基于多重信息验证的信用卡安全监测方法与流程
本发明涉及互联网技术领域,具体为基于多重信息验证的信用卡安全监测方法。
背景技术
信用卡是一种非现金交易付款的方式,是银行提供给用户的一种先消费后还款的小额信贷支付工具,最早的信用卡出现于19世纪末,信用卡分为贷记卡和准贷记卡两种,具有提供结算服务,方便购物消费,增强安全感;简化收款手续,节约社会劳动力;促进商品销售,刺激社会需求等特点,信用卡由银行或其它财务机构签发给那些资信状况良好的人士,用于在指定的商家购物和消费、或在指定银行机构存取现金的特制卡片,是一种特殊的信用凭证
信用卡使用的过程中涉及到安全使用问题,本发明专利通过用户预先设定额度,进行安全信息回访服务,用户可以先自行支付,如果需要验证,可以启动超过额度和使用频次验证服务,通过电话回拨和信息回访,回访可以设定手机号,身份证号,预先设定的问题,以及声纹识别技术系统进行综合判定核实是否为用户本人,如果信息问题存在可疑问题,银行将对金额暂时锁死,直到保证信息核查正确再进行信息转帐。
安全准确地远程识别和确认信用卡用户的身份;只要能通过某种简单方便且安全可靠的手段确保身份合法,就可以基本杜绝信用卡被非法盗取的现象。类似于人类的指纹和dna,声纹也是人体独特的个性生物特征,很难找到两个声纹完全一样的人,通过预先采集到信用卡人的声音样本,从中抽取出声纹识别“基因”序列,然后在刷卡超额和频率刷卡次数超出限度证时,将信用卡用户的声纹与声纹库中的声纹进行比对确认,就能够轻易地判断领取人是否合法。对于极少量的聋哑人群等特殊人群,再辅以人工检查手段确认。这样回答电话号码以及预设问题回答和声纹识别结合起来,不仅将大幅度降低盗用的可能性,而且极大地提高了信用卡中心的工作效率。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了基于多重信息验证的信用卡安全监测方法,解决了信用卡在使用过程中经常出现不安全,声纹特征的语音获取不便,获取语音的成本较高,使用繁琐,不适合远程身份确认,声纹辨认和确认的算法复杂高。识别准确率较低的问题。
的问题。
(二)技术方案
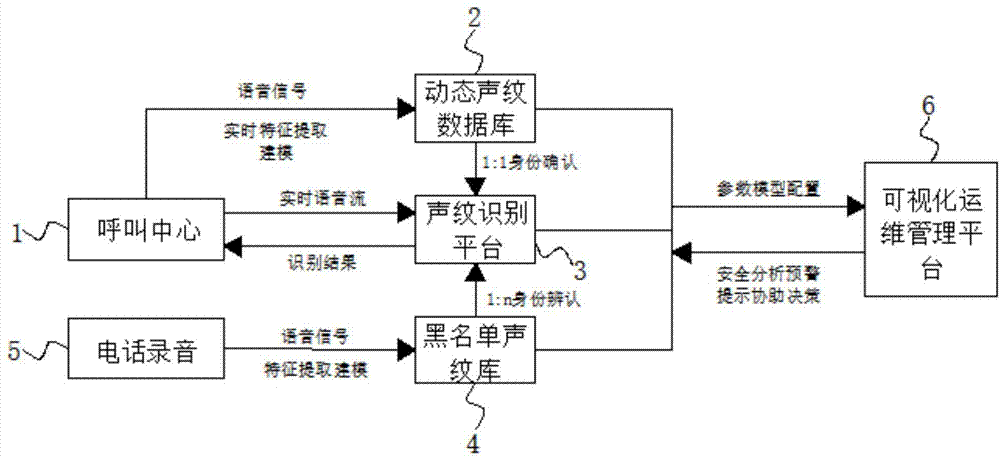
为实现以上目的,本发明通过以下技术方案予以实现:基于多重信息验证的信用卡安全监测方法,包括呼叫中心,所述呼叫中心的输出端与动态声纹数据库的输入端连接,且动态声纹数据库的输出端与声纹识别平台的输入端连接,所述声纹识别平台与呼叫中心实现双向连接,且声纹识别平台的输入端与黑名单声纹库的输出端连接,所述黑名单声纹库的输入端与电话录音的输出端连接,且黑名单声纹库、声纹识别平台和动态声纹数据库均与可视化运维管理平台实现双向连接。
本发明还提供了基于多重信息验证的信用卡安全监测方法的监测方法,具体包括以下步骤;
s1、首先通过用户预先设定额度,进行安全信息回访服务,用户可以先自行支付,如果需要验证,可以启动超过额度和使用频次验证服务,通过电话回拨和信息回访,回访可以设定手机号,身份证号,预先设定的问题,以及声纹识别技术系统进行综合判定核实是否为用户本人;
s2、呼叫中心接收到用户的语音信号后,进行实时特征提取建模,声纹自动识别模型可以分别通过声学特征、词法特征、韵律特征、语种、方言和口音信息和通道信息对用户的语音信号进行提取识别;
s3、动态声纹数据库可对提取的用户语音特征进行动态搜索对比,然后通过声纹识别平台进行1:1身份确认,同时实时语音流会直接传送至声纹识别平台,声纹识别平台并将识别结果发给呼叫中心,电话录音会对用户的呼叫语音进行实时录制,并将录下的音频信号进行特征提取建模存储到黑名单声纹库内;
s4、声纹识别平台可将识别结果传送至可视化运维管理平台可对识别结果进行分析,若识别出确实是用户本人,会进行提示并协助决策,向黑名单声纹库会将用户的语音信息在黑名单声纹库上去除,若识别出不是用户本人时,可视化运维管理平台会将黑名单声纹库内呼叫者特征提取出的数据通过声纹识别平台进行1:n身份辨认,并将辨认的结果传送至可视化运维管理平台内,从而实现对信用卡的安全声纹监测。
(三)有益效果
