一种列表页信息的提取方法及装置与流程
本发明涉及网页数据分析。
背景技术:
列表显示方式是一种网页显示批量数据常用方式,比如各种搜索引擎搜索到的结果,或者购物网站的商品。在数据分析领域中,由于无法直接访问网站数据库,只能通过网络爬虫的方式抓取网页内容。网页内容中的列表显示内容是数据分析的对象。但是一张完整的网页除了数据分析的对象中的列表内容之外,还包括其他内容,比如广告信息、用户信息以及其他各种信息。为此,需要从网页所提供的诸多信息中提取列表的内容。
技术实现要素:
本发明所要解决的问题:
1、从网页中提取列表内容。
2、由于网页经常变动,特别是列表内容的数据项不固定。
为解决上述问题,本发明采用的方案如下:
根据本发明的一种列表页信息的提取方法,包括分析步骤和抽取步骤;所述分析步骤对样例页进行dom分析,分析出样例页数据类别和对应元素路径;所述抽取步骤根据样例页目标数据的类别和对应元素路径,抽取出列表页中对应元素中的文本信息;
所述分析步骤包括样例页加载步骤、列表区定位步骤、记录块定位步骤以及数据项分析步骤;
所述样例页加载步骤:根据样例页url通过页面分析模块模拟浏览器加载样例页,得到样例页的htmldom树;
所述列表区定位步骤:遍历样例页的htmldom树中的元素,根据元素的宽高数据判断其是否为列表区;
所述记录块定位步骤:遍历列表区元素的子元素,通过子元素的宽高数据的比较以及子元素的子元素节点比较判断是否存在连续的子元素作为记录块;
所述数据项分析步骤:遍历记录块元素的叶子元素,并提取相应叶子元素的文本内容,然后对相应叶子元素的文本内容进行语义分析得到数据类型,获得数据类型和对应元素路径;
所述抽取步骤包括列表页加载步骤、信息提取步骤;
所述列表页加载步骤:根据列表页url通过页面分析模块模拟浏览器加载样例页,得到列表页的htmldom树;
所述信息提取步骤:根据数据类型和对应元素路径从列表页的htmldom树中提取与对应元素路径相匹配的记录块中的文本内容,并使记录块数据项的文本内容与数据类型对应。
进一步,根据本发明的列表页信息的提取方法,还包括数据项验证步骤;
数据项验证步骤:遍历其他记录块元素的叶子元素,并提取相应叶子元素的文本内容,然后对相应叶子元素的文本内容进行语义分析得到数据类型,然后将得到的数据类型和对应元素路径与所述数据项分析步骤得到的数据类型和对应元素路径相比较,判断两者是否一致。
根据本发明的一种列表页信息的提取装置,包括分析模块和抽取模块;所述分析模块用于对样例页进行dom分析,分析出样例页数据类别和对应元素路径;所述抽取模块用于根据样例页目标数据的类别和对应元素路径,抽取出列表页中对应元素中的文本信息;
所述分析模块包括样例页加载模块、列表区定位模块、记录块定位模块以及数据项分析模块;
所述样例页加载模块,用于:根据样例页url通过页面分析模块模拟浏览器加载样例页,得到样例页的htmldom树;
所述列表区定位模块,用于:遍历样例页的htmldom树中的元素,根据元素的宽高数据判断其是否为列表区;
所述记录块定位模块,用于:遍历列表区元素的子元素,通过子元素的宽高数据的比较以及子元素的子元素节点比较判断是否存在连续的子元素作为记录块;
所述数据项分析模块,用于:遍历记录块元素的叶子元素,并提取相应叶子元素的文本内容,然后对相应叶子元素的文本内容进行语义分析得到数据类型,获得数据类型和对应元素路径;
所述抽取模块包括列表页加载模块、信息提取模块;
所述列表页加载模块,用于:根据列表页url通过页面分析模块模拟浏览器加载样例页,得到列表页的htmldom树;
所述信息提取模块,用于:根据数据类型和对应元素路径从列表页的htmldom树中提取与对应元素路径相匹配的记录块中的文本内容,并使记录块数据项的文本内容与数据类型对应。
进一步,根据本发明的列表页信息的提取装置,还包括数据项验证模块;
数据项验证模块,用于:遍历其他记录块元素的叶子元素,并提取相应叶子元素的文本内容,然后对相应叶子元素的文本内容进行语义分析得到数据类型,然后将得到的数据类型和对应元素路径与所述数据项分析模块得到的数据类型和对应元素路径相比较,判断两者是否一致。
本发明的技术效果如下:
