一种面向大数据的K近邻连接查询方法与流程
本发明属于数据库技术领域,具体涉及一种面向大数据的k近邻连接查询方法。
背景技术:
k-近邻连接(k-nearestneighborjoin,简称knnj)查询是空间数据库中一种非常重要和频繁的数据库操作,在k-近邻分类、k-均值聚类、抽样评估、遗漏值评估等应用中,knnj得到了广泛的应用。由于近邻(nn)查询和join查询在数据库中都是极为耗时的操作,尤其当数据集很大或者维度很高时,knnjoin的代价将会变得惊人。
随着空间数据的急剧增长,单个节点单进程方法已不再适用,提出云计算环境下的分布式knnj查询方法成为了目前急需解决的问题。mapreduce是google提出的一种集群上处理大规模数据集的分布式并行编程模型,也是目前云计算环境中的核心计算模式。为了有效地解决大规模数据集的knnj查询问题,zhang等人首先提出了hadoop平台下较高效的两张表之间的knnj算法(h-zknnj)。
h-zknnj算法包括了3个串行执行的mapreduce任务。第1个mapreduce任务从hdfs中读取两张表的数据,进行采样,确定数据的划分写入hdfs。第2个mapreduce任务需要再次从hdfs读取两张表的数据以及第1mapreduce任务的结果,对两张表进行切分,并在分块中进行knnjoin的查询,结果写入hdfs。第3个mapreduce任务从hdfs读取前面产生的中间结果进一步处理,得到最终结果写入hdfs。h-zknnj算法需要从hdfs分别读写3次,且hdfs默认写三份。在现有的hadoop平台下,每个mapreduce任务都需要读写hdfs,即使某些mapreduce任务产生的数据仅是临时数据。显然,这种表达作业依赖关系的方式是低效的,在读写数据量很大时会产生大量不必要的io开销。
因此需要一种架构合理、两个大数据集之间的k近邻连接查询处理以提高k近邻连接查询处理的响应时间的面向大数据的k近邻连接查询方法。
技术实现要素:
本发明的目的是提供一种面向大数据的k近邻连接查询方法,以解决现有技术,作业依赖关系的方式是低效的,在读写数据量很大时会产生大量不必要的io开销等问题。
本发明提供了如下的技术方案:
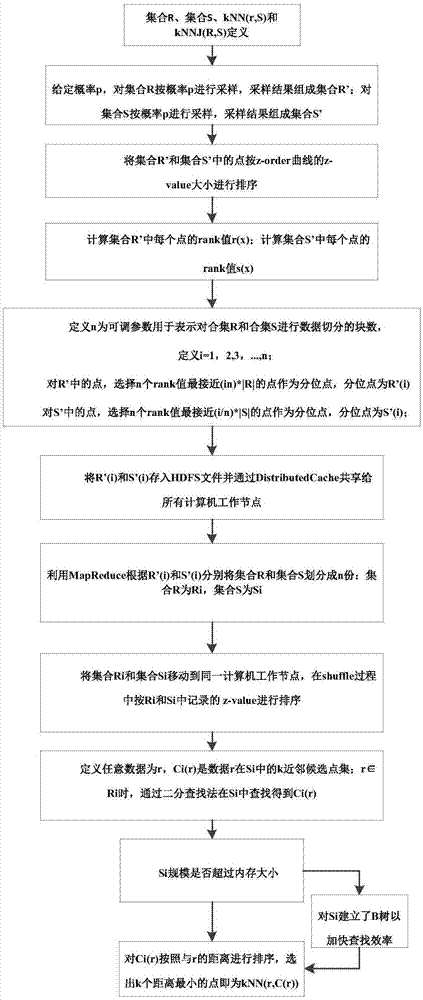
一种面向大数据的k近邻连接查询方法,包括以下步骤:
s1、给定rd空间中两个数据集合r和集合s,r和s分别表示一个d维的空间关系,其中每条记录r∈r(s∈s)都是一个d维的点;
定义:knn(r,s),给定一个查询对象r∈r及正整数k,从空间关系s中找出距离r最近的k个对象;
定义:knnj(r,s),给定两个空间关系r和s,knnj(r,s)={(r,knn(r,s))|forallr∈r};
s2、给定概率p,对集合r按概率p进行采样,采样结果组成集合r’;对集合s按概率p进行采样,采样结果组成集合s’;
s3、将集合r’和集合s’中的点按z-order曲线的z-value大小进行排序;
s4、计算集合r’中每个点的rank值r(x);计算集合s’中每个点的rank值s(x);
s5、定义n为可调参数用于表示对合集r和合集s进行数据切分的块数,定义i=1,2,3,...,n;对r’中的点,选择n个rank值最接近(i/n)*|r|的点作为分位点,分位点为r’(i);对s’中的点,选择n个rank值最接近(i/n)*|s|的点作为分位点,分位点为s’(i);
s6、将r’(i)和s’(i)存入hdfs文件并通过distributedcache共享给所有计算机工作节点;
s7、利用mapreduce根据r’(i)和s’(i)分别将集合r和集合s划分成n份:集合r为ri,集合s为si;
s8、将集合ri和集合si移动到同一计算机工作节点,在shuffle过程中按ri和si中记录的z-value进行排序;
s9、定义任意数据为r,ci(r)是数据r在si中的k近邻候选点集;r∈ri时,通过二分查找法在si中查找得到ci(r);
s10、si规模是否超过内存大小,
若是,对si建立了b树以加快查找效率;
s11、对ci(r)按照与r的距离进行排序,选出k个距离最小的点即为knn(r,c(r))。
优选的,采用欧氏距离表示两个记录r和s之间的距离。
优选的,集合r为查询点集合,集合s为被查询点集合。
本发明的有益效果是:
