一种基于聚类的BGP人脸快速检索方法与流程
本发明涉及人脸识别技术领域,尤其涉及一种基于聚类的bgp人脸快速检索方法。
背景技术:
近年来人脸识别始终是图像处理、计算机视觉、模式识别、认知科学等领域研究的热点问题,广泛应用在安全验证、快捷支付、视频调查、个人鉴定等场合,其中一种广泛应用的人脸识别场景即是给定一张待检索图片,快速从数据库中检索到相似图片,这类问题即为基于人脸的快速检索。
目前实现快速检索方法主要包含以下几类:1)基于词袋模型的检索方法;2)基于kd树的检索方法;3)基于向量聚类和量化的检索方法;4)基于哈希的检索方法。上述几类快速检索方法通常实现复杂,且快速检索的对象通常是cifar-10、inriaholidays等以场景为主的数据库图片,通常不适用于实现人脸图像的快速检索,而由于人脸具有易变性质,对人脸的特征提取和描述易受表情、光照等影响,尤其是大型人脸数据库中人脸姿态、表情变化较剧烈,很难提取稳定的描述子进行快速检索,直接适用当前的快速检索方法来进行人脸快速检索并不能实现精确的检索。
目前的人脸识别算法可以分为以下几类:1)基于人脸局部特征的识别方法,如局部二值模式(localbinarypattern,简称lbp)、弹性图匹配、二进制梯度模式(binarygradientpattern,简称bgp)等方法;2)基于人脸全局特征的识别方法,如线性判别分析(lineardiscriminantanalysis,简称lda)、主成分分析(principlecomponentanalysis,简称pca)、独立成分分析(independentcomponentanalysis,简称ica)等方法;3)基于全局特征和局部特征结合的方法,如基于特征脸和五官特征结合的方法;4)基于深度学习的方法,如facenet的提出和应用。人脸识别的精度、效率取决于所采用的识别算法,而通常识别精度高的算法所需的时间也相应的较长,即识别速率较慢,直接使用上述几类人脸识别算法均难以兼顾识别精度以及识别效率。因此如何能够保证人脸检索精度的同时,提高人脸检索效率是亟待解决的问题。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种实现方法简单、能够结合聚类与bgp实现人脸快速检索,且检索性能好的基于聚类的bgp人脸快速检索方法。
为解决上述技术问题,本发明提出的技术方案为:
一种基于聚类的bgp人脸快速检索方法,步骤包括:
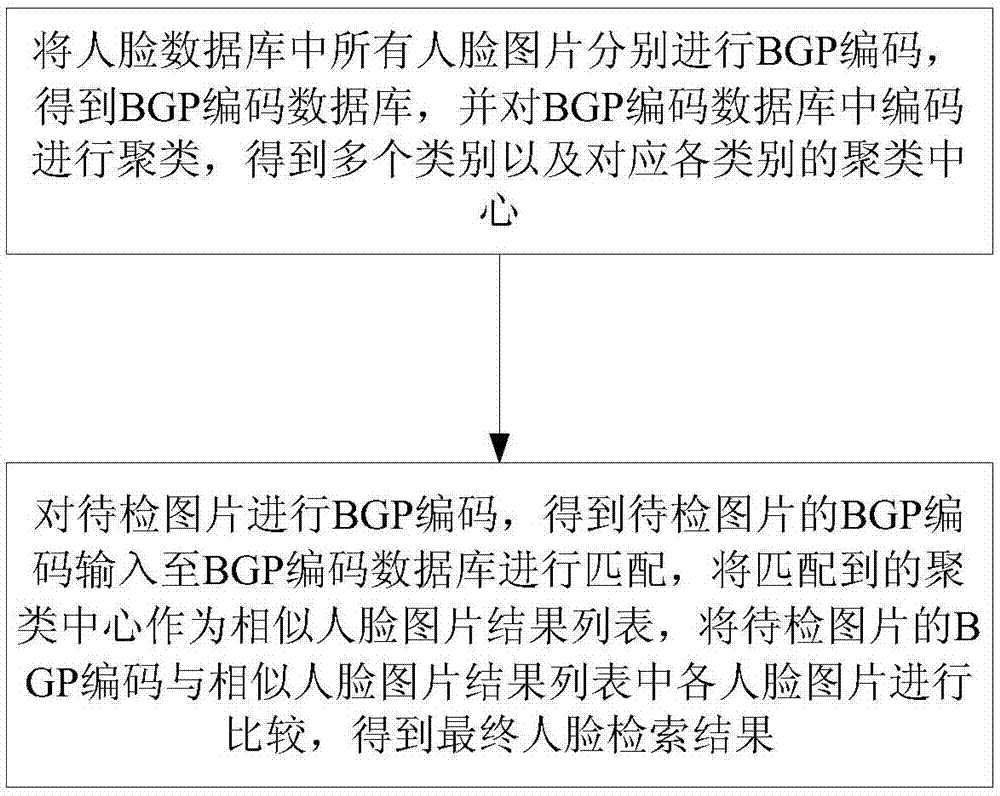
s1.特征库聚类:将人脸数据库中人脸图片分别进行bgp编码,得到bgp编码数据库,并对所述bgp编码数据库中编码进行聚类,得到多个类别以及对应各类别的聚类中心;
s3.人脸检索:对待检图片进行bgp编码,得到待检图片的bgp编码输入至所述bgp编码数据库进行匹配,将匹配到的聚类中心作为相似人脸图片结果列表,将所述待检图片的bgp编码与所述相似人脸图片结果列表中各人脸图片进行比较,得到最终人脸检索结果。
作为本发明的进一步改进:所述进行bgp编码为使用bgp算法对输入图片进行编码,得到bgp编码值,每个bgp编码值包含有像素的强度信息以及邻域像素关系的信息。
作为本发明的进一步改进,所述进行bgp编码的步骤包括:
基于bgp算法对输入图片进行特征提取,得到bgp特征图像;
将所述bgp特征图像分成互不重叠的子块;
