一种基于面板数据分析的软件故障的预测方法与流程
本发明提供一种基于面板数据分析的软件故障的预测方法,属于软件预测技术领域。
背景技术:
随着软件技术的不断发展,软件版本在不断更新,随之而来的是软件的复杂度在不断的攀升,带来软件开发、维护难度以及故障率的增加,而修复原有的故障时会随时引入新故障。随着复杂网络的不断应用,带来了许多基于复杂网络的度量元,这些度量元可以从一个新的视角衡量软件的复杂度,本领域技术人员主要基于度量元进行软件预测,进而可以预测软件系统中的故障数目。目前所采用的预测技术大多为基于横截面数据建立静态模型来预测故障数目,该静态模型不能准确反映软件在开发过程中各个版本升级的动态变化情况,而且在众多的预测模型中,整体上没有得出与预测故障一致的度量属性,也没有综合分析不同种类的软件度量属性对故障预测造成的影响。如何从众多的软件度量中挖掘出对故障预测造成的影响较大的度量属性并较为准确地预测故障数目成为本技术领域人员的一大研究方向。
技术实现要素:
(一)目的
本发明实施例提供了一种基于面板数据分析的软件故障预测方法,可以解决现有技术模型中的无法获得与预测故障一致的度量属性,无法实现较为准确的预测未知软件版本的故障数目的问题。
(二)技术方案
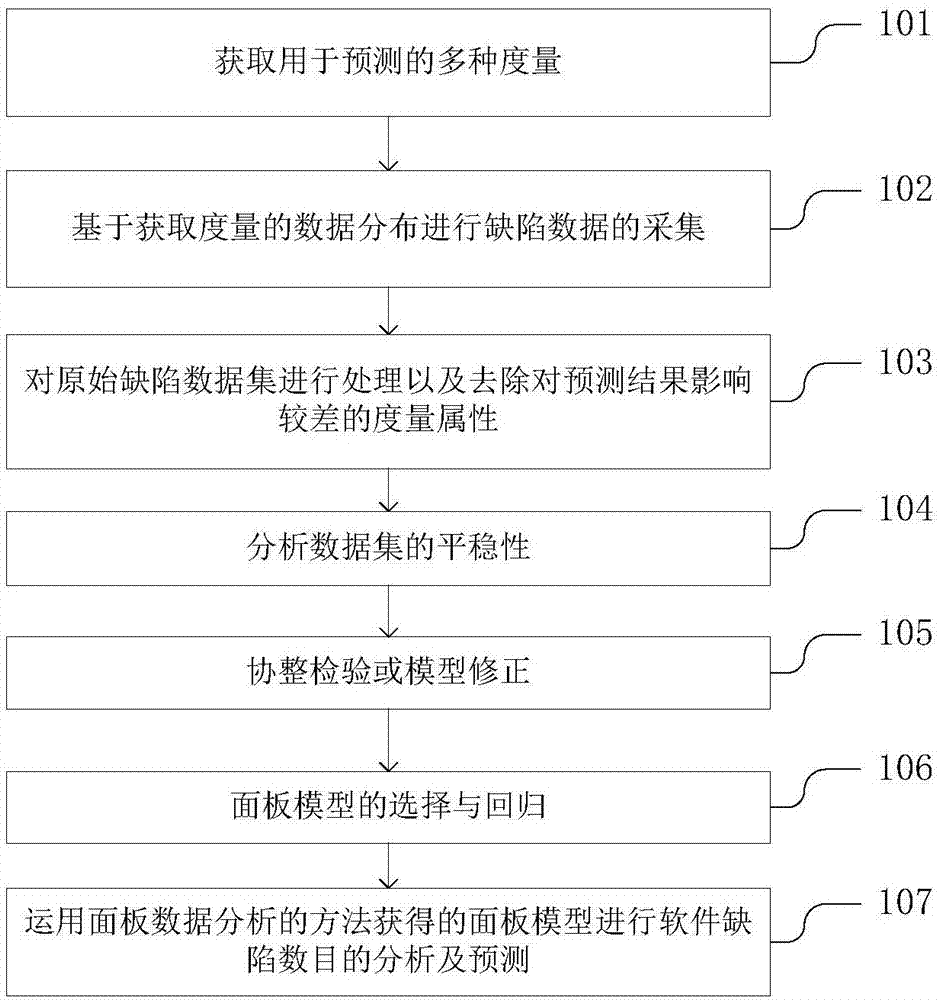
本发明一种基于面板数据分析的软件故障预测方法,如图1所示,其实施步骤如下:
步骤1:获取用于预测的多种度量;
步骤2:基于获取度量的数据分布进行故障数据的采集;
步骤3:对原始故障数据集进行处理以及去除对预测结果影响较差的度量属性;
步骤4:分析数据集的平稳性;
步骤5:协整检验、模型修正;
步骤6:面板模型的选择与回归;
步骤7:运用面板数据分析的方法获得的面板模型进行软件故障数目的分析及预测;
通过以上步骤,实现了通过面板数据分析方法对软件故障数目进行分析和预测;由于面板数据分析基于数据结构的二维性,可以扩大分析的数据量,增加估计和检验统计量的自由度;有助于提供动态分析的可靠性,反映数据的渐进性变化;从而能够获取与预测故障数据趋势一致的数据对应的度量属性;进而较为准确的预测未知版本的故障数目。
其中,在步骤1中所述的“获取用于预测的多种度量”,其具体做法如下:所获取的用于预测的多种度量属于软件的基本属性,可以包含软件的内在特征,也可以包含软件的外在特征,或者两者皆有包含;在本次实施方式中,根据给定的软件,以函数为节点,以调用关系为边,建立函数调用关系网络,基于该复杂网络,获取多个度量元,该度量元可以是静态的拓扑结构指标,也可以是动态指标;本实施中所采用的度量元包括:渗流均值、节点数量、边、平均度、聚集系数、平均路径和社团数量;其中,静态的拓扑结构指标包括节点数量、边、平均度、聚集系数、平均路径和社团数量;动态指标为渗流均值,渗流均值是通过渗流过程中采集多个渗流值并取平均值得到;也即是,在一种通过随机删除网络的节点模拟网络遭遇随机攻击的情景中,渗流值是网络崩溃时的删除节点的比例,记为渗流阈值渗流均值为进行多次随机删除节点进行多次渗流得到的渗流阈值的平均值。