本发明提供了基于多重信息验证的信用卡安全监测方法。与现有技术相比具备以下有益效果:该基于信用卡安全监测系统及其监测方法,通过在呼叫中心的输出端与动态声纹数据库的输入端连接,且动态声纹数据库的输出端与声纹识别平台的输入端连接,声纹识别平台与呼叫中心实现双向连接,且声纹识别平台的输入端与黑名单声纹库的输出端连接,黑名单声纹库的输入端与电话录音的输出端连接,且黑名单声纹库、声纹识别平台和动态声纹数据库均与可视化运维管理平台实现双向连接,可实现通过用户预先设定额度,进行安全信息回访服务,用户可以先自行支付,如果需要验证,可以启动超过额度和使用频次验证服务,通过电话回拨和信息回访,回访可以设定手机号,身份证号,预先设定的问题,以及声纹识别技术系统进行综合判定核实是否为用户本人,如果信息问题存在可疑问题,银行将对金额暂时锁死,直到保证信息核查正确再进行信息转帐,安全准确地远程识别和确认信用卡用户的身份,通过预先采集到信用卡人的声音样本,从中抽取出声纹识别“基因”序列,然后在刷卡超额和频率刷卡次数超出限度证时,将信用卡用户的声纹与声纹库中的声纹进行比对确认,就能够轻易地判断领取人是否合法,对于极少量的聋哑人群等特殊人群,再辅以人工检查手段确认,这样回答电话号码以及预设问题回答和声纹识别结合起来,不仅将大幅度降低盗用的可能性,而且极大地提高了信用卡中心的工作效率,从而很好的解决了信用卡在使用过程中经常出现不安全,声纹特征的语音获取不便的问题,大大降低了获取语音的成本,简化了使用步骤,适合远程身份确认,声纹辨认和确认的算法复杂低,识别准确率高。
附图说明
图1为本发明系统的结构原理框图。
图中,1呼叫中心、2动态声纹数据库、3声纹识别平台、4黑名单声纹库、5电话录音、6可视化运维管理平台。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明实施例提供一种技术方案:基于多重信息验证的信用卡安全监测方法,包括呼叫中心1,呼叫中心1的输出端与动态声纹数据库2的输入端连接,且动态声纹数据库2的输出端与声纹识别平台3的输入端连接,声纹识别平台3与呼叫中心1实现双向连接,且声纹识别平台3的输入端与黑名单声纹库4的输出端连接,黑名单声纹库4的输入端与电话录音5的输出端连接,且黑名单声纹库4、声纹识别平台3和动态声纹数据库2均与可视化运维管理平台6实现双向连接,特征提取的任务是提取并选择对说话人的声纹具有可分性强、稳定性高等特性的声学或语言特征,与语音识别不同,声纹识别的特征必须是“个性化”特征,而说话人识别的特征对说话人来讲必须是“共性特征”,虽然目前大部分声纹识别系统用的都是声学层面的特征,但是表征一个人特点的特征应该是多层面的,包括:(1)与人类的发音机制的解剖学结构有关的声学特征、鼻音、带深呼吸音、沙哑音、笑声等;(2)受社会经济状况、受教育水平、出生地等影响的语义、修辞、发音、言语习惯等;(3)个人特点或受父母影响的韵律、节奏、速度、语调、音量等特征。从利用数学方法可以建模的角度出发,声纹自动识别模型目前可以使用的特征包括:(1)声学特征;(2)词法特征;(3)韵律特征;(4)语种、方言和口音信息;(5)通道信息等,根据不同的任务需求,声纹识别还面临一个特征选择或特征选用的问题,例如,对“信道”信息,在刑侦应用上,希望不用,也就是说希望弱化信道对说话人识别的影响,因为我们希望不管说话人用什么信道系统它都可以辨认出来;而在银行交易上,希望用信道信息,即希望信道对说话人识别有较大影响,从而可以剔除录音、模仿等带来的影响,总之,较好的特征,应该能够有效地区分不同的说话人,但又能在同一说话人语音发生变化时保持相对的稳定;不易被他人模仿或能够较好地解决被他人模仿问题;具有较好的抗噪性能,对于模式识别,有以下几大类方法:
(1)模板匹配方法:利用动态时间弯折(dtw)以对准训练和测试特征序列,主要用于固定词组的应用(通常为文本相关任务);
(2)最近邻方法:训练时保留所有特征矢量,识别时对每个矢量都找到训练矢量中最近的k个,据此进行识别,通常模型存储和相似计算的量都很大;
(3)神经网络方法:有很多种形式,如多层感知、径向基函数(rbf)等,可以显式训练以区分说话人和其背景说话人,其训练量很大,且模型的可推广性不好;