1.本发明一种面向大数据的k近邻连接查询方法,整体架构合理、两个大数据集之间的k近邻连接查询处理以提高k近邻连接查询处理的响应时间;
2.通信代价,基于采样技术和z-order曲线确定空间划分函数,从ri和si(i∈[1,α])按照1/(ε2|r|)和1/(ε2|s|)概率进行采样,总通信代价为o(α/ε2),将ri和si划分到对应分块(rij,sij)中,对于r∈ri,只会分到一个分块中,通信代价为o(α|r|)。对于s∈si,有可能会被复制到两个分块中。在分块sij中,从邻近块中复制的点个数最多为2(k+ε|s|)。通常ε取值很小,因此复制的数据量为o(k),对于si,通信代价为o(α(|s|+nk))。整个方法的通信代价为o(α(1/ε2+|s|+|r|+k|r|+nk))。α为一个较小的常量,n,k,1/ε2与|s|,|r|相比都很小,得出算法通信代价为o(1/ε2+|s|+(k+1)|r|);
3.计算代价,首先对样本ri’和si’按z-value进行排序,得到ri划分点后计算si划分需要找到[kp]个邻居节点,计算代价为o(nlog(|si’|))。按z-value进行排序总的计算代价为o(α(|r|+|s|+|r’|log|r’|+|s’|log|s’|+nlog(|s’|))),即o(α(|r|+|s|+(1/ε2)log(1/ε2)+nlog(1/ε2)))。对sij进行二分查找时计算代价为o((|rij|+|sij|)log|sij|)。如果数据划分能够使得负载均衡,则计算代价为o((|r|/n+|s|/n)log(|s|/n)),数据划分后进行查询处理总的计算代价为o(α(|r|+|s|)log(|s|/n))(如果负载不均衡,最坏的情况下,总计算代价为o(α(|r|+|s|)log|s|))。因此总计算代价为o(α((1/ε2)log(1/ε2)+nlog(1/ε2)+(|r|+|s|)log|s|+k|r|logk)),由于α为数值很小的常量,并且k|r|logk远小于(|r|+|s|)log|s|,因此总计算代价即为o(α(|r|+|s|+(1/ε2)log(1/ε2)+nlog(1/ε2)))。
4.i/o代价,进行数据划分需要从hdfs读取r和s,i/o代价为o(|r|+|s|)。向hdfs写入分位点信息,i/o代价为o(3αn)。计算c(r)需要从hdfs读取r和s,i/o代价为o(|r|+|s|)。向hdfs写入最终结果(r,knn(r,c(r)))(r∈r),i/o代价为o(3k|r|)。整个算法总的输入代价为o(2(|r|+|s|)),输出代价为o(3αn+3k|r|)。由于α,n均为较小的常数,因此输出代价为o(3k|r|)。在数据量特别大的情况下,i/o已成为性能瓶颈,h-zknnj输入代价为o((α+1)(|r|+|s|)+αk|r|),输出代价为o(3((α+αk+k)|r|+α|s|))。与h-zknnj算法相比,d-knnj算法的i/o代价明显减小,提高了整个算法的执行效率。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明结构流程示意图;
图2是本发明在mapreduce中的分布式执行流程;
图3是本发明在对数据进行z-order划分的示意图;
图4是本发明在大数据分析引擎中的实现流程。
具体实施方式
如图1-3所示,一种面向大数据的k近邻连接查询方法,包括以下步骤:
s1、给定rd空间中两个数据集合r和集合s,r和s分别表示一个d维的空间关系,其中每条记录r∈r(s∈s)都是一个d维的点;
定义:knn(r,s),给定一个查询对象r∈r及正整数k,从空间关系s中找出距离r最近的k个对象;
定义:knnj(r,s),给定两个空间关系r和s,knnj(r,s)={(r,knn(r,s))|forallr∈r};
s2、给定概率p,对集合r按概率p进行采样,采样结果组成集合r’;对集合s按概率p进行采样,采样结果组成集合s’;
s3、将集合r’和集合s’中的点按z-order曲线的z-value大小进行排序;
s4、计算集合r’中每个点的rank值r(x);计算集合s’中每个点的rank值s(x);
s5、定义n为可调参数用于表示对合集r和合集s进行数据切分的块数,定义i=1,2,3,...,n;对r’中的点,选择n个rank值最接近(i/n)*|r|的点作为分位点,分位点为r’(i);对s’中的点,选择n个rank值最接近(i/n)*|s|的点作为分位点,分位点为s’(i);