其中,在步骤2中所述的“基于获取度量的数据分布进行故障数据的采集”,其具体做法如下:所述度量的数据分布由本领域技术人员通过对各个版本软件的测试获取得到;进行故障数据的采集的过程,也即是,记录每个版本的软件测试结束后的结果的过程;在本次实施方式中,所测试的软件之一为sqlite,所测软件的版本为:3.16.1、3.16.2、3.17.0、…3.23.1;其中,所采集的度量数据分布包括:渗流均值、节点数量、边、平均度、聚集系数、平均路径和社团数量,所采集的故障数据分别为每一版本的故障数目。
其中,在步骤3中所述的“对原始故障数据集进行处理以及去除对预测结果影响较差的度量属性”,其具体做法如下:对原始故障数据进行处理为去除错误数据,去除对预测结果影响较差的度量属性;可采用先将度量数据进行归一化以消除不同度量之间的影响,选用最小-最大规范化对原始数据进行线性变换;具体展开来说,假定max为度量a数据列的最大值,min为度量a数据列的最小值,最小-最大规范化通过计算属性a的值映射到[a,b]上,转换函数为:
式中,x*表示度量a归一化后的度量值,max为度量a数据列的最大值,min为度量a数据列的最小值;
可采用数据挖掘技术中的最小绝对值压缩与选择的方法选择出适合于故障预测模型构建的数据集;所述方法即为加入一定的约束条件,将影响因子较小的观察变量的回归系数设置为零;
在另一种实施方式中,可通过计算数据集中任何两种度量之间的相关系数,判断度量之间是否存在显著相关;
记新版本的故障数据为yk+1,将各个历史版本的故障数据表示为:y1,y2,y3,....;测试新版本的所述度量的数据集,记为x1,k+1;x2,k+1;x3,k+1......;将各个历史版本测试的所述度量的数据集分别表示为:第一个版本的所述度量:x1,1,x2,1,x3,1...;第二个版本的所述度量:x1,2,x2,2,x3,2...;第k个版本的所述度量:x1,k,x2,k,x3,k,xi,k...。
其中,在步骤4中所述的“分析数据集的平稳性”,其具体做法如下:该步骤是面板数据分析的第一步,在运用面板数据分析的方法进行数据的处理与分析中,面板数据是可以反映动态的数据变化的,可以描述单个度量数据随版本信息更改的变化规律,但区别于时间序列数据模型的是,时间序列中某些度量是不随时间的改变而发生变化,这在时间序列中是观察不到的,而数据面板可以;亦可以描述某个版本状态下故障数据与各个度量数据间的关系,但区别于截面数据反映某个时期的不同度量,面板数据可以综合分析多个版本下的故障数据与度量间的关系,便于整体把握;作为面板数据分析方法中的第一步,其具体做法如下:采用单位根检验的方法,进行相同根单位检测和不同根单位检测,在两种检测方式均拒绝存在单位根的原假设时,判断为所述数据集平稳;若判断数据集为非平稳序列,且序列中存在单位根,可通过差分的方法消除单位根以得到平稳序列。
其中,在步骤5所述的:“协整检验、模型修正”,其具体做法如下:获取两列版本序列数据,并对序列数据进行对数提取,得到新的版本序列,分别对两个新的版本序列数据进行扩充迪克富勒(adf)测验,采用恩格尔-格兰杰(eg)两步法进行协整检验,也即是,第一步,计算非均衡误差,第二部,检验单整性;在本次实施例中,可选用渗流均值与故障数目数据列作为两列版本序列数据。
