一种跨进程的数据采集处理方法与流程
本发明涉及一种跨进程的数据采集处理方法。
背景技术:
在软件开发中,出于模块化目的,不但常常将一个应用程序分解为多个静态库/动态库模块,有时也会基于稳定性和多实例运行的考虑,将一个应用软件拆解为多个应用程序模块,采用多进程协作运行的方式实现特定的软件功能。
对于32位进程而言,将一个软件拆解为多个进程,可以更加充分地应用64位操作系统的内存资源;对于一个软件中较为复杂、不够稳定的部分代码,拆解独立为一个进程,再加上进程故障守护重启机制,可以有效避免不稳定的功能代码引起的进程崩溃问题影响其他进程中关键代码的运行。
总而言之,软件采用多进程协作运行的方式设计是一个非常自然的设计。但是,引入的一个新问题是,多进程设计的软件中,一个进程往往以另一个进程的输出作为输入,这对进程间数据处理任务的转交、传递提出了要求。
在主流操作系统中,两个进程之间交换较多的数据,较为常用的两个方法,一是共享内存,二是管道。由于基于计算机的内存完成进程间数据传递,性能较高,因此,这在大部分场合下,是极佳的选择。
上面提到的共享内存或者管道技术,用于两个进程间传递数据,在大部分场合下,是极佳的选择。但在一些特殊的场合下,也存在失效的问题。
假设有两个进程,进程a和进程b,进程a位于前端收集原始数据,并做预处理,将预处理后的数据递交给进程b;进程b位于后端,专门用于对进程a传递而来的数据进行更为复杂的后续处理。
由于进程b主要负责对进程a预处理过的数据进行更复杂的后续处理,那么意味着进程b涉及的算法代码通常更加复杂,也更加容易出错和不稳定,同时复杂的处理也基本意味着对单笔数据处理的时间周期也更长。
上面的分析,主要说明进程b相对于进程a而言不稳定异常退出的概率更大,并且处理数据的效率更低,进程a可能在某些高峰时期以1000次/每秒的速率采集和预处理数据,进程b则有可能以最快10次/每秒的速率进行复杂处理。带来的问题是,进程b内可能会堆积大量的待处理数据在内存中,在大量内存数据未处理完毕的时候,如果进程b故障崩溃,将会发生大量的数据丢失。
考虑到上述复杂处理的耗时性以及可能的不稳定性,如果要实现可靠的数据处理,必须考虑引入磁盘存储。如果进程a将预处理后的数据,直接写入磁盘文件中,那么进程b将可以按自己的处理性能逐个处理,而不必担心进程a有突发大量的预处理数据任务推送导致在短时间内发生大量的内存资源占用。
总而言之,不引入磁盘存储,仅仅基于内存进行跨进程的数据任务传递,将会面临两个威胁:一是大量的内存资源占用;二是,关键处理进程的崩溃将会引起大量的数据丢失。
对于在多个进程之间共享的磁盘存储,有一个潜在的可能选项,是类似mssqlserver、oracle、mysql这样的关系数据库。从功能角度而言,是可行的,但是关系数据库的主要优势在于提供二维平面化数据的索引查询,其复杂的数据存储格式和索引功能,在单纯实现先进先出任务队列的功能需求下,显得多余且性能低下,往往难以达到理想的速度性能。
随着某些领域中应用程序复杂性的提高,高度复杂的大型软件,往往采用多进程协作的开发、运行方式。
如此,可以避免复杂的数据分析代码的不稳定性影响数据采集部分代码的7*24小时不间断运行特性。因为,如果同处于一个进程,那么数据分析代码的崩溃故障,将造成数据采集部分代码在进程崩溃后、维护重启前,一个可能相当长的时间内得不到运行,从而导致原始数据采集缺失。
拆分进程处理后,复杂代码的稳定性问题给整个软件带来的负面影响将会得到一定程度的降低,但基于内存的交换,会造成来不及处理的数据在内存中大量堆积,如果内存堆积发生在复杂处理进程中,同样还是存在数据在处理前就大量丢失的风险。
技术实现要素:
本发明的目的,在于提供一种跨进程的数据采集处理方法,其既可保障数据的可靠存储转移使用,同时也避免了数据库复杂数据存储方式和索引建立的性能丢失。