(4)隐式马尔可夫模型(hmm)方法:通常使用单状态的hmm,或高斯混合模型(gmm),是比较流行的方法,效果比较好;
(5)vq聚类方法(如lbg):效果比较好,算法复杂度也不高,和hmm方法配合起来更可以收到更好的效果;
(6)多项式分类器方法:有较高的精度,但模型存储和计算量都比较大;
声纹识别需要解决的关键问题还有很多,诸如:短话音问题,能否用很短的语音进行模型训练,而且用很短的时间进行识别,这主要是声音不易获取的应用所需求的;声音模仿(或放录音)问题,要有效地区分开模仿声音(录音)和真正的声音;多说话人情况下目标说话人的有效检出;消除或减弱声音变化(不同语言、内容、方式、身体状况、时间、年龄等)带来的影响;消除信道差异和背景噪音带来的影响;此时需要用到其他一些技术来辅助完成,如去噪、自适应等技术。
对说话人确认,还面临一个两难选择问题,通常,表征说话人确认系统性能的两个重要参数是错误拒绝率和错误接受率,前者是拒绝真正说话人而造成的错误,后者是接受集外说话人而造成的错误,二者与阈值的设定相关,两者相等的值称为等错率,在现有的技术水平下,两者无法同时达到最小,需要调整阈值来满足不同应用的需求,比如在需要“易用性”的情况下,可以让错误拒绝率低一些,此时错误接受率会增加,从而安全性降低;在对“安全性”要求高的情况下,可以让错误接受率低一些,此时错误拒绝率会增加,从而易用性降低。前者可以概括为“宁错勿漏”,而后者可以“宁漏勿错”。我们把真正阈值的调整称为“操作点”调整。好的系统应该允许对操作点的自由调整。
本发明还公开了基于多重信息验证的信用卡安全监测方法的监测方法,具体包括以下步骤;
s1、首先通过用户预先设定额度,进行安全信息回访服务,用户可以先自行支付,如果需要验证,可以启动超过额度和使用频次验证服务,通过电话回拨和信息回访,回访可以设定手机号,身份证号,预先设定的问题,以及声纹识别技术系统进行综合判定核实是否为用户本人;
s2、呼叫中心1接收到用户的语音信号后,进行实时特征提取建模,声纹自动识别模型可以分别通过声学特征、词法特征、韵律特征、语种、方言和口音信息和通道信息对用户的语音信号进行提取识别,准确识别说话人真实身份,正确区分真实和伪造的生物信息,杜绝各种仿冒、窃取或复制的可能;
s3、动态声纹数据库2可对提取的用户语音特征进行动态搜索对比,然后通过声纹识别平台3进行1:1身份确认,同时实时语音流会直接传送至声纹识别平台3,声纹识别平台3并将识别结果发给呼叫中心1,电话录音5会对用户的呼叫语音进行实时录制,并将录下的音频信号进行特征提取建模存储到黑名单声纹库4内,可对海量数据进行高并发处理,支持十亿级声纹数据库1:n秒级检索识别,准确率≧99%;
s4、声纹识别平台3可将识别结果传送至可视化运维管理平台6可对识别结果进行分析,若识别出确实是用户本人,会进行提示并协助决策,向黑名单声纹库4会将用户的语音信息在黑名单声纹库4上去除,若识别出不是用户本人时,可视化运维管理平台6会将黑名单声纹库4内呼叫者特征提取出的数据通过声纹识别平台3进行1:n身份辨认,并将辨认的结果传送至可视化运维管理平台6内,从而实现对信用卡的安全声纹监测,在多人对话场景中准确辨认用户,分离出单个说话人音频,并识别出每个人的身份和说话内容,声纹反欺诈系统针对不法分子通过电话和网络诈骗、勒索、绑架等刑事犯罪案件提供解决方案,在通信系统或安全监测系统中嵌入声纹识别技术,监控过程中,实时建立动态声纹黑/白名单库,进行1:n超大规模比对验证,准确识别来电人真实身份,并持续跟踪监控嫌疑人员,为社保经办机构提供专属定制的声纹识别生存验证解决方案,在原有社保信息管理系统的基础上,采用声纹识别技术,进行远程电话身份认证,针对对信息系统的使用比较熟练的人群设置自动认证方式,针对对使用互联网比较有门槛的人设置半自动认证方式,使用简便,性价比高,声纹信用卡验证系统能够针对黑中介,身份冒用,高危用户建立数据中心,建立黑名单,对与黑名单匹配用户直接预警,拦截。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!