一种基于深度相关匹配模型的信息检索方法与流程
本发明涉及计算机领域,尤其涉及一种基于深度相关匹配模型的信息检索方法。
背景技术:
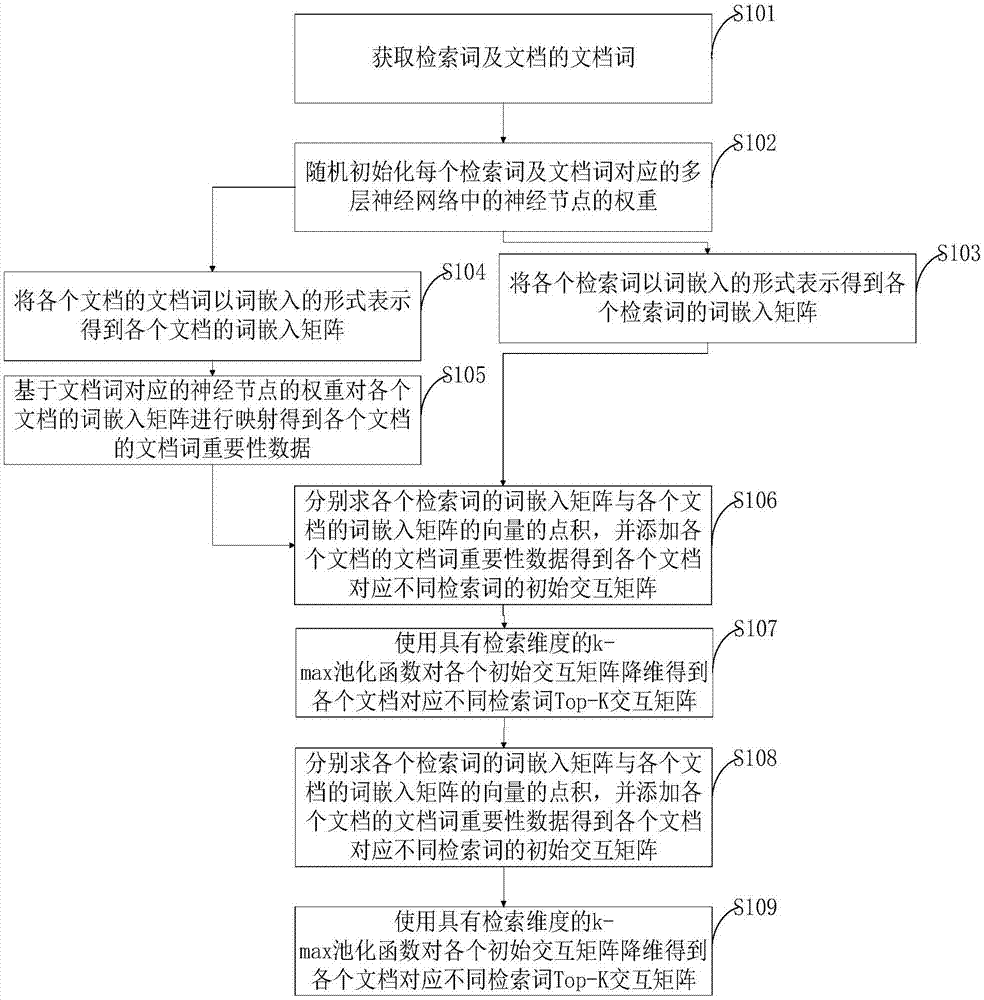
:在传统的信息检索模型中,它们会根据精确匹配信号测量文档的相关性。也就是说,相关性得分通过来自文档的检索词的频率所确定。因为忽略了相似匹配信号,这类模型经常面临典型的单词不匹配问题。最近,深度神经网络在许多自然语言处理任务中取得了巨大成功。同时,这些深度神经网络也已应用于信息检索,称为神经信息检索(即neuir)。他们用词嵌入作为单词的表达,再基于这些表达来构建一些模型,这些模型的检索性能有比较大的提高。单词的重要性对信息检索的模型非常重要。在传统的检索模型中,他们基于逆文档频率(即idf)来测量单词的重要性。由于这些模型仅考虑与检索词相同的文档词,因此仅考虑检索词的idf就足够了。最近,神经检索模型采用深度神经网络来模拟检索词和文档词之间的相似匹配。通过这种方式,与检索词相似的词也能够被检索到。然而,现有的神经检索模型忽略了这些相似检索词的重要性,检索性能较差。因此,如何提供一种新的技术方案,提高检索性能成为了本领域技术人员急需解决的问题。技术实现要素:针对现有技术中存在的上述不足,本发明公开了一种基于深度相关匹配模型的信息检索方法,充分考虑了相似检索词的重要性,显著提高了检索的性能。为解决上述技术问题,本发明采用了如下的技术方案:一种基于深度相关匹配模型的信息检索方法,包括如下步骤:获取检索词及文档的文档词;随机初始化每个检索词及文档词对应的多层神经网络中的神经节点的权重;将各个检索词以词嵌入的形式表示得到各个检索词的词嵌入矩阵;将各个文档的文档词以词嵌入的形式表示得到各个文档的词嵌入矩阵;基于文档词对应的神经节点的权重对各个文档的词嵌入矩阵进行映射得到各个文档的文档词权重向量;分别求各个检索词的词嵌入矩阵与各个文档的词嵌入矩阵的向量的点积,并添加各个文档的文档词权重向量得到各个文档对应不同检索词的初始交互矩阵;使用具有检索维度的k-max池化函数对各个初始交互矩阵降维得到各个文档对应不同检索词top-k交互矩阵;使用多层神经网络计算各个文档的top-k交互矩阵的检索得分;基于各个文档的检索得分的大小对各个文档进行排序,得到检索结果。优选地,所述多层神经网络可表示为其中,wk和bk分别表示第k层神经网络的权重矩阵和偏差,ak表示第k层神经网络的激活函数,gqi表示第i个检索词的权重系数,i=1,2,…,m,m表示检索词的总个数,s表示检索得分,k=1,2,…,l,l表示多层神经网络的网络总层数,表示第i个检索词第k层神经网络的top-k交互矩阵。优选地,第i个检索词的权重系数gqi=softmax(wqiqi),qi表示第i个检索词的词嵌入矩阵,wqi表示第i个检索词对应的多层神经网络中的神经节点的权重,softmax()表示归一化指数函数。优选地,任一文档中第i个检索词对应的降维后的top-k交互矩阵为其中,m表示检索词的总个数,tk表示具有检索维度的k-max池化函数,d为所述文档的词嵌入矩阵,gd为所述文档的文档词权重向量,gd={gd1,gd2,…,gdj,…,gdn},gdj为所述文档中第j个文档词的权重,gdj=wdjdj,wdj表示第j个文档词对应的多层神经网络中的神经节点的权重,dj为第j个文档词的词嵌入矩阵,j=1,2,…,n,n表示文档中包含的文档词的总个数,文档的词嵌入矩阵由所述文档中所有文档词的词嵌入矩阵组成。