为了达成上述目的,本发明的解决方案是:
一种跨进程的数据采集处理方法,用于实现数据采集进程与数据处理进程之间数据的存储;数据采集进程与数据处理进程共享磁盘存储,方法包括如下步骤:
步骤1,生成待处理任务列表文件todo.list,将数据采集进程输出的数据保存于共享磁盘的文件夹中,若输出的数据大小高于限值,则分为多个任务内容文件进行保存,所有文件的路径和文件名信息均根据时间先后记录在待处理任务列表文件todo.list中;
步骤2,将待处理任务列表文件todo.list改名为doing.list,同时生成新的待处理任务列表文件todo.list,此时若数据采集进程继续输出数据,将其记录在所述新的待处理任务列表文件todo.list中;
步骤3,数据处理进程逐行处理任务列表doing.list对应的文件,并在处理完毕后删除该对应的文件。
采用上述方案后,本发明具有以下有益效果:
(1)本发明通过在两个协作进程之间引入一个逻辑的磁盘文件总线,来消除高峰期采集的数据因处理性能不足,大量堆积在内存中造成资源占用,并可能因进程崩溃而大量丢失的可能风险;
(2)本发明设计了数据文件结合列表文件的数据存储方式,通过在列表文件中记录多个任务数据文件的文件路径,巧妙运用了列表文件改名完全在操作系统控制下,不受多进程多线程访问冲突影响的快速任务数据转交方法;
(3)本发明可以避免使用重量级的数据库存储跨进程共享数据的方案,既保障了数据的可靠存储转移使用,同时也避免了数据库复杂数据存储方式和索引建立的性能丢失,是一种轻量、优雅、稳定的跨进程的大数量数据传递方案。
附图说明
图1是本发明的模块原理图;
图2是本发明的数据采集流程示意图;
图3是本发明的任务切换流程示意图;
图4是本发明的数据处理流程示意图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
首先给出几个名词解释:
1)数据采集进程:foregroundprocess,以下简记为fp,用于进行原始数据采集并进行预处理,将预处理结果输出到磁盘文件中,等待其他进程处理的一类进程;
2)数据处理进程bp:backgroudprocess,以下简记为bp,从磁盘文件中读取缓存的任务数据,并执行数据处理的一类进程;
3)磁盘文件总线:filebus,按照一定的规则组织存放的文件集合,供数据采集进程向数据处理进程传递约定格式的数据;
4)待处理列表文件:todo.list
5)处理列表文件:doing.list
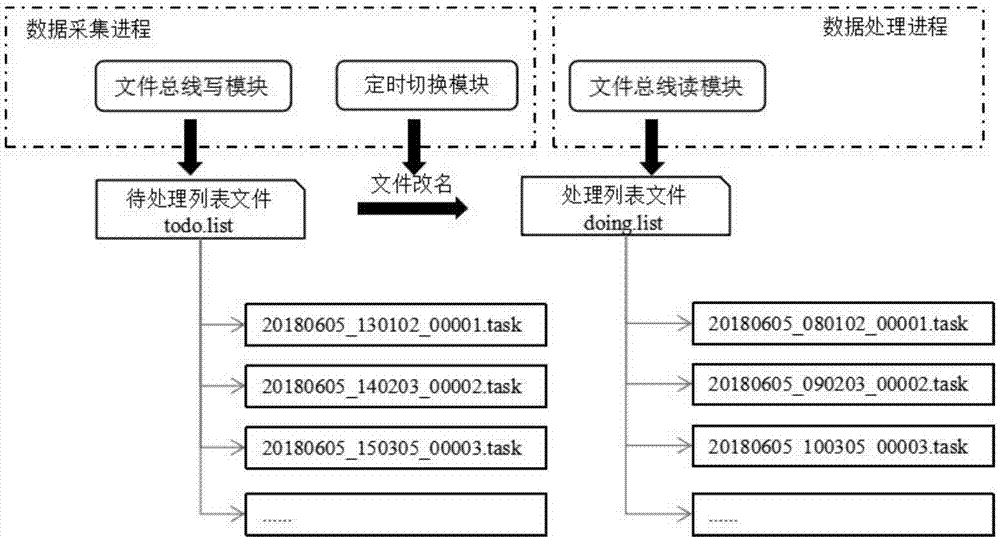
配合图1所示,本发明提供的一种跨进程的数据采集处理方法,采用的基本模块主要有文件总线写模块、文件总线读模块和定时切换模块,下面分别介绍。
文件总线写入模块,是供数据采集进程在对原始数据进行预处理后将数据写入到磁盘文件总线时调用的模块。为了避免单个文件过大(如超过4g的文件,则普通文件操作api不能正常访问),会根据单个文件的大小情况,自动切换生成多个任务内容文件,并按顺序登记到“待处理列表文件”中;
文件总线读取模块,主要为数据处理进程提供读取数据采集进程写入到磁盘文件总线中任务数据时调用的模块。为了保证读取任务顺序和数据采集进程写入时一致,同样需要先访问“处理列表文件”,然后再进一步读取访问任务内容文件;
定时切换模块,主要用来定时监测数据处理进程是否完成对“处理列表文件”的处理和删除,在需要时,将“待处理列表文件”改名为“处理列表文件”,完成待处理数据从数据采集进程到数据处理进程的转移、传递。
以下将结合现有技术,说明本发明技术方案的思路。
数据采集进程fp预处理后的数据,通常都具备一定数据格式,按照约定数据格式,将一个个待处理任务数据写入到一个文件中,即可完成持久化存储。当数据采集进程完成数据写入,数据处理进程bp可以在任意的时间点打开文件进行读取,开始数据的后续处理。