其中,在步骤6所述的:“面板模型的选择与回归”,其具体做法如下:面板模型的选择包括对混合估计模型、固定效应模型和随机效应模型的选择;在本次实施例中,通过采用豪斯曼(hausman)检验方法,对面板模型进行选择,在一种实施方式中,选择模型为随机效应模型;在所述模型中,yik为被解释变量(本实施例中,该被解释变量只有一个,也即是版本的故障数目,因此i可以是1,此处省略不写)在横截面i和版本k上的数值,xik为解释变量(例如渗流均值)在横截面i和版本k上的数值,此时建立随机效应回归,公式为yik=αi+βi·xik+εik,其中αi表示截距值,βi表示对应于解释变量的系数向量,其中,εik表示随机误差项;用hausman检验该模型是否是随机效应模型;随机效应模型有三种形式:变系数模型、固定影响模型和不变参数模型,根据f检验法,通过比较所测度量与所测软件版本序列的数据的方差,以确定他们之间的精密度是否有显著性差异,以确定模型形式;因横截面个数大于版本序列数,可以采用横截面加权预测法来估计回归方程。
其中,在步骤7所述的:“运用面板数据分析的方法获得的分析模型进行软件故障数目的分析及预测”,其具体做法如下:进行软件故障数目的分析,主要表现为对软件故障数目与度量分布之间关系的分析,进行软件故障数目的预测,主要表现在根据度量与历史软件故障数目之间的线性方程来计算未知版本的故障数目;在本次实施方式中,根据步骤6所述的回归方程,计算得到未知版本的故障数目。
(三)优点与功效
本发明实现了通过面板数据分析方法对软件故障数目进行分析和预测;由于面板数据分析基于数据结构的二维性,可以扩大分析的数据量,增加估计和检验统计量的自由度;有助于提供动态分析的可靠性,反映数据的渐进性变化;从而能够获取与预测故障数据趋势一致的数据对应的度量属性;进而较为准确的预测未知版本的故障数目。该软件故障预测方法简单实用,实施容易,具有推广应用价值。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的方法流程图。
图2是本发明实施例提供的方法示意图。
图3是本发明实施例提供的一种基于面板数据分析的软件预测方法的各个度量的折线图。
具体实施方式
这里将详细的对示例性实施例进行说明,以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式;相反,它们仅是与所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
本发明提供了一种基于面板数据分析的软件故障预测方法,为使本发明的目的、技术方案和优点更加清楚,下面将结合附图1-3对本发明实施方式作详细描述:
本发明一种基于面板数据分析的软件故障预测方法,如图1所示,其实施步骤如下:
101、获取用于预测的多种度量。
其中,获取的用于预测的多种度量是软件的基本属性,可以包含软件的内在特征,可以包含软件的外在特征,或者两者皆有包含。用于预测的多种度量元包括:开发软件的规模、控制流、数据流、代码、开发复杂度、历史故障。在本次实施方式中,度量元包括:渗流均值、节点数量、边、平均度、聚集系数、平均路径和社团数量。所述在进行选取度量时,应关注与软件故障数目的相关性。
102、基于获取度量的数据分布进行故障数据的采集。
