一种分离用户和产品注意力机制的文本情感分类方法与流程
本发明涉及自然语言处理领域,具体涉及一种分离用户和产品注意力机制的文本情感分类方法。
背景技术:
目前,文本情感分类被广泛用于在线评论网站(如淘宝和微博),对于评论文本的情感分类研究侧重于向用户推荐符合用户个性化的产品。其中,按照处理文本的粒度不同,情感分析可分为文档级、句子级、属性级等。本发明主要对文档级别的文本进行情感分析,对文本中蕴含的情感,从整体上进行分析、处理、归纳和推理,以此来获得用户的总体情感倾向。
传统的深度学习方法只是关注评论内容的重要性,而忽略用户个性和产品属性的信息。尽管少数模型将用户和产品信息考虑在内,也提高了文本情感分类的准确性。但它们通常是将用户和产品信息加入文本中一起输入模型训练,没有单独考虑二者信息在情感分类中的影响作用。
然而,在评论文本中,首先,我们观察到一些词语或句子侧重体现用户的个性,其他一些则倾向表明产品的属性,这两种信息在识别文本情感标签中产生不同的影响。比如,“这家酒店环境很好,而且我很喜欢这种现代的装修风格”。其中,词语“好、现代的”是用户的观点,表明产品—酒店的属性,而词语“好”是用户表达的情感,强烈体现了用户的个性,即对产品的态度是苛刻还是宽容,如果用评分制度来衡量,对于同一商品,苛刻的用户倾向给低分,宽容的用户倾向给高分。总之,评论观点更多地与产品属性相关联,而评论情感更多与用户个性有关。其次,并非所有词语、句子对于不同用户和不同产品的评论文本语义都有同等作用。因此,首先需要将用户个性和产品属性信息分离开来,运用注意力机制来提取用户个性和产品属性信息。最终,针对文档是由句子、句子是由词语组成的层次结构,因此设计神经网络模型是层次结构的双向长短时记忆模型,以此来映射文档的层次结构。这样不仅能提高文本情感分类的效率、准确性和容错性,而且能满足大规模语料处理的需求。
技术实现要素:
发明目的:本发明提出了一种分离用户和产品注意力机制的文本情感分类方法,使得情感分类具有更好的针对性和精准性。
技术方案:本发明所述的一种分离用户和产品注意力机制的文本情感分类方法,包括以下实现步骤:
(1)预处理待分类的文本;
(2)将处理后的文本向量化;
(3)建立注意力机制模块;
(4)句子特征提取模块,用于接收分词处理后的文本的词向量,并输入到第一层双向长短时记忆模型中,分别得到用户句子特征和产品句子特征;
(5)文档特征提取,用于接收句子特征,并输入到第二层双向长短时记忆模型中,分别得到用户文档特征和产品文档特征;
(6)将用户文档特征和产品文档特征进行拼接,得到综合的文档级别特征;
(7)将步骤(6)所得综合的文档特征输入情感分类模块,进行情感类型识别。
所述步骤(1)包括以下步骤:
(11)将待处理的文本切分成词语或者字的形式,得到分词后的文本;
(12)根据文本数据的特征,对公开的停用词表进行修改,生成新的停用词表;
(13)用新的停用词表,将分词后的文本与情感识别任务无关的词语或者符号删去,得到预处理后的文本数据。
所述步骤(2)包括以下步骤:
(21)生成词向量:利用公开的语料库训练word2vec得到词向量表;
(22)根据词向量表,将预处理后的文本数据转换为数字化结构,作为文本的词向量。
所述步骤(3)包括以下步骤:
(31)将用户的评分行为表示成一个评分矩阵;
(32)根据用户对已知产品的评分数据,通过推荐方法中的协同过滤算法来推断出用户对未知产品的评分;
(33)根据用户-产品评分矩阵,通过奇异值分解法得到用户个性矩阵和产品属性矩阵,分别作为模型的注意力机制,并结合向量化后的文本信息在模型进行训练。
所述步骤(4)包括以下步骤:
(41)分别计算句子中每个词语的用户打分函数和产品打分函数;
(42)根据各词语的打分函数值,分别计算句子中每个词语隐状态的用户权重值和产品权重值;
(43)分别提取用户句子特征和产品句子特征。
所述步骤(5)包括以下步骤:
(51)分别计算文档中每个句子的用户打分函数和产品打分函数;
(52)根据各句子的打分函数值,分别计算文档中每个句子隐状态的用户权重值和产品权重值;
(53)分别提取用户文档特征和产品文档特征。
有益效果:与现有技术相比,本发明的有益效果:1、采用层次结构的双向长短时记忆模型,可以分别从输入词语或句子的前向和后向,进行捕获更加全面的语义信息;2、分别从词语层面和句子层面进行隐状态表示,可以提取出更加深层的文本信息;3、考虑到“冷启动”问题,采用推荐方法中的协同过滤算法,从已有的用户对产品的评分数据中进行信息提取,重点采用基于物品的协同过滤算法,可以有效的全面提取出用户和产品信息;4、采用奇异值分解方法,对用户兴趣分布矩阵进行分解优化,提取出用户个性矩阵和产品属性矩阵,作为模型注意力机制,可以监督模型提取出更加重要的特征;5、提高了文本特征描述的准确性,从而提高了情感识别的正确性。
附图说明
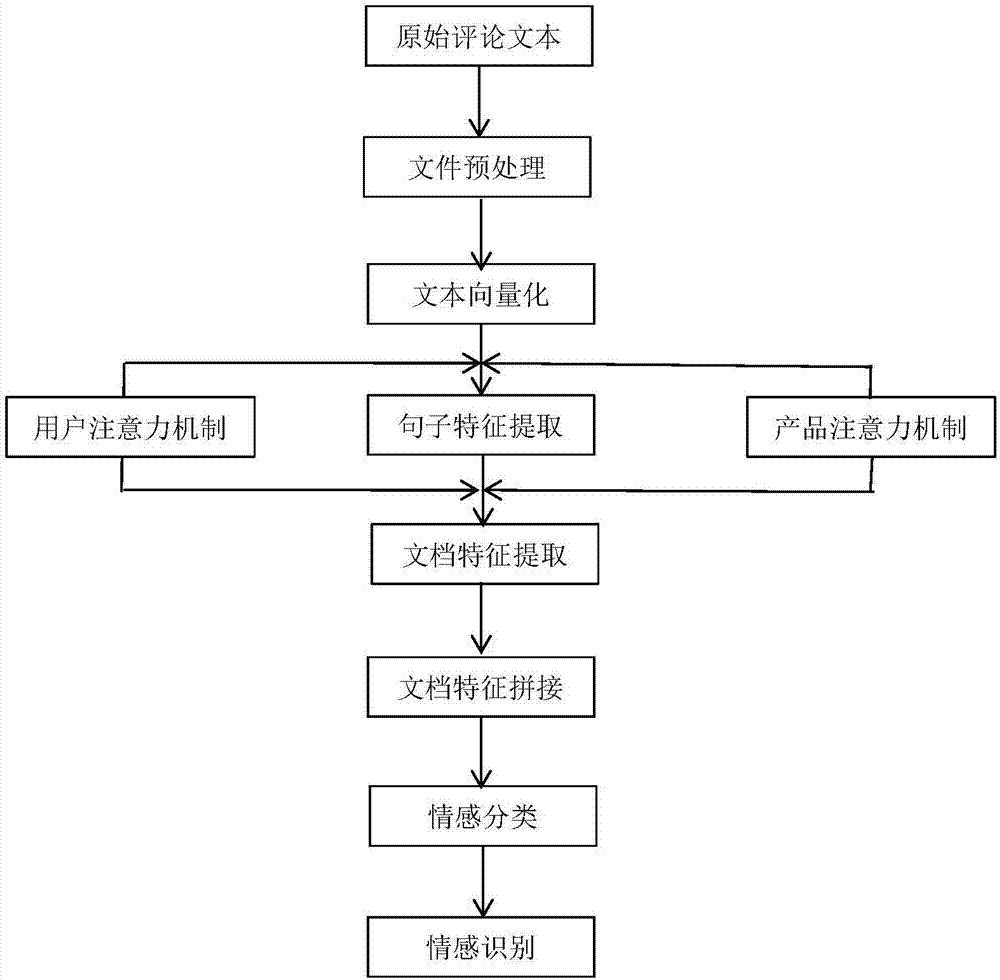
图1为本发明的流程图。
具体实施方式
下面结合附图对本发明做进一步说明,图1为本发明的流程图,包括以下步骤:
1、文本预处理模块:包括词语切分单元、停用词表修订单元,以及停用词删除单元。
(1)词语切分单元,用于将所述待处理的文本切分成词语或者字的形式,得到分词后的文本;
(2)停用词表修订单元,用于根据文本数据,对公开的停用词表进行修改,生成新的停用词表;
(3)停用词删除单元,用于根据所述新的停用词表,将所述分词后的文本中与情感识别任务无关的词语或者符号删去,得到所述预处理后的文本数据。
2、文本向量化模块:包括词向量表生成单元和文本向量化单元。
(1)词向量表生成单元,用于利用公开的语料库训练word2vec得到词向量表;
(2)所述文本向量化单元,用于根据所述词向量表,将所述预处理后的文本数据
3、建立注意力机制模块,包括评分矩阵生成单元、注意力机制生成单元。一是,考虑到“冷启动”问题,利用推荐系统中的协同过滤算法,可以更加全面地捕获用户个性和产品属性信息,并随后作为用户注意力机制和产品注意力机制。二是,由于不是所有词语、句子对于评论文本的情感分类都有同等作用。运用注意力机制原理,对情感分类中有不同影响作用的词语、句子,赋予不同的权重值。
(1)评分矩阵生成单元。用户的评分行为可以表示成一个评分矩阵r,其中r[u][i]就是用户u对物品i的评分,但是,用户不会对所有的物品评分,所以这个矩阵里有很多元素都是空的,这些空的元素称为缺失值(missingvalue)。因此,评分预测从某种意义上说就是填空,如果一个用户对一个物品没有评过分,那么推荐方法就要预测这个用户是否会对这个物品评分以及会评几分。本实例使用基于物品的协同过滤算法,来补全缺失值,基于物品的协同过滤算法主要分为两步:
a)计算物品之间的相似度wij:
|n(i)|是喜欢物品i的用户数,|n(i)||n(j)|是同时喜欢物品i和物品j的用户数。在计算物品之间相似度的算法上,我们提出优化,考虑用户活跃度(iuf)对物品相似度的影响,增加iuf参数来修正物品相似度的计算公式,如下:
b)预测用户对未评分物品j的打分值ruj
其中,n(u)是用户u喜欢的物品的集合,s(j,k)是和物品最相似的k个物品的集合,wij是物品j和i的相似度,rui是用户u对已打分物品i的评分值。
(2)注意力机制生成单元。根据用户-产品评分矩阵r,通过奇异值分解法(svd)得到用户个性矩阵和产品属性矩阵,利用下式进行计算:
r=uspt
其中,r表示待分解的评分矩阵;s∈rk×k表示对角矩阵,u∈rn×k表示所述用户个性矩阵,p∈rn×k表示所述产品属性矩阵,pt是转置形式。最终矩阵u作为模型的用户注意力机制、p作为模型的产品注意力机制,以此来捕获不同语义层面的关键语义信息。
4、句子特征提取模块,包括词语层面隐状态表示单元,用户句子特征
传统的长短时记忆模型算法,并没有单独考虑用户个性和产品属性信息在句子特征提取中的影响,而是将用户和产品信息同评论文本信息直接输入模型,得到句子特征和文档特征。而本发明提出一种单独求解用户特征和产品特征的算法,具体如下:
(1)词语层面隐状态表示单元:用于接收所述分词处理后的文本的词向量
(2)用户句子特征
用户句子特征
a)根据所述用户隐状态表示
其中,vu为权重向量,wh、wu均为权重矩阵,b表示偏置值,均由模型训练学习得到。
b)根据各词语的打分函数值,计算句子中每个词语隐状态的用户权重值
c)根据所述用户隐状态表示
(3)产品句子特征
产品句子特征
a)根据所述产品隐状态表示
其中,vp为权重向量,wh、wp均为权重矩阵,b表示偏置值,均由模型训练学习得到。
b)根据各词语的产品打分函数值,计算句子中每个词语隐状态的产品权重值
c)根据所述产品隐状态表示
5、文档特征提取模块,包括句子层面隐状态表示单元、用户文档特征du提取单元和产品文档特征dp提取单元。
(1)句子层面隐状态表示单元:该单元用于接收步骤(4)所得用户句子特征
(2)用户文档特征du的提取单元包括以下步骤:
a)根据句子层面的用户隐状态表示
b)根据各句子的打分函数值,计算文档中每个句子隐状态的用户权重值
c)根据所述句子级别的隐状态表示
(3)产品文档特征dp的提取单元包括以下步骤:
a)根据句子级别的产品隐状态表示
b)根据各句子的产品打分函数值,计算文档中每个句子隐状态的产品权重值
c)根据所述句子级别的隐状态表示
6、文档特征拼接模块,用于将所述文档特征du、dp进行拼接,得到综合文档级别特征d。
d=[du;dp]
7、情感分类模块,用于将所述综合文档特征d输入分类器,进行情感类型识别:
x=tanh(wld+bl)
其中wl为权重矩阵,bl表示偏置值,均有模型训练学习得到,c表示情感类别,yi表示预测为类别为i的概率。
- 还没有人留言评论。精彩留言会获得点赞!