以上是使用文件来完成跨进程的数据交换,最简单直接的实现思路,但是必然会存在以下的问题。
由于数据采集进程对数据的采集预处理,往往和数据处理进程的数据处理同步进行。并不能因为数据处理进程正在进行数据,就不得不让数据采集进程进入进入停等状态。
当存在两个进程,同时读/写访问同一个文件时,无法保证文件内容的一致性。由于文件io通常是一个耗时操作,在计算机的操作系统中不可能是一个原子操作。有较大的概率出现,数据采集进程在写入某个任务数据、尚未写入完整时,数据处理进程已经在系统进程调度下开始尝试读取新的任务数据。这种情况下,数据处理进程将读入一个随机不完整的任务数据,且完整度完全随机、难以分析(因为多个进程在系统的抢占式调度下并没有固定的执行顺序)。最终,数据处理进程将难以从不确定完整度的任务数据处理中恢复到正常状态,并且这是一个大概率的事件。
因此,基于单个文件,来完成数据采集进程和数据处理进程之间的任务数据传递,是不可靠的。
考虑两个filew和filer,filew用于数据采集进程写入,filer用于数据处理进程读取。初始情况下,filew、filer都不存在,当数据采集进程通过文件总线写入模块创建一个filew并写入n个任务数据(每次写入一个任务数据前,都需要对filew施加一个线程同步锁lockw,数据完整写入后释放锁)后,数据采集进程中的定时切换模块检测到filer不存在时,将对filew施加线程同步锁lockw,然后将filew关闭以完成写入动作(此时,文件内的内容数据必定是完整的),最后将filew改名为filer,供数据处理进程打开读取处理(最后需要释放锁)。当数据处理进程处理完filer后,应将其删除,以便数据采集进程可以切换提供新的任务数据文件。
上述过程中filew一旦改名为filer后,当数据采集进程需要通过文件总线写入模块写入新的任务数据时,需要重新创建一个新的文件filew。
依据上述原理,基本上已经可以解决基于文件的跨进程数据传递的问题,但仍有不足之处。
考虑数据处理进程bp处理效率较低或者因为故障无法启动运行,而且数据采集进程fp采集的数据量极大,那么容易出现一个问题是,当存在一个filew改名得到的filer文件,filer未能在较短的时间内被数据处理进程bp处理完毕并删除的情况下,数据采集进程fp将可能在一个filew中,迅速写入大量数据。通常在主流操作系统中,普通的文件操作api通常只能访问4g大小以下的文件,当filew的大小一旦超出此大小后,后续的处理将会发生异常。改用较少使用的特殊api,也可以消除此问题,但是单个数据文件过大,在应用程序的管理、维护上也是非常不利的,因此,通常较少启用特殊的文件api来兼容极大的文件(大于4gb字节的文件)。
下面进一步解决此问题。
如果,限制了单个任务数据文件的最大尺寸(例如1g以下),那么在数据处理进程bp处理任务缓慢的情况下,数据采集进程fp无法切换新文件,可能写入的数据量超出单个任务数据文件的最大尺寸。针对此问题,考虑引入一个待处理任务列表文件(todo.list),当数据采集进程fp的一个新的写入将造成当前任务数据文件cur.task超过限定的尺寸大小时,主动切换一个新文件new.task进行写入,同时将cur.task的路径(可以是相对路径)和文件名信息写入todo.list的最后一行进行记录。亦即,数据采集进程的输出将升级为一个待处理列表文件todo.list和一组任务数据文件*.task的形式。
对于数据处理进程bp而言,处理任务的目标文件也需要同样升级为一个处理列表文件doing.list和一组任务数据文件xxxx.task的形式,其中处理列表文件doing.list由待处理列表文件todo.list改名转化而来。
