一种拍摄目标的三维坐标估计方法和拍摄设备与流程
本发明属于三维空间的检测领域,尤其涉及一种拍摄目标的三维坐标估计方法、计算机可读存储介质和拍摄设备。
背景技术:
拍摄目标经现有技术的拍摄设备成像后,可得到拍摄目标的二维坐标。然而,实际应用中,经常希望能获取拍摄目标的三维坐标。因此,现有技术的拍摄设备无法满足实际应用的需求。
技术实现要素:
本发明的目的在于提供一种拍摄目标的三维坐标估计方法、计算机可读存储介质和拍摄设备,旨在解决现有技术的拍摄设备无法获取拍摄目标的三维坐标的问题。
第一方面,本发明提供了一种拍摄目标的三维坐标估计方法,所述方法包括:
获取拍摄装置拍摄的目标图像;
根据所述目标图像得到一个或多个目标的二维矩形框;
针对每个目标分别计算拍摄装置相对于目标的三维空间姿态;
根据所述目标的二维矩形框和拍摄装置相对于目标的三维空间姿态找到目标的二维矩形框的四条边对应于目标的三维包围盒的点的编号;
根据目标的二维矩形框的四个边对应于目标的三维包围盒的点的编号代入包围盒方程式得到目标的三维坐标。
第二方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述的拍摄目标的三维坐标估计方法的步骤。
第三方面,本发明提供了一种拍摄设备,包括:
一个或多个处理器;
存储器;以及
一个或多个计算机程序,其中所述一个或多个计算机程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述处理器执行所述计算机程序时实现如上述的拍摄目标的三维坐标估计方法的步骤。
在本发明中,由于根据目标图像得到一个或多个目标的二维矩形框;根据所述目标的二维矩形框和拍摄装置相对于目标的三维空间姿态找到目标的二维矩形框的四条边对应于目标的三维包围盒的点的编号;根据目标的二维矩形框的四个边对应于目标的三维包围盒的点的编号代入包围盒方程式得到目标的三维坐标。因此本发明可以使拍摄设备获取拍摄目标的三维坐标。
附图说明
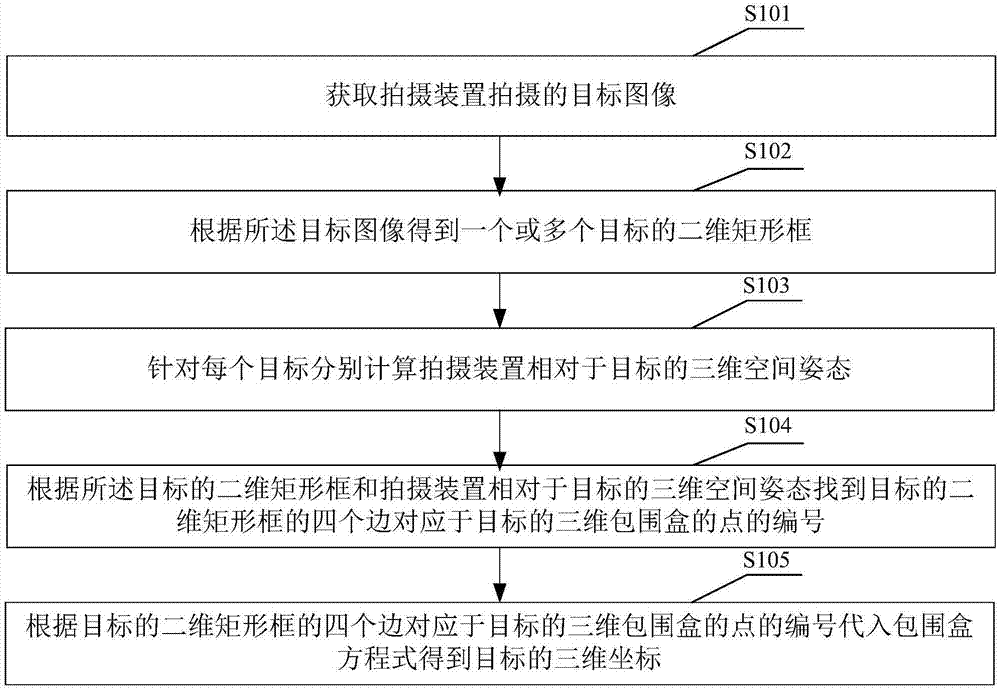
图1是本发明实施例一提供的拍摄目标的三维坐标估计方法的流程图。
图2是本发明实施例三提供的拍摄设备的具体结构框图。
具体实施方式
为了使本发明的目的、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
实施例一:
请参阅图1,本发明实施例一提供的拍摄目标的三维坐标估计方法包括以下步骤:需注意的是,若有实质上相同的结果,本发明的拍摄目标的三维坐标估计方法并不以图1所示的流程顺序为限。
s101、获取拍摄装置拍摄的目标图像。
s102、根据所述目标图像得到一个或多个目标的二维矩形框。
在本发明实施例一中,s102具体可以为:
根据所述目标图像,采用神经网络深度学习算法,如yolo、ssd、mtcnn、faster-rcnn,预测得到一个或多个目标的二维矩形框,二维矩形框的中心点记作u0、v0,宽高分别记作w、h。
s103、针对每个目标分别计算拍摄装置相对于目标的三维空间姿态。
在本发明实施例一中,s103具体可以为:
针对每个目标分别采用神经网络深度学习算法预测得到和目标三维空间姿态相关的矢量q,根据和目标三维空间姿态相关的矢量q转换成目标的三维空间姿态r。具体可以包括以下步骤:
s1031、构造一组和目标三维空间姿态相关的矢量q。
在本发明实施例一中,和目标三维空间姿态相关的矢量q可以是:4元数{q0,q1,q2,q3}、姿态矩阵或者三个姿态角{a,b,c}。当三维空间的其中两个维度所确定的平面是与拍摄装置视线方向垂直时,所述矢量q是二元数。
s1032、接收拍摄装置拍摄的目标图像i*。
s1033、将优化的神经网络模型参数w*以及接收的拍摄装置拍摄的目标图像i*代入神经网络模型方程,得到矢量q。