其中,所述度量的数据分布是本领域技术人员通过对各个版本软件的测试获取的,进行故障数据的采集的过程,也即是,记录每个版本的软件测试结束后的结果的过程。在本次实施方式中,所测试的软件为sqlite,所测软件的版本为:3.16.1、3.16.2、3.17.0、…3.23.1。在本实施方式中,度量的数目为7,所测软件版本的数目为17。所述各个版本的多个度量元的数据如表1所示。
表1
103、对原始故障数据集进行处理以及去除对预测结果影响较差的度量属性。
其中,对原始故障数据进行处理为去除错误数据,去除对预测结果影响较差的度量属性可采用先将度量数据进行归一化以消除不同度量之间的影响,选用最小-最大规范化对原始数据进行线性变换。具体展开来说,假定max为度量a数据列的最大值,min为度量a数据列的最小值,最小-最大规范化通过计算属性a的值映射到[a,b]上,转换函数为:
表2
然后采用数据挖掘技术中的最小绝对值压缩与选择的方法选择出适合于故障预测模型构建的数据集。所述方法即为加入一定的约束条件,将影响因子较小的观察变量的回归系数设置为零。记新版本的故障数据为fk+1,将各个历史版本的故障数据表示为:f1,f2,f3,....;测试新版本的所述度量的数据集,记为x1,k+1;x2,k+1;x3,k+1......;将各个历史版本测试的所述度量的数据集分别表示为:第一个版本的所述度量:x1,1,x2,1,x3,1...;第二个版本的所述度量:x1,2,x2,2,x3,2...;第k个版本的所述度量:x1,k,x2,k,x3,k,xi,k...。
在一种实施方式中,对原始故障数据集进行处理是指分析数据走势,将明显偏离走势的数据进行剔除,对完全没有偏差的数据进行微型调整。去除对预测结果影响较差的度量属性是每个本技术领域人员正常的工作流程,部分度量属性不会随着版本的升级或者更改发生变化,部分度量属性会随着版本的更改发生剧烈变化,这时就需要对度量属性进行选择,去掉无用或者对预测产生不好影响的度量属性。本实施例里选取与故障数目相关性较高的度量元进行面板数据分析,例如:聚集系数、平均度、平均路径长度和社团数量。在一种可能设计中,可以运用统计工具计算历史版本的故障数据和各个度量值的相关性,对于选出来的强相关性度量值,对相关性系数使用归一化的方式,对各度量值赋予不同的权重。
在另一种实施方式中,还可以采用因子分析对各个度量进行降维处理,也即是,在尽可能损失较少原始信息的前提下,将多个变量综合成少数几个度量来研究总体方面的信息,降维后的度量用于作为面板数据分析的数据基础。
104、分析数据集的平稳性。
其中分析数据集的平稳性时,可采用采用单位根检验的方法,对面板序列绘制时序图,粗略观察时序图中折线是否含有趋势项和截距项,然后进行相同根单位检测和不同根单位检测,在两种检测方式均拒绝存在单位根的原假设时,判断所述数据平稳。该步骤是进行面板数据分析的关键步骤,图2示出了面板数据分析的具体流程示意图。在一种实施方式中,基于时序图得出的结论选择相应的检验模式,采用扩充迪克富勒(adf)检验方法进行检验,面板序列图的折线分布如图3所示。
105、协整检验或模型修正。