优选地,通过损失函数l(θ)对神经网络的参数进行优化,其中,θ表示神经网络中任意一种需要优化的参数,q表示检索词的集合,d+来自正样本文档集d+,d+表示与检索词正相关的文档词集,d-来自负样本文档集d-,d-表示与检索词无关和/或负相关的文档词集。综上所述,本发明公开一种基于深度相关匹配模型的信息检索方法,包括如下步骤:获取检索词及文档的文档词;随机初始化每个检索词及文档词对应的多层神经网络中的神经节点的权重;将各个检索词以词嵌入的形式表示得到各个检索词的词嵌入矩阵;将各个文档的文档词以词嵌入的形式表示得到各个文档的词嵌入矩阵;基于文档词对应的神经节点的权重对各个文档的词嵌入矩阵进行映射得到各个文档的文档词权重向量;分别求各个检索词的词嵌入矩阵与各个文档的词嵌入矩阵的向量的点积,并添加各个文档的文档词权重向量得到各个文档对应不同检索词的初始交互矩阵;使用具有检索维度的k-max池化函数对各个初始交互矩阵降维得到各个文档对应不同检索词top-k交互矩阵;使用多层神经网络计算各个文档的top-k交互矩阵的检索得分;基于各个文档的检索得分的大小对各个文档进行排序,得到检索结果。附图说明图1为本发明公开的一种基于深度相关匹配模型的信息检索方法的流程图。图2为本发明采用本发明的方法选择不同的top-k时的性能比较。具体实施方式下面结合附图对本发明作进一步的详细说明。如图1所示,本发明公开了一种基于深度相关匹配模型的信息检索方法,包括如下步骤:s101、获取检索词及文档的文档词;s102、随机初始化每个检索词及文档词对应的多层神经网络中的神经节点的权重;s103、将各个检索词以词嵌入的形式表示得到各个检索词的词嵌入矩阵;s104、将各个文档的文档词以词嵌入的形式表示得到各个文档的词嵌入矩阵;s105、基于文档词对应的神经节点的权重对各个文档的词嵌入矩阵进行映射得到各个文档的文档词权重向量;gd为文档词权重向量,首先用文档中所有的文档词的词嵌入进行映射,假设,文档有300个词,词嵌入为50维,那么文档词嵌入矩阵为300*50维,用文档词对应的多层神经网络中的神经节点的权重映射为300*1维,如果检索词有5个单词,则将300*1维的矩阵扩展为5*300*1维,即文档词权重向量。s106、分别求各个检索词的词嵌入矩阵与各个文档的词嵌入矩阵的向量的点积,并添加各个文档的文档词权重向量得到各个文档对应不同检索词的初始交互矩阵;每个文档的词嵌入矩阵与各个检索词的词嵌入矩阵都会得到一个初始交互矩阵,即一个文档的初始交互矩阵的个数等于检索词的个数。给定检索词和文档,每个检索词和文档的文档词均处于分布式表示中,以求点积的方式以形成待添加重要性数据初始交互矩阵,为了强调文档中的不同单词具有不同的显着性水平,将文档词的重要性添加到矩阵中,即将待添加重要性数据初始交互矩阵的值和文档词权重向量的值相加,得到初始交互矩阵。s107、使用具有检索维度的k-max池化函数对各个初始交互矩阵降维得到各个文档对应不同检索词top-k交互矩阵;文档中不重要的文档词也包括在初始交互矩阵中并参与了后续计算。通过我们的研究,与检索词具有高相关性的文档词基本上确定了文档的检索得分,低相关的文档词,如停用词,对检索得分的影响很低,在此基础上,我们提出了基于检索维度的top-k池化函数,以选择最优文档词,去除不良文档词。处理k-max池层后,对于每个文档都是选取前k个最强的文档词,整个文档维度的长度为k,它形成一个固定值,能够有效减少计算量,提高检索效率,并为传入神经网络提供条件。