统计每个子块的bgp直方图,得到对应各子块的直方图;
将所有子块的直方图按顺序进行拼接,得到最终的bgp编码值。
作为本发明的进一步改进:所述步骤s1中具体采用k均值聚类方法进行聚类。
作为本发明的进一步改进,所述采用k均值聚类方法进行聚类时,先在所述bgp编码数据库中随机挑选k个初始聚类中心,根据与k个聚类中心的距离将所述bgp编码数据库中各bgp编码划分到各所述聚类中心所属的类,形成k个聚类簇,对每个聚类簇重新计算聚类中心,再根据新的聚类中心重新划分各所述bgp编码,不断迭代直到最大迭代次数或聚类中心不再发生变化。
作为本发明的进一步改进,所述采用k均值聚类方法进行聚类的具体步骤为:
s11.随机选取所述bgp编码数据库中k个bgp编码并作为初始聚类中心,得到k个聚类中心;
s12.分别计算所述bgp编码数据库中每个bgp编码与所述k个聚类中心的距离,若满足目标bgp编码与目标聚类中心的距离最小,则将目标bgp编码划分至目标聚类中心所属的类中,形成k个初始聚类簇;
s13.对当前每个聚类簇重新计算聚类中心,得到k个更新后的聚类中心:
s14.判断是否达到所需最大迭代次数,若是退出聚类,否则判断当前得到的聚类中心与上一次迭代得到的聚类中心是否有变化,若有变化,返回执行步骤s12以进行下一次迭代计算,否则退出聚类。
所述步骤s1采用离线执行,得到包含多个类别以及对应聚类中心的bgp编码数据库进行存储,所述步骤s2在线对待检图片调用步骤s1得到的bgp编码数据库进行人脸检索。
作为本发明的进一步改进,所述步骤s2的步骤包括:
s21.对待检图片进行bgp编码,得到待检图片的bgp编码;
s22.将所述待检图片的bgp编码输入至所述bgp编码数据库进行匹配,输出与所述待检图片的bgp编码匹配的聚类中心并作为相似人脸图片结果列表;
s23.将所述相似人脸图片结果列表中各人脸图片分别与所述待检图片的bgp编码进行匹配比较,由匹配得到的人脸图片得到最终人脸检索结果。
所述步骤s22中进行匹配时,计算所述待检图片的bgp编码与所述bgp编码数据库中各聚类中心的距离,由距离最近的聚类中心作为匹配到的聚类中心。
与现有技术相比,本发明的优点在于:
1、本发明基于聚类的bgp人脸快速检索方法,基于bgp编码实现人脸识别,bgp能够鲁棒、简洁描述人脸并提取人脸特征,通过bgp来对人脸编码能够保证编码的准确性和简洁性,可以充分利用bgp编码的特性实现精确的人脸识别,同时考虑人脸检索的效率问题,通过结合聚类的方式来将数据库中相似度较高的编码聚为一类,进行人脸检索时,将待检图片与各个聚类中心进行匹配,在匹配到对应的聚类中心后再进行精确的识别,可以快速的定位到检索人脸目标,实现过程简单,能够在保证检索精度的同时,实现快速检索。
2、本发明基于聚类的bgp人脸快速检索方法,进一步结合k均值聚类方法,能够提高聚类的效率及效果,将相似度较高的编码高效的聚为一类,充分结合bgp人脸特征提取和k均值聚类方法的优势,能够在鲁棒、准确描述人脸的同时,显著提高人脸检索效率。
附图说明
图1是本实施例基于聚类的bgp人脸快速检索方法的实现流程示意图。
图2是bgp基本描述子的原理示意图。
图3是本实施例中bgp求特征向量的实现流程示意图。
图4是本实施例中k均值算法的实现流程示意图。
图5是本实施例基于聚类的bgp人脸快速检索方法的实现流程示意图。
图6是本发明具体应用实施例中采用的yale中一个人部分图像的示意图。