s6、将r’(i)和s’(i)存入hdfs文件并通过distributedcache共享给所有计算机工作节点;
s7、利用mapreduce根据r’(i)和s’(i)分别将集合r和集合s划分成n份:集合r为ri,集合s为si;
s8、将集合ri和集合si移动到同一计算机工作节点,在shuffle过程中按ri和si中记录的z-value进行排序;
s9、定义任意数据为r,ci(r)是数据r在si中的k近邻候选点集;r∈ri时,通过二分查找法在si中查找得到ci(r);
s10、si规模是否超过内存大小,
若是,对si建立了b树以加快查找效率;
s11、对ci(r)按照与r的距离进行排序,选出k个距离最小的点即为knn(r,c(r))。
具体的,采用欧氏距离表示两个记录r和s之间的距离,集合r为查询点集合,集合s为被查询点集合。
本具体实施方式一为:
设有集群有8个节点,cpu:xeone5-2620(双核2.00ghz),内存:8g,硬盘:6t(硬盘实际可用空间为44.03t);操作系统:centos6.4(64bit);分布式文件系统:hdfs;dag框架是基于mapreduce框架之上的,其中一个节点为master,剩下节点均为worker节点。
采用来自openmapstreet项目的真实数据集。每个数据集表示美国一个州的道路网信息。整个数据集包括了美国50个州的信息,超过160,000,000条记录,数据量达到6.6gb。每条记录包括:记录标识id,二维坐标和其他描述信息。为了测试性能并与其他算法进行性能对比,从数据集中随机提取两个样本集r和s,其中,r和s的数据规模分别为10m,20m,40m和80m。采用mxn标识数据配置,其中m和n分别表示r和s中的数据条数(百万为单位),如(40x80)表示r中有40m条记录,s中有80m条记录。默认采样概率ε=0.003。
h-zknnj算法是mapreduce框架下面向大规模数据的knnj查询算法。由于其算法是基于mapreduce框架的,每个mapreduce任务都需要读写hdfs,即使某些mapreduce任务产生的数据仅是临时数据。显然,这种表达作业依赖关系的方式效率不高。
在进行对比时,固定k值为10,数据规模从10*10变化到80*80。图3显示了固定k=10时,在不同数据规模条件下,本方法与h-zknnj算法性能对比实验结果。显然本方法的性能要优于h-zknnj,随着数据量的增大的,优势将会更加明显。
本具体实施方式二为:
以一种云数据管理系统-nhclouddb为例,如图4所示,
(1)客户端ui提交的sql首先进入driver,sql语句的格式形如:select*fromknnj(r,d,k,p),其中,r,d分别为关系表,p为进行k近邻连接的属性。
(2)然后driver会为此次sql的执行创建一个session,driver维护整个session的生命周期;
(3)driver首先将sql传送给查询编译器compiler;
(4)compiler对sql进行词法、语法分析;
(5)查询编译器对sql进行解析,使用antlr语法解析器来对sql进行解析,并生成相应的抽象语法树。
(6)进入到类型的检查和语法分析阶段,若该查询包含k近邻连接操作knnj,提取sql中进行k近邻连接查询的两个数据表以及进行k近邻运算的属性;
(7)生成3个任务:task1、task2、task3,task1对连接的两个表进行数据划分,得到分位点信息,根据分位点信息对连接的两个表进行数据的划分;task2在数据分块s中查找对应分块r中每个点r的k近邻候选点集c(r);task3根据c(r)得出r中每个元素r的knn集合c(r);
(8)将task1、task2、task3进行组合成为有向无环图dag,并将3个task合并成一个大作业,生成dag有向无环图操作树。
(9)将dag转化称相应的mapreduce或spark任务。生成的mapreduce任务或spark任务交给nhclouddb的执行引擎来执行;
(10)执行引擎会与hadoop进行交互,将任务交给hadoop或spark来执行,并从hadoop取得最终的执行结果,并返回给用户。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!