一般情况下,检索词或者文档中的文档词的词嵌入输入神经网路是不会改变的,但是由于词嵌入是通过其他数据训练而来,在当前数据训练或者预测时,难免会有偏差,因此,在当前数据训练的时候,神经网络也会像调整其他参数的值一样调整词嵌入的值,以此来调节数据的不一致问题。本发明充分利用现有的词嵌入来加速训练,突破了原始单词嵌入的局限,最大限度地避免了缺点。s108、使用多层神经网络计算各个文档的top-k交互矩阵的检索得分;s109、基于各个文档的检索得分的大小对各个文档进行排序,得到检索结果。本发明中,检索词可以以检索词集的形式存在,一个检索词集包括多个检索词。在传统的信息检索模型中,它们会根据精确匹配信号测量文档的相关性。也就是说,相关性得分通过来自文档的检索词的频率所确定。因为忽略了相似匹配信号,这类模型经常面临典型的单词不匹配问题。最近,深度神经网络在许多自然语言处理任务中取得了巨大成功。同时,这些深度神经网络也已应用于信息检索,称为神经信息检索(即neuir)。他们用词嵌入作为单词的表达,再基于这些表达来构建一些模型,这些模型性能上有比较大的提高。单词的重要性对信息检索的模型非常重要。在传统的检索模型中,他们基于逆文档频率(即idf)来测量单词的重要性。由于这些模型仅考虑与检索词相同的文档词,因此仅考虑检索词的idf就足够了。最近,神经检索模型采用深度神经网络来模拟检索词和文档词之间的相似匹配。通过这种方式,与检索词相似的词也能够被检索到。然而,现有的神经检索模型忽略了这些相似检索词的重要性,它们对模型的贡献也很大。以下面的例子为例:检索:介绍生活在水中的动物,如鲨鱼文档片段a:在水中游泳的海豚正在寻找食物。文档片段b:一只黄色小狗落入水中。从上面的例子可以看出,与精确匹配的信号“水”相比,“海豚”和“小狗”作为相似的匹配信号分别出现在文件a,b中。鉴于“水”和“鲨鱼”在检索中提供的语义环境,“海豚”的重要性应该大于“小狗”。因此,在不强调文档单词的重要性的情况下,很容易发生匹配错误。当强调词语的重要性时,它将对正确的匹配产生有利的贡献。因此,本发明在对检索和文档之间的相关性进行建模时考虑了文档词的重要性,具体来说,本发明的方法以检索和文档的文本的词嵌入为输入,通过深度神经网络自动提取相关信号,产生最终的检索得分,首先构建交互矩阵,其中每个元素表示相应检索词和文档词之间的交互。同时,我们将文档词的词嵌入压缩到一个小维度,并融合到交互矩阵中。这样,交互矩阵不仅可以捕获匹配信号,还可以捕获文档重要性。然后,我们在交互矩阵上应用top-k池化层,并获得必要的最强的k个相关信号。最强相关性信号与每个检索项相关联,并投影到多层神经网络中以获得检索层面的匹配分数。最后,网络所产生的匹配分数与权重控制网络点积以产生检索得分。与现有技术相比,采用本发明公开的方法,能够显著提升检索性能。本发明公开的方法,可以以一个深度相关匹配模型的形式存在,这个模型的工作原理即是本发明中s102至s109步骤中的方法。具体实施时,所述多层神经网络可表示为其中,wk和bk分别表示第k层神经网络的权重矩阵和偏差,ak表示第k层神经网络的激活函数,gqi表示第i个检索词的权重系数,i=1,2,…,m,m表示检索词的总个数,s表示检索得分,k=1,2,…,l,l表示多层神经网络的网络总层数,表示第i个检索词第k层神经网络的top-k交互矩阵,任一文档中第i个检索词对应的降维后的top-k交互矩阵为为多层神经网络第一层的输入。本发明中,激活函数可以采用softplus函数。