图7是在具体实施例中选取的目标图像示意图。
图8是在具体实施例中采用传统方法检索得到的检索结果图。
图9是在具体实施例中采用本发明检索方法得到的检索结果图。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图1所示,本实施例基于聚类的bgp人脸快速检索方法步骤包括:
s1.特征库聚类:将人脸数据库中人脸图片分别进行bgp编码,得到bgp编码数据库,并对bgp编码数据库中编码进行聚类,得到多个类别以及对应各类别的聚类中心;
s3.人脸检索:对待检图片进行bgp编码,得到待检图片的bgp编码输入至所述bgp编码数据库进行匹配,将匹配到的聚类中心作为相似人脸图片结果列表,将待检图片的bgp编码与相似人脸图片结果列表中各人脸图片进行比较,得到最终人脸检索结果。
二进制梯度模式(bgp)是一种简洁高效的人脸描述子,二进制梯度模式具有计算简单、判别性强、鲁棒性好等特点,十分适合应用于难以区分的人脸识别中,bgp在图像梯度方向图中定义,具有良好的梯度特征,可以有效应对光照强度等变化;且在bgp中使用结构模式和多空间分辨率,结构化bgp作用相当于边缘检测器,这是准确识别和简洁表示的关键,同时多空间分辨率策略增加了描述符覆盖不同半径邻域像素的能力,使得基于bgp在人脸识别中能够取得较高的识别精度。
本实施例考虑bgp的上述特性,基于bgp编码实现人脸识别,bgp能够鲁棒、简洁描述人脸并提取人脸特征,通过bgp来对人脸编码能够保证编码的准确性和简洁性,可以充分利用bgp编码的特性实现精确的人脸识别,同时考虑人脸检索的效率问题,通过结合聚类的方式来将数据库中相似度较高的编码聚为一类,进行人脸检索时,将待检图片与各个聚类中心进行匹配,可以缩小后续的检索范围,在匹配到对应的聚类中心后再进行精确的识别,可以快速的定位到检索人脸目标,极大的提高检索效率,能够在保证检索精度的同时,实现快速检索。
bgp是基于图像梯度方向(igo)和二进制描述方式,其思想来源于gradientfaces新型描述符,该描述符用图像梯度方向(igo)取代像素强度来对人脸进行描述,以实现对照明变化的鲁棒性,即梯度域提取的特征比来自强度域的特征更具有判别性和鲁棒性。bgp算法中通过衡量图像梯度域中的局部像素之间的关系,并将底层局部结构有效编码为一组二进制字符串,不仅增加了判别力,更是大大简化了计算复杂度。
bgp中为了发现梯度域潜在结构,bgp是从多方向计算图像梯度,并将其编码为一系列二进制串,能够表示微小边界变化和纹理信息,因此具有很强的判别性,即使面对遮挡、光照、表情变化等,也能取得较好的识别精度,且由于采用bgp对图像进行编码时,每个编码值都蕴含了邻域像素关系的信息,而不仅仅是像素自身的强度信息,因此bgp编码后的图像对各种环境变化更鲁棒,尤其具有较强的光照不变性。
bgp的基本描述子如图2所示,其中(a)对应为一个中心像素的八个邻像素(值为115),(b)为四个方向,(c)为主要的二进制串,编码为0111,标签为7,bgp算法如下:
给定一个中心像素和一系列局部邻像素(比如图1中8个邻像素),然后根据公式(1),基于每个方向上的两个对称邻像素计算出一对二进制编码(主要的和辅助的),如图2的(b)(c)所示,从g1、g2、g3、g4等四个方向上可以得到4对二进制数:
再通过四个主要二进制编码得到中心像素的标签,即bgp二进制位表示如公式(2):