其中,所述协整检验基于单位根检验的结果显示两列版本序列数据列为平稳数据列。其具体做法如下:获取两列版本序列数据,并对序列数据进行对数提取,得到新的版本序列,分别对两个新的版本序列数据进行扩充迪克富勒(adf)测验,采用恩格尔-格兰杰(eg)两步法进行协整检验,也即是,第一步,计算非均衡误差,第二部,检验单整性。在本次实施例中,可选用渗流均值与故障数目数据列作为两列版本序列数据进行分析之后再作其他度量与故障数据之间的平稳性分析。
106、面板模型的选择与回归。
面板模型的选择包括对混合估计模型、变截距效应模型和变系数效应模型的选择。用hausman检验该模型是否是随机效应模型。在所述模型中,yik为被解释变量(版本的故障数目)在横截面i和版本k上的数值,xik为解释变量(例如渗流均值)在横截面i和版本k上的数值,此时建立随机效应回归,公式为yik=αi+βi·xik+εik,其中αi表示截距值,βi表示对应于解释变量的系数向量,其中ε项表示随机误差项。其中随机误差项可分解为版本序列随机误差分量、截面随机误差分量和混合随机误差分量,随机效应模型有三种形式:变系数模型、变截距模型和混合模型,其中,变系数模型中,软件故障数目的预测受到度量的影响,此影响不仅体现在回归方程的截距αi上,还表现在对应解释变量的系数βi上;其中,变截距模型中,根据影响因子是常数还是随机变量的不同,分为固定效应模型和随机效应模型。在实施中,可通过hausman检验确定是否采用随机效应模型,也即是,采用卡方分布对各个度量(也即是影响因子)进行检验,若接受影响因子为随机变量的假设则判定为随机效应模型,也即是,截距项中包含了服从正态分布截面随机误差项和时间随机项。根据f检验法,分别计算混合模型的残差平方和s1,变截距模型的残差平方和s2和变系数模型的残差平方和s3,给定显著水平下的f统计量的临界值fα,分别计算三个模型下的统计量f1,f2和f3,分别与显著水平下的临界值fα进行比较,以选择模型形式。若横截面个数大于版本列数,可以采用横截面加权预测法来估计回归方程。在一种实施方式中,可通过选择普通最小二乘法或加权最小二乘法或似不相关回归法直接将面板数据进行整合,估计模型参数。基于spss数据分析工具,分别获得基于面板数据分析的固定效应模型和随机效应模型,基于临界值与统计量的比对以及对显著相关的判别,选用随机效应模型。在随机效应模型中,随机效应方程中的截距项为-2.61,各个系数值分别为-0.57,1.44,-2.11,0.59;随机误差项为7.51,于是随机效应方程的线性表达式为:y=-0.57x1+1.44x2-2.11x3+0.59x4+4.9
107、运用面板数据分析的方法获得的分析模型进行软件故障数目的分析及预测。
其中,进行软件故障数目的分析,主要表现为对软件故障数目与度量分布之间关系的分析,进行软件故障数目的预测,主要表现在根据度量与历史软件故障数目之间的线性方程来计算未知版本的故障数目。在本次实施例中,选取sqlite的从3.61版本开始的十个版本的相关度量元以及故障数据的数据进行分析,将某一版本的归一化后的原始数据代入步骤106中的随机效应回归方程中,可以近似得到对应的故障数据,于是可以基于该方程进行下一版本的故障数据的预测。
- 还没有人留言评论。精彩留言会获得点赞!