具体实施时,第i个检索词的权重系数gqi=softmax(wqiqi),qi表示第i个检索词的词嵌入矩阵,wqi表示第i个检索词对应的多层神经网络中的神经节点的权重,softmax()表示归一化指数函数。具体实施时,任一文档中第i个检索词对应的降维后的top-k交互矩阵为其中,m表示检索词的总个数,tk表示具有检索维度的k-max池化函数,d为所述文档的词嵌入矩阵,gd为所述文档的文档词权重向量,gd={gd1,gd2,…,gdj,…,gdn},gdj为所述文档中第j个文档词的权重,gdj=wdjdj,wdj表示第j个文档词对应的多层神经网络中的神经节点的权重,dj为第j个文档词的词嵌入矩阵,j=1,2,…,n,n表示文档中包含的文档词的总个数,文档的词嵌入矩阵由所述文档中所有文档词的词嵌入矩阵组成。·表示检索词和文档词之间的交互操作符,其作用是求向量的点积。具体实施时,通过损失函数l(θ)对神经网络的参数进行优化,其中,θ表示神经网络中任意一种需要优化的参数,q表示检索词的集合,d+来自正样本文档集d+,d+表示与检索词正相关的文档词集,d-来自负样本文档集d-,d-表示与检索词无关和/或负相关的文档词集。θ表示神经网络中任意一种需要优化的参数,例如wk或bk。正样本和负样本文档集是通过官方下载的标准文档库,他们是用人工标注的正负样例,规整为文档集。本发明中,扩大了正样本和负样本之间的差距,使得正分数大于负分大于1,通过反向传播算法优化神经网络。如图2所示,下面为本发明的方法与传统方法的实验比较示例:数据集millionquerytrack2007:简称mq2007。数据集是letor4.0的子集,由网络爬虫从域名gov2网站收集,用户点击用作文档排序的基础,包括25m文档和10000个检索词集。mq2007共有58730个文档和1501个检索词集。其中,文档和检索词集中的单词是小写的和索引的,并且使用krovetz词干分析器提取相应的单词。另外,参考inquery中的停用词列表,我们删除了检索词集中的停用词。表1详细列出了数据集的参数。robust04:robust04是一个小型新闻数据集。我们使用robust04-title作为我们的数据集之一。这些主题来自trecrobusttrack2004.这里的robust04-title意味着主题的标题被用作检索词。该集合包含0.5m文档和250个检索词集。词汇量大小为0.6m,文档大小为252m。在下表1中更清楚地描述。表1mq2007robust04检索词集数1501250文档数58730324541基准方法我们的基准包括传统模型,包括bm25,以及一些最近的神经网络模型。一种类型是以表示为中心的深度匹配模型,包括acr-i,dssm,cdssm,另一种以交互为中心的深度匹配模型如下:acr-ii,matchpyramid,drmm。我们选择一些神经深度匹配模型进行比较,我们将在下面介绍这些模型:arc-i:arc-i是一种以表示为中心的模型。arc-i已经在一组nlp任务上进行了测试,包括短语匹配,完形填空和释义识别。dssm:dssm是一个出色的网络搜索模型。原始论文提到训练dssm需要大量数据。在以下实验中,它没有显示出优异的结果。cdssm:dssm是cdssm的改进版本。它主要将dssm中的全连接层改为卷积层,通过这种方式获得更多的结构信息,并且性能得到改善。arc-ii:它是aci-i的改进版本。它已经注意到交互的重要性,并且比arc-i更早地学习了交互信息。arc-i和arc-ii没有开源代码,因此它被重新实现并应用于比较模型。matchpyramid:它是一种广泛使用的模型。