基于监督类机器学习算法的模型实现架构的方法与流程
本发明涉及一种基于监督类机器学习算法的模型实现架构的方法。
背景技术:
在当前技术环境下,机器学习是最热门最令人振奋的领域之一。机器的学习,让人们享用了稳定的垃圾邮件过滤器、便利的文本及语音识别、可靠的网络搜索引擎和高明的棋手,而且安全高效的自动驾驶汽车有望很快就会出现无可置疑,机器学习已经成为一个热门领域,但它有时候容易一叶障目需要不断地额进行创新才能让其实现不断的学习。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种基于监督类机器学习算法的模型实现架构的方法。
为实现上述目的,本发明采用如下技术方案:
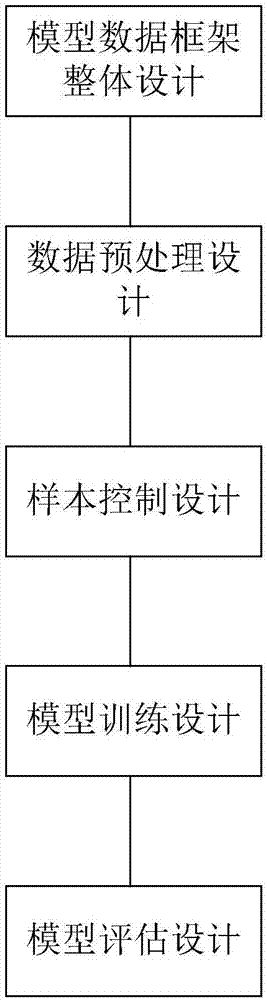
基于监督类机器学习算法的模型实现架构的方法,包括以下步骤:
步骤1:模型数据框架整体设计,主要针对模型输入数据的明确定义;
步骤2:数据预处理设计,主要针对生成模型输入矩阵进行进一步加工处理;
步骤3:样本控制设计,主要针对监督机器学习中的样本数据和标签数据;
步骤4:模型训练设计,主要建立一算法库,将步骤2加工完成的训练数据作为输入,然后,调用算法库中的算法,即可生成相应的机器学习模型;
步骤5:模型评估设计,将测试数据输入训练好的各个模型中来计算获得预测结果,比较测试数据中的目标项和预测结果的差异性。
进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中,所述步骤1中模型输入数据分为目标项和特征项,其中,目标项即为模型需要预测的对象,通过业务需求来确认这样的对象;特征项则是用于进行模型训练的一个多维矩阵,特征项中的每一个维度都对预测目标项有着一定的影响。
再进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中,所述步骤2中处理方式包括以下步骤:
1、删除行记录完全一样的数据样本或者任意一列缺失值超过50%的特征列;
2、相关特征列的基本转换;
3、通过设计相关哑变量离散化一些连续型或者分类文本类型的特征列;
4、异常值的处理,对于整理偏离过大的数据点,进行直接删除或者重新赋值;
5、以明确的逻辑联合多个特征列进行计算,生成新的特征列;
6、以一定的规则将数据进行横向划分,分别定义为训练数据和测试数据。
更进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中,所述基本转换包括log、exp、sqrt转换。
再更进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中所述步骤3中样本数据,需要增加一列名为“weight”或“offset”的修正列,赋值规则为:
标签为1的样本,weight赋值为p1/r1;
标签为0的样本,weight赋值为(1-p1)/(1-r1);
其中p1为初始全样本数据中标签为1的样本所占的比例,r1为抽样调整后的样本数据中标签为1的样本所占的比例。
再更进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中所述步骤4中的算法库为r中的算法包,或为python中的scipy算法库,或为spark中的mllib算法库。
再更进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中,所述步骤5中涉及的目标项和预测结果设有参考量,分别为均方误差和分类准确率,其中,
mse称为均方误差,计算公式为:
其中,n为测试样本量,yi为测试数据中的目标项,
分类准确率,计算公式为:
其中,n为测试样本量,p为模型预测为1且实际目标项也为1的数量,q为模型预测为0且实际目标项也为0的数量。
再更进一步的,所述的基于监督类机器学习算法的模型实现架构的方法,其中,一定的规则的规则为以7:3的比例划分训练测试数据,即70%的数据样本用于训练模型,30%的数据样本用来测试。
借由上述方案,本发明至少具有以下优点:
1、该发明为监督类机器学习算法的完整过程,具有通用性与可复制性,对于各个领域的机器学习算法业务都可以使用。
2、该发明在数据预处理过程中考虑周全,为建立机器学习模型提供了可靠的输入。