再如公式(3)转化为十进制数:
通过上述步骤,在四个方向上获得八个二进制数,每个方向上的主要和辅助的二进制数总是互补的,每个方向只需要一个二进制位来体现,为了简洁的表示,本实施例采用主要的二进制位来计算标签(根据公式(3))。
本实施例步骤s1、步骤s2中进行bgp编码时,即是采用如上述bgp算法对输入图片进行编码,得到bgp编码值,每个bgp编码值包含有像素的强度信息以及邻域像素关系的信息,从而可以有效提高人脸识别的判别性及鲁棒性。二进制梯度模式适用于灰度图像,对于彩色图像需首先转换为灰度图像。由于采用bgp对图像进行编码时,每个编码值都蕴含了邻域像素关系的信息,而不仅仅是像素自身的强度信息,因此bgp编码后的图像对各种环境变化更鲁棒,尤其具有较强的光照不变性。
如图3所示,本实施例中进行bgp编码的具体步骤为:
基于bgp算法对输入图片进行特征提取,得到bgp特征图像;
将所述bgp特征图像分成互不重叠的子块;
统计每个子块的bgp直方图,得到对应各子块的直方图;
将所有子块的直方图按顺序进行拼接,得到最终的bgp编码值。
在特征库聚类阶段,对人脸数据库中所有人脸图片分别使用上述步骤进行bgp编码,得到bgp编码数据库;在人脸识别阶段,对待检图片采用上述步骤进行bgp编码,得到待检图片的bgp编码。
本实施例中,步骤s2中具体采用k均值聚类方法进行聚类,即基于k均值聚类实现bgp人脸快速检索方法,结合k均值聚类方法能够提高聚类的效率及效果,将相似度较高的编码高效的聚为一类,充分结合bgp人脸特征提取和k均值聚类方法的优势,能够在鲁棒、准确描述人脸的同时,实现检索速度和效率的明显提升,可以实现准确描述人脸的基础上快速检索。
本实施例中,采用k均值聚类方法进行聚类时,先在bgp编码数据库中随机挑选k个初始聚类中心,根据与k个聚类中心的距离将所述bgp编码数据库中各bgp编码划分到各所述聚类中心所属的类,形成k个聚类簇,对每个聚类簇重新计算聚类中心,再根据新的聚类中心重新划分各所述bgp编码,不断迭代直到最大迭代次数或聚类中心不再发生变化。
如图4所示,采用k均值聚类方法进行聚类的具体步骤如下:
step1:随机选取bgp编码数据库中k个bgp编码并作为初始聚类中心,得到k个聚类中心
step2:计算bgp编码数据库中每个bgp编码xp与k个聚类中心的距离d:
若满足目标bgp编码与目标聚类中心的距离最小,即满足:
d(xp,ci)=min(d(xp,cj)),j=1,2,…,k,
则将目标bgp编码划分至目标聚类中心所属的类中,即xp∈ci,j=1,2,…,k,形成k个初始聚类簇;
step3:对当前每个聚类簇重新计算聚类中心,得到k个更新后的聚类中心,计算表达式为:
step4:判断是否达到所需最大迭代次数,若是退出聚类,否则判断当前得到的聚类中心与上一次迭代得到的聚类中心是否有变化,若有变化,返回执行步骤s12以进行下一次迭代计算,否则退出聚类。
经过上述步骤后,即可基于k均值聚类方法将经过bgp编码后的人脸数据库中各图片分为多个类别,将相似度较高的编码聚为一类,各个类别对应为相似的多张图片。
人脸数据库经过上述bgp编码及聚类后,即可得到多个类别以及对应各个类别的聚类中心,后续将待检图片与该数据库特征比较,即可实现人脸识别。本实施例步骤s2的步骤包括:
s21.对待检图片进行bgp编码,得到待检图片的bgp编码;