数据采集进程fp,负责不断生成新的任务数据文件*.task,并将路径信息<path>/<name>.task追加写入待处理列表文件todo.list末尾行(若todo.list不存在,则新建之);同时,也定时检测处理列表文件doing.list文件是否存在,当doing.list文件不存在时,数据采集进程fp需要将待处理列表文件todo.list改名为doing.list交由数据处理进程bp处理;数据处理进程bp定时检测处理列表文件doing.list是否存在,如果存在,则逐行取出任务数据文件的路径信息,对列表文件中记录的任务数据文件逐个进行读取处理,特别需要注意的重点操作是,处理完毕后,数据处理进程bp需要将处理列表文件doing.list删除(否则无法完成新的待处理列表文件todo.list的切换处理)。
以上是本发明的工作原理描述。其中特别需要注意的是,需要保证源源不断生成的多个任务数据文件的文件名和路径信息,每一个都是唯一不相同的,否则会造成冲突,引起有效数据的覆盖写问题。
为了进一步阐述发明原理,下面将补充描述一个具体实施例作为补充(实现参考c语言)。
为了进行准确描述,实施例假设如下:
1、任务数据格式:
为了简化描述,此处假设任务数据对象由一组多个(property,value)二元组构成,其中property可能有以下字符串取值{“type”,“timestamp”,“data”},value中的type和timestamp一般采用普通文本字符串取值,而data一般有普通文本字符串和二进制数据两种取值。
对于普通文本字符串value,在任务数据文件中直接占用一行property:value\r\n,对于二进制数据,在任务数据文件中使用property:<length=?>\r\nvalue\r\nproperty:<end>\r\n的格式进行表达。例如:
type:http_content
timestamp:2018-06-0509:53:59
data:<length=10>
0123456789
data:<end>
2、任务数据文件命名规范:
发明中提到,通常需要保证源源不断生成的多个任务数据文件的文件名和路径信息,其中每一个都是唯一不相同的。本实施例约定一个特殊格式的文件名yyyymmdd_hhmmss_id.task进行解决。其中,yyyy指代四位数字的年份(如2018),mm指代2位数字的月份(取值01~12),dd指代2位数字的天数(取值01~31),hh指代24小时制的小时数(取值00~23),mm指代2位数字的分钟数(取值00~59),ss指代2位数字的秒数(取值00~59),id指代一个整数,表示同一秒内产生的第id个任务数据文件(秒数不变时,id取值增1,当秒数变化时,id重置为1)。
本发明主要涉及三个主要流程:
1、数据采集流程
数据采集是软件的输入基础,由数据采集进程fp中的文件总线写模块实现。从各种数据采集硬件设备(如网卡)上得到的数据,经过简单处理后,封装为任务数据对象objtask,并序列化到任务数据文件中。
如图2所示,其主要步骤如下:
1)在数据采集进程中,对写文件锁lockw进行加锁操作;
2)检查当前任务数据文件的文件指针file*fp是否有效(非空),若fp有效则转步骤7),若fp无效,则继续;
3)获取系统当前时间戳变量timenow(包括:年月日时分秒),并与缓存的时间戳变量timeinuse进行比对,若相同,则将id变量增加1,若不相同,则将timenow赋值给timeinuse,并将id变量重设为1;