3、该发明适用于各类机器学习框架及各类机器学习模型。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1是本发明的结构示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
如图1所示,基于监督类机器学习算法的模型实现架构的方法,包括以下步骤:
步骤1:模型数据框架整体设计,主要针对模型输入数据的明确定义;
其中,模型输入数据分为目标项和特征项,其中,目标项即为模型需要预测的对象,通过业务需求来确认这样的对象;特征项则是用于进行模型训练的一个多维矩阵,特征项中的每一个维度都对预测目标项有着一定的影响。
因此该模型数据框架整体的主要任务是根据实际项目的业务需求及可以获取的总体数据情况,通过明确的逻辑定义来确定目标项及特征项数据,并把它们融合汇聚成一个完整的模型输入矩阵。
步骤2:数据预处理设计,主要针对生成模型输入矩阵进行进一步加工处理;
所述步骤2中处理方式包括以下步骤:
1、删除行记录完全一样的数据样本或者任意一列缺失值超过50%的特征列;
2、相关特征列的基本转换,例如所述基本转换包括log、exp、sqrt转换;
3、通过设计相关哑变量离散化一些连续型或者分类文本类型的特征列;
4、异常值的处理,对于整理偏离过大的数据点,进行直接删除或者重新赋值;
5、以明确的逻辑联合多个特征列进行计算,生成新的特征列;
6、以一定的规则将数据进行横向划分,分别定义为训练数据和测试数据。
一定的规则的规则为以7:3的比例划分训练测试数据,即70%的数据样本用于训练模型,30%的数据样本用来测试。
步骤3:样本控制设计,主要针对监督机器学习中的样本数据和标签数据;
在实际项目中经常出现1-0样本不平衡的情况,大多数情况下标签为1的样本数据远小于标签为0的样本数据。因此需要有一个样本控制的过程,即复制标签为1的样本数据或者随机抽样标签为0的样本数据,最终使得标签为1的样本数据量和标签为0的样本数据量保持在同一数量级上。
所述步骤3中样本数据,需要增加一列名为“weight”或“offset”的修正列,赋值规则为:
标签为1的样本,weight赋值为p1/r1;
标签为0的样本,weight赋值为(1-p1)/(1-r1);
其中p1为初始全样本数据中标签为1的样本所占的比例,r1为抽样调整后的样本数据中标签为1的样本所占的比例。
步骤4:模型训练设计,主要建立一算法库,将步骤2加工完成的训练数据作为输入,然后,调用算法库中的算法,即可生成相应的机器学习模型;
针对步骤4需要在建模过程中需要注意:
1、在没有理论证明某种算法最优的情况下,需要遍历算法库中的所有适合输入数据的模型;
2、对于每种算法而言,关键参数种类也各有不同;针对每种算法的主要参数,需要进行有针对性的配置,才能使模型的拟合效果达到最佳;
3、为了防止模型过拟合现象的发生,需要进行k折的交叉验证进行那些待估参数的调整拟合;
4、建模完成以后需要进行模型诊断,例如对于回归类的算法需要查看模型的r2是否较大,越接近于1说明模型的拟合效果越好。另外还要查看残差的正态随机性检验是否能够通过,维度之间是否存在明显的多重共线性现象;对于分类问题,需要查看绘制出的roc曲线下的auc值是否较大,越接近1说明模型的拟合效果越好。
所述步骤4中的算法库为r中的算法包,或为python中的scipy算法库,或为spark中的mllib算法库。
步骤5:模型评估设计,将测试数据输入训练好的各个模型中来计算获得预测结果,比较测试数据中的目标项和预测结果的差异性。
所述步骤5中涉及的目标项和预测结果设有参考量,分别为均方误差和分类准确率,其中,
mse称为均方误差,计算公式为:
其中,n为测试样本量,yi为测试数据中的目标项,
分类准确率,计算公式为:
其中,n为测试样本量,p为模型预测为1且实际目标项也为1的数量,q为模型预测为0且实际目标项也为0的数量。
另外,一些实际的项目中可能存在自定义的模型预测性能评价指标。综合考虑mse值、accuracy值以及自定义的模型评价指标,尽量选择mse值小,accuracy值大的模型做为最终选择使用的模型。
本发明至少具有以下优点:
1、该发明为监督类机器学习算法的完整过程,具有通用性与可复制性,对于各个领域的机器学习算法业务都可以使用。
2、该发明在数据预处理过程中考虑周全,为建立机器学习模型提供了可靠的输入。
3、该发明适用于各类机器学习框架及各类机器学习模型。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!