在本发明实施例一中,神经网络模型方程为f(w*,i*)=q。
优化的神经网络模型参数w*可以通过以下方式得到:
接收拍摄装置拍摄的用于学习的目标图像i;
利用机器学习将n组样本数据i1,q1...in,qn形成的样本集,按照神经网络模型方程优化神经网络模型参数w,得到优化的神经网络模型参数w*。
在本发明实施例一中,神经网络模型方程为
f(w,i1)=q1
...
f(w,in)=qn。
其中,机器学习(machinelearning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
利用机器学习将n组样本数据i1,q1...in,qn形成的样本集,具体为:
从原始图像按二维标注坐标u0、v0、w、h对每个目标分别截取图像i;
标注图像i对应的姿态学习数据q,利用摄影测量方法在图像上标注目标的特征点或者特征线,利用pnp算法或后方交会算法得到姿态r,转换成q作为姿态学习数据,为保证学习数据的唯一性,q={q0,q1,q2,q3}的q0分量小于0时,以-q={-q0,-q1,-q2,-q3}作为学习数据。这种标注方法能不依赖其他昂贵设备直接根据图像快速得到目标的姿态和位置。由于在建立神经网络模型的前向传播的时候,神经网络模型的输出层输出表示目标三维空间姿态的4个值,由于神经网络模型输出的值域范围是(-∞,∞),而表示目标三维空间姿态的四元数受到平方和等于1的约束q02+q12+q22+q32=1。因此当矢量q是四元数时,所述神经网络模型的输出处理过程为:
将神经网络模型的最后输出层输出的矢量q经单位化约束层处理后输出四元数矢量q{q0,q1,q2,q3};计算过程如下:
前向传播公式
反向传播公式
四元数预测的是三维空间姿态,退化成二元数就是预测二维平面上的方向,可预测二维平面目标在平面上的姿态,例如,可用于航拍照片预测地面目标的方向。
因此当矢量q是二元数时,所述神经网络模型的输出处理过程为:
将神经网络模型的最后输出层输出的矢量q经单位化约束层处理后输出二元数矢量q{q0,q1};计算过程如下:
前向传播公式
反向传播公式
s1034、通过矢量q解算得到拍摄装置相对于目标的三维空间姿态r。
在本发明实施例一中,矢量q可以是四元数、n个特征点在图像上的坐标、旋转矢量或者旋转矩阵等,其中,n≥3。
当矢量q是四元数时,拍摄装置相对于目标的三维空间姿态r可用下式算出:
当矢量q是n个特征点在图像上的坐标p1,…,pn时,拍摄装置相对于目标的三维空间姿态r和位置t可以通过计算机视觉物像对应关系解算出来,具体可通过opencv库函数中的cv::solvepnp函数得到拍摄装置相对于目标的三维空间姿态r和拍摄装置相对于目标的三维空间坐标t。
当矢量q是旋转矢量时,可以通过opencv库函数中的cv::rodrigues函数将旋转矢量转换成拍摄装置相对于目标的三维空间姿态r。
s104、根据所述目标的二维矩形框和拍摄装置相对于目标的三维空间姿态找到目标的二维矩形框的四条边对应于目标的三维包围盒的点的编号。
在本发明实施例一中,s104具体可以包括以下步骤:
随意选择一个z>0代入公式
假设目标上有n个包围点1,…,n对应存在n个共线方程
根据这个共线方程可以得到每个目标的三维包围盒的点xi对应的像坐标ui和vi;
选择ui中的最小值uil作为目标的二维矩形框左侧横坐标
uil=min(ui|i=1,…,n)
选择ui中的最大值uir作为目标的二维矩形框右侧横坐标
uir=max(ui|i=1,…,n)
选择vi中的最小值vit作为目标的二维矩形框上侧横坐标
vit=min(vi|i=1,…,n)
选择vi中的最大值vib作为目标的二维矩形框下侧横坐标
vib=max(vi|i=1,…,n)
实际情况中通常将目标的三维包围盒的点xi|i=1…n=8设置成目标的三维包围盒的n=8个顶点