1、本发明通过样例页面分析后得到数据类别和对应元素路径后,再根据数据类别和对应元素路径进行批量的列表页信息提取,而不是对每个列表页都进行列表内容分析后提取,由此可以大大加快数据提取速度。
2、通过对数据项的语义分析,得到数据项的数据类型,然后再构建数据类别和对应元素路径的对应关系,即使记录块的数据项内容发生改变,提取的结果内容可以与上一次提取的内容保持一致,从而保持存储的一致性,从而大大提高自动化程度。
3、本发明对列表页的记录块定位准确。
附图说明
图1、图2、图3、图4、图5和图6是示例列表页内容。
具体实施方式
下面结合附图对本发明做进一步详细说明。
本实施例是一种列表页信息的提取装置。该装置通过程序指令集实现,包括分析模块、抽取模块、存储模块以及语义分析模块。分析模块用于对样例页进行dom分析,分析出样例页数据类别和对应元素路径。抽取模块用于根据样例页目标数据的类别和对应元素路径,抽取出列表页中对应元素中的文本信息。存储模块用于将抽取模块所提取的文本信息存入数据库。语义分析模块用于对于数据项的文本进行分析归类成数据类别。其中样例页是列表页的一个样例页面。具体来说,比如搜索结果页面,各种关键词搜索结果的列表页面布局格式相同,因此只需要分析其中一个关键词搜索结果的列表页面,其他关键词搜索结果的搜索结果的列表页面布局格式可以直接参照引用。考虑到网站网页重新设计的问题,可以每天执行一次分析模块的分析后,再执行抽取模块的抽取步骤。
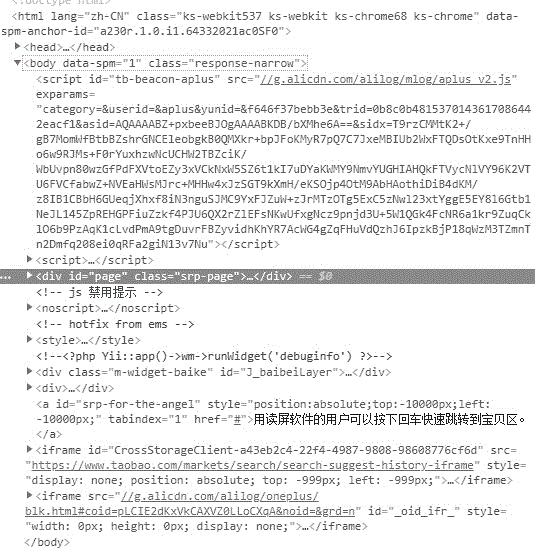
图1、图2、图3、图4、图5、图6是本文样例页示例。该示例是通过chrome开发者工具得到的淘宝网一个随机商品名搜索结果页面的html数据,这些html数据构成htmldom树。
分析模块进行分析的具体步骤如下:
首先,样例页加载步骤:根据样例页url通过页面分析模块模拟浏览器加载样例页,得到样例页的htmldom树。本文中的页面分析模块是一种没有界面的浏览器,也就是无头浏览器,或者页面分析工具。无头浏览器有很多种,比如phantomjs、slimerjs、htmlunit。本实施例的页面分析模块采用phantomjs。phantomjs能够根据url下载页面并构建htmldom树。phantomjs能够模拟可视化的界面,能够计算出htmldom树每个可视化元素在可视化界面上显示时的坐标位置和宽高数据。本文中的元素是指htmldom树上的节点,体现在html文档上,为html上的一个标签。样例页加载后是对样例页的htmldom树分析步骤。样例页的htmldom树分析步骤分成三个步骤:首先是列表区定位,然后记录块定位,数据项分析以及数据项验证。列表区是列表页上用于列表显示记录块的区域。列表区由多个记录块组成。记录块由数据项组成。比如购物网站的商品列表页面中,每件商品是一个记录块,商品属性是数据项。商品属性由很多种,比如商品名称、类别、价格、商家等,因此记录块包含多个数据项。
列表区定位步骤用于找出样例页的htmldom树中记录块的父节点。该记录块的父节点本文称为列表区元素。具体来说,通过元素的x,y坐标及高宽值,判断矩形的大小及位置,获取符合要求的dom节点,确定其为对应的列表区,进而获取列表页相应元素的xpath。最后输出的xpath表示了列表区元素的在htmldom树中的位置。“通过元素的x,y坐标及高宽值,判断矩形的大小及位置,获取符合要求的dom节点,确定其为对应的列表区”的实际方法有很多种,本实施例中,采用“根据元素的宽高数据判断其是否为列表区”的方法,更为具体来说是下级节点和上级节点之间的屏占比例确定。当某节点在其父节点屏占比超过60%时,该节点为潜在列表区元素,而当该节点还满足子孙节点在该节点中屏占比不超过8%时,该节点为列表区元素。遍历时,当找到潜在列表区元素时,遍历该潜在列表区元素的子节点。
