊隶属度函数(1),重新构造分类模型,包括:
原始twsvm模型将平行约束条件舍弃,对于二分类问题,构建两个非平行超平面,构造原则是令其距离本类样本点尽可能的近,距离另一类尽可能远,令属于1类和-1类样本分别由a、b两个矩阵所表示,其最优化问题构造为公式(3):
其中,d1,d2为惩罚参数,e1,e2是全为1的列向量。通过优化上式可得其分类:
w1x++b1=1;w2x-+b2=-1。
w1x++b1=1和w2x-+b2=-1为求得的分类超平面,通过求得分类超平面将数据分为两类。
在此基础上,引入模糊隶属度函数sa、sb,则分类模型的分类超平面优化问题可以表示为公式(2)。
其中sa、sb为a、b样本每个样本的模糊隶属度,样本误差与隶属度的积表示样本点对分类器所做的贡献大小。拉格朗日变换求对偶,问题表述为
xtwr+br=min|xtwl+bl|l=1,2(5);
其中|.|为x到平面xtwl+bl=0,(l=1,2)的垂直距离。
本实施例提供了分类模型的具体推导过程,本实施例的方法还通过本发明的方法或系统通过使用基于模糊隶属度函数和模糊双支持向量机的确定分类模型,对两个二次规划问题做处理,若两类样本数目相同,其时间可比svm快4倍,大大降低了算法的复杂度,提高了运算效率。
图2为本发明所提供的对非平衡数据集的分类系统结构图。如图2所示,一种对非平衡数据集的分类系统,包括:
第一获取模块1,用于获取非平衡数据;所述非平衡数据包括正类数据和负类数据;所述正类数据表示所述样本非平衡数据中数量较少的一类数据,所述负类数据表示所述样本非平衡数据中数量较多的一类数据;
训练集和测试集生成模块2,用于对样本非平衡数据进行随机划分得到训练集和测试集;所述训练集包括正类训练集和负类训练集;所述测试集包括正类测试集和负类测试集
第二获取模块3,用于获取所述正类训练集的类中心c1和所述负类训练集的类中心c2以及所述训练集的中心c;
法向量和两类类中心的距离t确定模块4,用于将所述类中心c1与所述训练集的中心c之差确定为正类超平面法向量w1,将所述类中心c2与所述训练集的中心c之差确定为负类超平面法向量w2,将所述类中心c1与所述类中心c2之差的模确定为两类类中心的距离t;
超平面确定模块5,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面和经过所述类中心c2的负类超平面;
距离确定模块6,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离di+、第二距离di-、第三距离dli+和第四距离dli-;所述第一距离di+表示所述正类训练集中的正类数据到所述正类超平面的距离;所述第二距离di-表示所述负类训练集中的负类数据到所述负类超平面的距离;所述第三距离dli+表示所述正类训练集中的正类数据经过所述类中心c2到所述负类超平面的距离;所述第四距离dli-表示所述负类训练集中的负类数据经过类中心c1到所述正类超平面的距离;
紧密度确定模块7,用于根据近邻算法确定正类训练集中正类数据的紧密度ci+,根据近邻算法确定负类训练集中负类数据的紧密度ci-;
模糊隶属度函数确定模块8,用于根据所述第一距离di+、所述第二距离di-、所述第三距离dli+、所述第四距离dli-、所述紧密度ci+、所述紧密度ci-和所述两类类中心的距离t确定模糊隶属度函数(1),
其中,si+表示正类数据模糊隶属度,si-表示负类数据模糊隶属度,ε表示半径控制因子,σ表示样本权值赋予参数;
分类模型确定模块9,用于根据所述模糊隶属度函数(1)及模糊双支持向量机确定分类模型(2),
其中,ftwsvm1表示正类分类超平面,a表示第一待分类数据,w1表示正类分类超平面的法向量,e1表示元全部等于1的正类列向量,b1表示第一常数,d1表示第一惩罚参数,sa表示第一待分类数据的模糊隶属度,ξ表示松弛因子,s.t.表示约束条件,b表示第二待分类数据,e2表示元全部等于1的负类列向量,ftwsvm2表示负类分类超平面,w2表示负类分类超平面的法向量,b2表示第二常数,d2表示第二惩罚参数,sb表示第二待分类数据的模糊隶属度;
优化后的分类模型生成模块10,用于以样本非平衡数据的训练集和测试集作为分类模型(2)的输入,以测试集的查全率、查准率、g-mean和f值作为分类模型(2)的输出,采用网格搜索算法和交叉验证法确定优化后的第一惩罚参数d1和优化后的第二惩罚参数d2,得到优化后的分类模型;
第三获取模块11,用于获取待测非平衡数据;
分类结果生成模块12,用于以所述待测非平衡数据作为所述优化后的分类模型的输入,得到对所述待测非平衡数据的分类结果。
本实施例的系统通过使用基于模糊隶属度函数的确定分类模型,根据样本点对分类超平面贡献的不同和两类样本非平衡率的不同赋予样本点不同的隶属度值,减轻了样本间的不平衡性,降低了样本中含有的噪声点对分类超平面的影响,从而提高了使用本发明的系统时的分类结果的准确性。本实施例中的系统通过使用基于模糊隶属度函数和模糊双支持向量机的确定分类模型,对两个二次规划问题做处理,大大降低了算法的复杂度,提高了运算效率。
在实际应用中,所述超平面确定模块具体包括:正类超平面和负类超平面确定单元用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定经过所述类中心c1的正类超平面w1x++b1=1(3)和经过所述类中心c2的负类超平面w2x-+b2=-1(4);其中,x+表示正类训练集中的正类数据,x-表示负类训练集中的负类数据。
距离确定模块,具体包括:距离确定单元,用于根据所述类中心c1、所述类中心c2、所述法向量w1和所述法向量w2确定第一距离
所述紧密度确定模块,具体包括:正类数据的紧密度确定单元,用于根据近邻算法确定正类训练集中正类数据的紧密度
负类数据的紧密度确定单元,用于根据近邻算法确定负类训练集中负类数据的紧密度
所述优化后的分类模型生成模块,具体包括:优化后的分类模型生成单元,用于以样本非平衡数据的训练集和测试作为分类模型(2)输入,以正类测试集的查全率
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!