matchpyramid有三个版本。我们选择最佳模型进行比较。实验比较中使用的模型是作者提供的原始模型。drmm:drmm是以交互为中心的模型,具有不同类型的直方图映射函数(即,ch,nh和lch)和权重门控函数(即,tv和idf)。我们选择最佳的结果模型进行比较。同样,实验中使用的模型是作者提供的原始模型。在使用中,采用本发明的方法时:词嵌入尺寸:我们使用50维的词嵌入,它由glove模型提前训练。在培训过程中由于数据量较小,我们没有同步训练词嵌入。通过我们的统计,语料库的词汇是193367。k-max池化层大小:k-max池化层选择512个最佳文档词,其他不会输入神经网络。通过我们的研究,数据集中的不同特征和数量会影响此参数大小的设置。多层神经网络规模:多层神经网络的大小设置为[512,512,256,128,64,32,16,1],实验使用softplus的激活函数。模型优化:使用adam优化器进行优化,e为1-5,学习率为0.001,批量大小为100。我们在matchzoo开发上进行了开发,它是一个使用kerastensorflow的开源匹配模型开发平台,包括当今最先进的匹配模型。评估结果:显然,我们提出的方法(即表中的dtmm)比基线有显着改进。mq2007和robust04中的模型的实验结果如表2及表3。表2表3在mq2007数据集上,所有以表示为中心的模型(包括dssm,cdssm,arc-i)和大多数以交互为中心的模型(包括drmm,arc-ii,matchpyramid)都不如bm25。在之前的模型中,只有drmm的性能优于bm25。以表示为中心的模型的性能通常不如以交互为中心的模型的性能。在某种程度上,这说明了ir中相关性强调的三个因素的作用。在mq2007上dtmm对最佳深度学习基准(即drmm)的提升如下ndcg@1为20.6%,p@1为15%,map为8%,这说明了我们的方法在ir任务上的优越性。在robust04数据集上,大多数以交互为中心的模型的性能也明显优于以表示为中心的模型。但是一个例外是,以交互为中心的模型arc-ii具有与cdssm相同的性能,并且不如以表示为中心的模型dssm。这可能与该数据集中特征的不均匀分布有关。当arc-ii截断文本长度时,它会删除文档末尾的重要信息,这会对模型性能产生影响。同样,除drmm模型外,大多数以交互为中心的模型和以表示为中心的模型不能超过bm25性能。在此数据集上,与最佳模型drmm相比,dtmm也实现了最佳效果。dtmm相对于robust04的最佳深度学习基准(即drmm)的改进分别是ndcg@20为7.4%,p@20为13%,map为12.5%。表4显示了dtmm和没有注重文档词权重的dtmm版本(dtmmno)之间的比较。dtmmno表示没有文档单词重要性的模型。在评估ndcg@3,ndcg@5,ndcg@10和map时,完整的dtmm在ndcg@3,ndcg@5,ndcg@10和map指标上分别比dtmmno的性能高8.25%,7.58%,6.39%,2.85%。它表明强调文档中不同单词的重要性是有意义的。表4此外,在本发明进行检索时,可以先使用okapibm25算法初步筛选出符合的文档,然后使用本方法来选出更加精确的文档。上述仅是本发明优选的实施方式,需指出是,对于本领域技术人员在不脱离本技术方案的前提下,还可以作出若干变形和改进,上述变形和改进的技术方案应同样视为落入本发明要求保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1