比较得到i=1..8中ui的最小值和最大值分别对应编号il和编号ir,其中,编号il和编号ir分别为目标的三维包围盒的点投影在图像上x坐标的最小值和最大值对应的点的编号。
比较得到i=1..8中vi的最小值和最大值分别对应编号it和编号ib,其中,编号it和编号ib分别为目标的三维包围盒的点投影在图像上y坐标最小值和最大值对应的点的编号。
在本发明实施例一中,s104具体也可以包括以下步骤:
对于目标上的n个目标的三维包围盒的点而言,先对目标的三维包围盒的点xi进行变换,得到变换后的分量比较大小确定编号il、编号ir、编号it和编号ib,其中编号il和编号ir分别为目标的三维包围盒的点投影在图像上x坐标的最小值和最大值对应的点的编号,编号it和编号ib分别为目标的三维包围盒的点投影在图像上y坐标最小值和最大值对应的点的编号;
具体可通过以下公式计算
的编号为il;δxi|i=1...n中的最大值δxmax对应的点的编号为ir;δyi|i=1...n
中的最小值δymin对应的点的编号为it;δyi|i=1...n中的最大值δymax对应的点
的编号为ib。
s105、根据目标的二维矩形框的四个边对应于目标的三维包围盒的点的编号代入包围盒方程式(boundingboxequation)得到目标的三维坐标。
在本发明实施例一中,s105具体也可以包括以下步骤:
包围盒方程at=xbox,其中
rij是矩阵r的i行j列的元素值,矩阵a4*3为包围盒矩阵boundboxmatrix(bbm)实际上是由左右上下4个边缘矢量foursidevectors包含[bleftbrightbtopbbottom]行拼合而成。
其中
4行1列的xbox为包围盒矢量boundboxvector,
其中,编号il是ui最小的目标的三维包围盒的点的编号,编号ir是ui最大的目标的三维包围盒的点的编号,编号it是vi最小的目标的三维包围盒的点的编号,编号ib是vi最大的目标的三维包围盒的点的编号,
xi=[xiyizi]’是编号i的物方点坐标,假设目标中心是目标本体坐标系原点,目标在三维空间中的外包立体矩形框由立方体n=8个点构成,i=1,…,n,可以定义
通过解出at=xbox,拍摄装置相对于目标的三维坐标t=[txtytz]’,只有txtytz3个未知数,4个方程,通过最小二乘法解出t=(aat)-1atxbox;
或者,
加上共线方程约束,将
实施例二:
本发明实施例二提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如本发明实施例一提供的拍摄目标的三维坐标估计方法的步骤。
实施例三:
图2示出了本发明实施例三提供的拍摄设备的具体结构框图,一种拍摄设备100包括:一个或多个处理器101、存储器102、以及一个或多个计算机程序,其中所述处理器101和所述存储器102通过总线连接,所述一个或多个计算机程序被存储在所述存储器102中,并且被配置成由所述一个或多个处理器101执行,所述处理器101执行所述计算机程序时实现如本发明实施例一提供的拍摄目标的三维坐标估计方法的步骤。
在本发明中,由于根据目标图像得到一个或多个目标的二维矩形框;根据所述目标的二维矩形框和拍摄装置相对于目标的三维空间姿态找到目标的二维矩形框的四条边对应于目标的三维包围盒的点的编号;根据目标的二维矩形框的四个边对应于目标的三维包围盒的点的编号代入包围盒方程式得到目标的三维坐标。因此本发明可以使拍摄设备获取拍摄目标的三维坐标。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取记忆体(ram,randomaccessmemory)、磁盘或光盘等。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!