4)以yyyymmdd_hhmmss_id为格式模板,根据时间戳变量timeinuse和id变量,通常在c程序中,可使用sprintf(filename,"%04d%02d%02d_%02d%02d%02d_%05d.task",year,month,day,hour,minute,second,id)生成任务数据文件的文件名(形如20180605_145030_00005.task,代表2018年6月5日14时50分30秒内第5次产生的新文件);
5)在任务数据文件的文件名filename前附加上合适的前缀目录路径,生成完整可访问的文件路径filepath;
6)根据文件路径filepath,使用fopen(filepath,“at”)打开任务数据文件,并返回文件指针fp;
7)检查待处理列表文件todo.list是否存在,若存在,则转步骤9),否不存在,则继续;
8)新建待处理列表文件todo.list;
9)将新产生的任务文件的路径filepath,附加写入到待处理列表文件todo.list的末尾行;
10)获取当前任务数据文件的文件大小filesize;
11)计算任务数据对象objtask将要写入到文件中的字节大小objsize;
12)对filesize和objsize进行求和得到size_sum,如果size_num大于任务数据文件的最大尺寸(该值一般根据应用程序的配置进行制定,通常要求小于4g),则关闭当前任务数据文件的文件后转步骤3),否则继续;
13)将任务数据对象objtask按照约定的数据任务格式,写入到fp指向的任务数据文件中(注意优先写入type和timestamp属性);
14)结束,对写文件锁lockw进行解锁;
2、任务切换流程
任务切换是本发明的核心实现,由数据采集进程fp中的定时切换模块实现。目的是,在合适的时机,将待处理列表文件todo.list动态更名为处理列表文件doing.list。
如图3所示,该流程由一个秒级定时器周期运行,其主要步骤如下:
1)检查处理列表文件doing.list是否存在,若存在,则转步骤7),否则继续;
2)检查待处理列表文件todo.list是否存在,若不存在,则转步骤7),否则继续;
3)在数据采集进程中,对写文件锁lockw进行加锁操作;
4)关闭待处理列表文件todo.list和当前任务数据文件的文件指针fp;
5)将待处理列表文件todo.list改名为doing.list;
6)对写文件锁lockw进行解锁操作;
7)睡眠1秒钟,释放cpu运行资源(避免空循环造成cpu高占用);
8)结束;
3、数据处理流程
数据处理由数据处理进程bp中的文件总线读模块实现。目的是,对数据采集进程生成的任务数据文件进行处理,并在处理完毕后,及时进行移除。
如图4所示,该流程和任务切换流程类似,由一个秒级定时器周期运行,其主要步骤如下:
1)检查处理列表文件doing.list是否存在,若不存在,则转步骤9),否则继续;
2)使用fopen打开doing.list,返回file*fpdoinglist;
3)从处理列表文件doing.list读取一行字符串line_string,若遇到文件尾则关闭文件后转步骤8),否则继续;
4)检查字符串line_string对应文件路径下的任务数据文件是否存在,不存在则转步骤3),否则继续;
5)使用fopen打开line_string对应文件路径下的任务数据文件,返回file*fptask;
6)从任务数据文件fptask中读取一个任务数据对象objtask,若遇到文件尾读取失败,则关闭文件fptask后转步骤3),否则继续;
7)对读取到的任务数据对象objtask进行后续处理(可通过初始化时传入的回调处理函数进行复杂处理)后,转步骤6);
8)删除处理列表文件doing.list;
9)睡眠1秒钟,释放cpu运行资源(避免空循环造成cpu高占用);
10)结束;
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!