以前述本文样例示例为例,图1中,body标签是htmldom树的根节点。遍历时首先从该根节点元素开始。该body元素的宽高数据为:1000×5477。该body元素有多个子节点,在这些子节点中,id为page的div元素的宽高数据为:1000×5477。id为page的div元素与其父节点body元素之间的屏占比为100%,因此,id为page的div元素为潜在列表区元素,因此遍历id为page的div元素的子节点。该id为page的div元素的子节点如图2所示。该id为page的div元素的子节点中,id为main的div元素的宽高数据为:1000×5097。id为main的div元素与其父节点id为page的div元素屏占比为93%,因此,id为main的div元素为潜在列表区元素,因此遍历id为main的div元素的子节点。该id为main的div元素的子节点如图3所示。id为main的div元素的子节点中,第三个div元素的宽高数据为1000×4672与其父节点的屏占比91%是为潜在列表区元素。id为main的div元素的第三个div元素的子节点中,class为grid-left的div元素的宽高数据为810×4672与其父节点的屏占比为79%是为潜在列表区元素。class为grid-left的div元素的子节点,如图4所示,其中id为mainsrp-itemlis的div元素的宽高数据为810×4128与其父节点的屏占比88%是为潜在列表区元素。id为mainsrp-itemlis的div元素的子节点如图5所示。通过上述方法层层分析,可以得到,class为gridg-clearfix的div元素是潜在列表区元素。遍历class为gridg-clearfix的div元素的子节点以及子孙节点后,任何子孙节点在该节点中屏占比不超过8%。class为gridg-clearfix的div元素的孙子节点,如图6所示。因此,class为gridg-clearfix的div元素为列表区元素。最终得到列表区元素的xpath为“//*[@id="mainsrp-itemlist"]/div/div”。另外,列表区定位遍历htmldom树时,本领域技术人员理解,需要跳过非可视化节点,以及浮动区域。xpath也就是元素路径。
记录块定位步骤用于定位样例页的htmldom树中列表区元素的记录块节点。本实施例中,该步骤具体为:遍历列表区元素的子元素,通过子元素的宽高数据的比较以及子元素的子元素节点比较判断是否存在连续的子元素作为记录块。遍历列表区元素的子元素时,首先剔除跳过非可视化节点。如图5、6所示,class为gridg-clearfix的div元素的三个子节点,均为非可视化节点,跳过后,其子节点的子节点作为class为gridg-clearfix的div元素的子元素进行遍历。如图6所示,class为itemj_mouseronverreqitem-ad的div元素均为class为gridg-clearfix的div元素的子元素。class为itemj_mouseronverreqitem-ad的div元素的宽高数据为182×322。每个div元素的宽高数据相同,因此,可以确定class为“itemj_mouseronverreqitem-ad”的div元素为记录块。得到两个记录块相对于列表区元素的xpath:“/div[1]/div[*]”和“/div[2]/div[*]”。将两个记录块xpath合并后得到最终的“/div[*]/div[*]”。本领域技术人员理解“*”为通配符。
本实施例示例中的列表区元素的子元素的宽高数据完全相同,因此很容易确定,对于列表区元素的子元素的宽高数据不尽相同的情况下,可以进一步分析子元素的子元素。具体来说,比较各个子元素的dom树结构是否相同。如果相同,则为记录块。
数据项分析步骤:遍历记录块元素的叶子元素,并提取相应叶子元素的文本内容,然后对相应叶子元素的文本内容进行语义分析得到数据类型,获得数据类型和对应元素路径。叶子元素也就是htmldom树中的节点。需要指出的是,叶子元素需要屏蔽修饰性节点,具体来说反应在html文档中,诸如a,b,i,u,p,span,strong等标签为修饰性节点需要屏蔽。比如,某一节点html标记如下:
<divclass="priceg_priceg_price-highlight">
<span>¥</span><strong>118.00</strong>
</div>
屏蔽span和strong标签后,实际的结构为:
<divclass="priceg_priceg_price-highlight">
¥118.00
</div>
因此,该div元素为实际的叶子元素,而非span和strong。由此提取该叶子元素的文本内容为:¥118.00。该叶子元素的文本内容构成记录块的一个数据项。
“对相应叶子元素的文本内容进行语义分析得到数据类型”,也就是对数据项归类分析。以淘宝网搜索结果的某一记录块为例,该记录块得到数据项如下:
数据项1:文本内容为“¥59.00”,相对xpath为“/div[2]/div[1]/div[1]”;
数据项2:文本内容为“6818人付款”,相对xpath为“/div[2]/div[1]/div[2]”;
数据项3:文本内容为“哈尔斯保温杯男士女高档316不锈钢水杯便携商务定制刻字泡茶杯子”,相对xpath为“/div[2]/div[2]”;
数据项4:文本内容为“哈尔斯娜娅莎专卖店”,相对xpath为“/div[2]/div[3]/div[1]”;
数据项5:文本内容为“上海”,相对xpath为“/div[2]/div[3]/div[2]”。
其中,数据项1的文本内容“¥59.00”,由于其中包括“¥”符号,因此归类为“价格”
数据项2的文本内容“6818人付款”归类为“销量”;数据项3的文本内容归类为“商品名称”,数据项4的文本内容归类为“店铺”,数据项5的文本内容归类为“地点”。由此上述记录块最终得到的数据类型和对应元素路径如下:
数据类型“价格”,对应元素路径为“/div[2]/div[1]/div[1]”;
数据类型“销量”,对应元素路径为“/div[2]/div[1]/div[2]”;
数据类型“商品名称”,对应元素路径为“/div[2]/div[2]”;
数据类型“店铺”,对应元素路径为“/div[2]/div[3]/div[1]”;
数据类型“地点”,对应元素路径为“/div[2]/div[3]/div[2]”。
其中对应元素路径也就是数据项元素路径。上述文本内容的归类分析由前述语义分析模块所实现。
数据项验证步骤是对数据项分析步骤得到的结果进行验证。数据项分析步骤中,通常只需要对第一个记录块进行分析即可得到相应的“数据类型和对应元素路径”而数据项验证则是对其他样例页中其他的记录块进行数据项分析,然后将得到的“数据类型和对应元素路径”逐个与前面第一个记录块进行数据项分析得到的“数据类型和对应元素路径”比较是否一致。
需要指出的是,在某些列表页中,记录块严格一致的情况下,数据项验证步骤可以省略。
另外,分析模块的输出除了上述的“数据类型和对应元素路径”之外,还包括列表区元素路径,本示例下为:“//*[@id="mainsrp-itemlist"]/div/div”;记录块路径,本示例下为“/div[*]/div[*]”。其中记录块路径是列表区元素路径的相对路径。“数据类型和对应元素路径”中的数据项元素路径是记录路径的相对路径。
抽取模块对列表进行抽取的步骤通常是一个批量处理的步骤,也就是对很多列表页执行抽取步骤。抽取模块执行抽取步骤包括两个步骤:列表页加载步骤和信息提取步骤。列表页加载步骤,也就是,根据列表页url通过页面分析模块模拟浏览器加载样例页,得到列表页的htmldom树。列表页加载步骤和前述样例页加载步骤相同,本文不再赘述。
信息提取步骤,也就是,根据数据类型和对应元素路径从列表页的htmldom树中提取与对应元素路径相匹配的记录块中的文本内容。具体步骤如下:首先,根据分析模块得到的列表区元素路径找到相应的列表区元素,然后遍历所有与记录块路径通配符相匹配的记录块元素,对遍历到的记录块元素进行数据项文本内容提取。数据项文本内容提取时,根据数据项元素路径,提取文本内容,再根据数据项类型组成数据块。以前述列表页记录块为例,得到的数据块如下:
数据类型“价格”,文本内容为“¥59.00”;
数据类型“销量”,文本内容为“6818人付款”;
数据类型“商品名称”,文本内容为“哈尔斯保温杯男士女高档316不锈钢水杯便携商务定制刻字泡茶杯子”;
数据类型“店铺”,文本内容为“哈尔斯娜娅莎专卖店”;
数据类型“地点”,文本内容为“上海”。
得到的数据块通过前述存储模块进行存储。
- 还没有人留言评论。精彩留言会获得点赞!