s22.将待检图片的bgp编码输入至所述bgp编码数据库进行匹配,输出与待检图片的bgp编码匹配的聚类中心并作为相似人脸图片结果列表;
s23.将相似人脸图片结果列表中各人脸图片分别与所述待检图片的bgp编码进行匹配比较,由匹配得到的人脸图片得到最终人脸检索结果。
在人脸检索阶段,对待检图片进行bgp编码,从人脸数据库中先查找与待检图片bgp编码匹配的聚类中心,以减少检索范围,快速定位到目标所在的检索区域,再将待检图片bgp编码与匹配到的聚类中心内各图片进行匹配比较,即可定位到目标图片,实现快速的人脸检索。
本实施例步骤s22中进行匹配时,具体计算待检图片的bgp编码与bgp编码数据库中各聚类中心的距离,由距离最近的聚类中心作为匹配到的聚类中心。
本发明具体实施例中步骤s1采用离线执行,得到包含多个类别以及对应聚类中心的bgp编码数据库进行存储,步骤s2在线对待检图片调用步骤s1得到的bgp编码数据库进行人脸检索。如图5所示,具体分为对数据库离线操作和对目标图片在线操作两部分,离线操作部分中,首先对人脸数据库所有图片进行bgp编码,接着对得到的编码进行k均值聚类,得到k个类别及各自的聚类中心;在线操作部分中,首先对待检索图片进行bgp编码,接着计算该编码与k个聚类中心的距离,找到距离最小的类,而后将该类作为相似人脸图片结果列表,最后将待检索图片编码与相似人脸图片编码比较,得到最终检索结果。即将特征库聚类过程采用离线操作预先完成,在线检索图片时再使用训练好的特征库进行人脸识别,可以节省在线检索的时间,提高在线检索的效率。
为验证本发明上述检索方法的有效性,基于yale库分别采用本发明上述检索方法以及传统检索方法进行实验,yale库包含15个研究对象,每人11张正脸图像,共165幅人脸图像。其中包括了光照、表情、遮挡等变化,yale中一个人部分人脸图像如图6所示,yale人脸库包含人脸的各种变化情况,但样本量有限,165幅图片无法满足大规模检索的数据量要求,而许多大规模人脸库,如lfw、casia等,包括侧脸在内姿态各异的人脸图片,单一人脸描述子难以提取人脸特征。针对上述矛盾,本实施例在yale数据库基础上进行样本扩充,扩充方法为对每张图片进行像素强度变换或加入少许噪声,最终将样本数量扩充为495、1650、4950、16500。
在yale及扩充的样本数据库上,分别使用本发明上述基于k均值聚类的bgp人脸快速检索方法与传统逐一检索方法进行对比实验,样本数n取165、495、1650、4950、16500,k值分别取3、5、7、9,具体实验步骤如下:
step1:从数据库随机选取一张图片作为目标图片;
step2:分别应用传统方法和本文提出的方法进行检索,检索出最相似的十张图片,并记录检索时间;
step3:重复上述两步,重复十次;
step4:将十次的平均检索时间视作该方法在对应数据库上的检索时间(time)。
最终检索时间对比情况如表1所示:
表1:检索时间对比情况
由表1可见,相对于传统检索方法,本发明基于聚类的bgp人脸检索方法能够缩短检索时间,提高检索效率。取n=165,k=9某次实验,随机选取一张图像作为目标图像,如图7所示,两种检索方法得到的检索结果分别如图8和图9所示。从上述结果可见,相对于传统方法,本发明在检索过程中能够保留较高的检索精度。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!